diff --git a/README.md b/README.md
index 6e150fa..7a63cc3 100644
--- a/README.md
+++ b/README.md
@@ -24,16 +24,26 @@ llm-arch-research/
│ └── src/llm/
│ ├── core/ # базовые компоненты
│ │ ├── base_model.py
+│ │ ├── cached_decoder.py # Декодер с кэшированием
│ │ ├── decoder.py
│ │ ├── multi_head_attention.py
│ │ ├── head_attention.py
│ │ ├── feed_forward.py
│ │ ├── token_embeddings.py
-│ │ └── positional_embeddings.py
-│ ├── models/gpt/ # GPT и GPT-2 реализация
-│ │ ├── gpt.py
-│ │ ├── gpt2.py
-│ │ └── __init__.py
+│ │ ├── positional_embeddings.py
+│ │ ├── rope.py # Rotary Positional Embeddings
+│ │ ├── rms_norm.py # RMS Normalization
+│ │ ├── swi_glu.py # SwiGLU активация
+│ │ ├── silu.py # SiLU активация
+│ │ └── gelu.py # GELU активация
+│ ├── models/ # Реализации моделей
+│ │ ├── gpt/ # GPT и GPT-2 архитектуры
+│ │ │ ├── gpt.py
+│ │ │ ├── gpt2.py
+│ │ │ └── __init__.py
+│ │ └── llama/ # LLaMA архитектура
+│ │ ├── llama.py
+│ │ └── __init__.py
│ ├── training/ # утилиты обучения
│ │ ├── dataset.py
│ │ ├── trainer.py
diff --git a/experiments/llm_only/train_llama_bpe.py b/experiments/llm_only/train_llama_bpe.py
new file mode 100644
index 0000000..76e8690
--- /dev/null
+++ b/experiments/llm_only/train_llama_bpe.py
@@ -0,0 +1,231 @@
+#!/usr/bin/env python3
+"""
+Experiment: train_gpt_bpe.py
+Description: Обучение GPT модели с собственным BPE токенизатором.
+Использует только библиотеку llm без зависимостей от HuggingFace.
+"""
+
+import torch
+import os
+import sys
+
+# Добавляем путь к shared модулям
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+
+from llm.models.llama import Llama
+from llm.tokenizers import BPETokenizer
+from llm.training.dataset import TextDataset
+from llm.training.trainer import Trainer
+
+from shared.configs import (
+ TRAIN_TEXTS, BASE_GPT_CONFIG, BPE_CONFIG,
+ TRAINING_CONFIG, PATHS, TEST_PROMPTS
+)
+from shared.data import (
+ load_training_data, ensure_directories,
+ print_experiment_info, ExperimentLogger
+)
+
+
+def train_bpe_tokenizer(texts: list, config: dict) -> BPETokenizer:
+ """
+ Обучает BPE токенизатор на текстах.
+
+ Args:
+ texts: Список текстов для обучения
+ config: Конфигурация токенизатора
+
+ Returns:
+ BPETokenizer: Обученный токенизатор
+ """
+ print("🔧 Обучение BPE токенизатора...")
+
+ tokenizer = BPETokenizer()
+ tokenizer.train(
+ texts=texts,
+ vocab_size=config["vocab_size"],
+ special_tokens=config["special_tokens"]
+ )
+
+ # Сохраняем токенизатор
+ os.makedirs(os.path.dirname(PATHS["bpe_tokenizer"]), exist_ok=True)
+ tokenizer.save(PATHS["bpe_tokenizer"])
+
+ print(f"✅ BPE токенизатор обучен и сохранен: {PATHS['bpe_tokenizer']}")
+ print(f"📊 Размер словаря: {tokenizer.get_vocab_size()}")
+
+ return tokenizer
+
+
+def test_tokenizer(tokenizer: BPETokenizer, texts: list):
+ """
+ Тестирует токенизатор на примерах.
+
+ Args:
+ tokenizer: Обученный токенизатор
+ texts: Список тестовых текстов
+ """
+ print("\n🧪 Тестирование токенизатора:")
+
+ for i, text in enumerate(texts[:3]):
+ print(f"\nПример {i+1}:")
+ print(f" Исходный текст: '{text}'")
+
+ # Кодирование
+ tokens = tokenizer.encode(text)
+ token_strings = tokenizer.tokenize(text)
+
+ print(f" Токены (ID): {tokens}")
+ print(f" Токены (текст): {token_strings}")
+ print(f" Количество токенов: {len(tokens)}")
+
+ # Декодирование
+ decoded = tokenizer.decode(tokens)
+ print(f" Декодированный: '{decoded}'")
+
+ if text == decoded:
+ print(" ✅ Кодирование/декодирование корректно")
+ else:
+ print(" ⚠️ Небольшие расхождения")
+
+
+def main():
+ """Основная функция эксперимента."""
+ # === Настройка эксперимента ===
+ experiment_name = "Обучение Llama с BPE токенизатором (только llm)"
+ experiment_config = {
+ "model": "Llama",
+ "tokenizer": "BPE",
+ "vocab_size": BPE_CONFIG["vocab_size"],
+ "training_epochs": TRAINING_CONFIG["num_epochs"],
+ "batch_size": TRAINING_CONFIG["batch_size"],
+ "learning_rate": TRAINING_CONFIG["learning_rate"]
+ }
+
+ print_experiment_info(experiment_name, experiment_config)
+ ensure_directories()
+ logger = ExperimentLogger(experiment_name)
+
+ try:
+ # === Подготовка данных ===
+ train_texts, val_texts = load_training_data()
+ print(f"📊 Данные: {len(train_texts)} train, {len(val_texts)} validation")
+
+ # === Обучение токенизатора ===
+ if os.path.exists(PATHS["bpe_tokenizer"]):
+ print("📝 Загрузка предварительно обученного токенизатора...")
+ tokenizer = BPETokenizer.load(PATHS["bpe_tokenizer"])
+ print(f"✅ Токенизатор загружен (vocab_size={tokenizer.get_vocab_size()})")
+ else:
+ tokenizer = train_bpe_tokenizer(TRAIN_TEXTS, BPE_CONFIG)
+
+ # Тестируем токенизатор
+ test_tokenizer(tokenizer, TEST_PROMPTS[:3])
+
+ # === Инициализация модели ===
+ model_config = BASE_GPT_CONFIG.copy()
+ model_config["vocab_size"] = tokenizer.get_vocab_size()
+
+ print(f"\n🔧 Инициализация Llama модели...")
+ print(f" Размер словаря: {model_config['vocab_size']}")
+ print(f" Размер эмбеддингов: {model_config['embed_dim']}")
+ print(f" Количество слоев: {model_config['num_layers']}")
+ print(f" Количество голов внимания: {model_config['num_heads']}")
+
+ model = Llama(model_config)
+
+ # === Подготовка датасета ===
+ print(f"\n📊 Подготовка датасета...")
+ train_dataset = TextDataset(
+ train_texts,
+ tokenizer,
+ block_size=model_config["max_position_embeddings"]
+ )
+ print(f" Размер train датасета: {len(train_dataset)} примеров")
+
+ # === Обучение модели ===
+ print(f"\n🎯 Начало обучения Llama модели...")
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=train_dataset,
+ lr=TRAINING_CONFIG["learning_rate"],
+ batch_size=TRAINING_CONFIG["batch_size"],
+ num_epochs=TRAINING_CONFIG["num_epochs"],
+ warmup_steps=TRAINING_CONFIG["warmup_steps"]
+ )
+
+ # Запускаем обучение
+ trainer.train()
+
+ # === Сохранение модели ===
+ print(f"\n💾 Сохранение модели...")
+ os.makedirs(os.path.dirname(PATHS["gpt_bpe_model"]), exist_ok=True)
+
+ # Сохраняем модель
+ torch.save(model.state_dict(), PATHS["gpt_bpe_model"])
+
+ # Сохраняем конфигурацию
+ import json
+ with open(PATHS["gpt_bpe_config"], 'w', encoding='utf-8') as f:
+ json.dump(model_config, f, indent=2, ensure_ascii=False)
+
+ print(f"✅ Модель сохранена:")
+ print(f" - {PATHS['gpt_bpe_model']}: веса модели")
+ print(f" - {PATHS['gpt_bpe_config']}: конфигурация модели")
+ print(f" - {PATHS['bpe_tokenizer']}: токенизатор")
+
+ # === Тестирование генерации ===
+ print(f"\n🧪 Тестирование генерации текста...")
+ model.eval()
+
+ for prompt in TEST_PROMPTS[:3]:
+ print(f"\n🔤 Промпт: '{prompt}'")
+
+ try:
+ # Кодируем промпт
+ input_ids = tokenizer.encode(prompt, add_special_tokens=False)
+ input_tensor = torch.tensor([input_ids], dtype=torch.long)
+
+ # Генерируем текст
+ with torch.no_grad():
+ generated_ids = model.generate(
+ x=input_tensor,
+ max_new_tokens=20,
+ do_sample=True,
+ temperature=0.8
+ )
+
+ # Декодируем результат
+ generated_text = tokenizer.decode(generated_ids[0].tolist())
+ generated_part = generated_text[len(prompt):]
+
+ print(f"🎯 Сгенерировано: '{generated_part}'")
+ print(f"📄 Полный текст: '{generated_text}'")
+
+ except Exception as e:
+ print(f"❌ Ошибка генерации: {e}")
+
+ # === Сохранение результатов ===
+ results = {
+ "experiment": experiment_name,
+ "model_config": model_config,
+ "training_config": TRAINING_CONFIG,
+ "tokenizer_vocab_size": tokenizer.get_vocab_size(),
+ "final_loss": "см. логи обучения" # В реальном эксперименте можно сохранить final loss
+ }
+
+ logger.save_logs("checkpoints/llm_only_training_logs.json")
+
+ print(f"\n🎉 Эксперимент завершен успешно!")
+ print(f"\n💡 Для использования обученной модели:")
+ print(f" uv run python experiments/llm_only/generate_gpt_bpe.py")
+
+ except Exception as e:
+ print(f"❌ Ошибка в эксперименте: {e}")
+ import traceback
+ traceback.print_exc()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/llm/README.md b/llm/README.md
index e69de29..ab35c48 100644
--- a/llm/README.md
+++ b/llm/README.md
@@ -0,0 +1,251 @@
+# LLM Framework - Фреймворк для языковых моделей
+
+Модульная библиотека для создания, обучения и использования больших языковых моделей (LLM) с поддержкой различных архитектур (GPT, LLaMA и др.).
+
+## 🏗️ Архитектура
+
+Библиотека построена по модульному принципу с четким разделением ответственности:
+
+```
+llm/
+├── core/ # Базовые компоненты
+│ ├── base_model.py # Абстрактный базовый класс моделей
+│ ├── cached_decoder.py # Универсальный декодер с кэшированием
+│ ├── decoder.py # Базовый декодер
+│ ├── multi_head_attention.py # Многоголовое внимание
+│ ├── head_attention.py # Одно-головое внимание
+│ ├── feed_forward.py # Стандартный FFN слой
+│ ├── token_embeddings.py # Векторные представления токенов
+│ ├── positional_embeddings.py # Абсолютные позиционные эмбеддинги
+│ ├── rope.py # Rotary Positional Embeddings (RoPE)
+│ ├── rms_norm.py # RMS Normalization
+│ ├── swi_glu.py # SwiGLU активация
+│ ├── silu.py # SiLU активация
+│ └── gelu.py # GELU активация
+├── models/ # Конкретные реализации моделей
+│ ├── gpt/ # GPT архитектуры
+│ │ ├── gpt.py # Базовая GPT
+│ │ ├── gpt2.py # GPT-2 реализация
+│ │ └── __init__.py
+│ └── llama/ # LLaMA архитектура
+│ ├── llama.py # LLaMA реализация
+│ └── __init__.py
+├── tokenizers/ # Токенизаторы
+│ ├── base_tokenizer.py # Базовый интерфейс
+│ └── bpe_tokenizer.py # BPE токенизатор
+└── training/ # Утилиты обучения
+ ├── dataset.py # Датасеты
+ ├── trainer.py # Тренировочный цикл
+ ├── optimizer.py # Оптимизаторы
+ └── scheduler.py # Планировщики обучения
+```
+
+## 🧩 Ключевые компоненты
+
+### BaseModel (`core/base_model.py`)
+**Абстрактный базовый класс** для всех языковых моделей с единым интерфейсом.
+
+```python
+class BaseModel(nn.Module, ABC):
+ @abstractmethod
+ def forward(self, input_ids: torch.Tensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """Прямой проход модели."""
+
+ @abstractmethod
+ def generate(self, input_ids: torch.Tensor, max_length: int = 50) -> torch.Tensor:
+ """Генерация текста."""
+```
+
+### CachedDecoder (`core/cached_decoder.py`)
+**Универсальный декодер** с поддержкой dependency injection и кэширования KV-памяти.
+
+```python
+CachedDecoder(
+ feed_forward_layer=FeedForward(...), # или SwiGLU
+ norm_layer=nn.LayerNorm, # или RMSNorm
+ rope=RoPE(...), # опционально
+ # ... другие параметры
+)
+```
+
+### RoPE (`core/rope.py`)
+**Rotary Positional Embeddings** - ротационные позиционные эмбеддинги.
+
+**Математическая основа:**
+```
+θ_i = base^(-2i/d)
+q'_m = q_m * cos(mθ_i) + rotate(q_m) * sin(mθ_i)
+```
+
+### RMSNorm (`core/rms_norm.py`)
+**Root Mean Square Normalization** - упрощенная нормализация без среднего.
+
+**Формула:**
+```
+RMSNorm(x) = (x / RMS(x)) * w
+где RMS(x) = sqrt(mean(x²) + eps)
+```
+
+### SwiGLU (`core/swi_glu.py`)
+**Swish-Gated Linear Unit** - современная активация с gating mechanism.
+
+**Формула:**
+```
+SwiGLU(x) = Swish(xW_g + b_g) ⊙ (xW_u + b_u) * W_d + b_d
+```
+
+## 🚀 Примеры использования
+
+### Создание классической GPT модели
+```python
+from llm.models.gpt import GPT
+
+config = {
+ "vocab_size": 50257,
+ "embed_dim": 768,
+ "num_heads": 12,
+ "num_layers": 12,
+ "max_position_embeddings": 1024,
+ "dropout": 0.1
+}
+
+model = GPT(config)
+```
+
+### Создание GPT2 модели
+```python
+from llm.models.gpt import GPT2
+
+config = {
+ "vocab_size": 50257,
+ "embed_dim": 768,
+ "num_heads": 12,
+ "num_layers": 12,
+ "max_position_embeddings": 1024,
+ "dropout": 0.1
+}
+
+model = GPT2(config)
+```
+
+### Создание LLaMA модели
+```python
+from llm.models.llama import Llama
+from llm.core.swi_glu import SwiGLU
+from llm.core.rms_norm import RMSNorm
+
+config = {
+ "vocab_size": 32000,
+ "embed_dim": 4096,
+ "num_heads": 32,
+ "num_layers": 32,
+ "max_position_embeddings": 2048,
+ "dropout": 0.1
+}
+
+model = Llama(config)
+```
+
+### Генерация текста
+```python
+# Прямой проход
+output = model(input_ids, attention_mask)
+
+# Генерация текста
+generated = model.generate(input_ids, max_length=100)
+```
+
+## 📊 Входные и выходные данные
+
+### Входные данные:
+- `input_ids`: `Tensor[int64]` формы `[batch_size, seq_len]` - индексы токенов
+- `attention_mask`: `Tensor[bool]` формы `[batch_size, seq_len]` - маска внимания
+- `cache`: `List[Tuple[Tensor, Tensor]]` - кэш ключей-значений для генерации
+
+### Выходные данные:
+- `logits`: `Tensor[float32]` формы `[batch_size, seq_len, vocab_size]` - вероятности токенов
+- `cache`: `List[Tuple[Tensor, Tensor]]` - обновленный кэш (при использовании)
+
+## 🏆 Поддерживаемые архитектуры
+
+### GPT (Original) Особенности
+- ✅ Многоголовое внимание
+- ✅ Layer Normalization (после внимания и FFN)
+- ✅ GELU активация
+- ✅ Learned positional embeddings
+- ✅ Базовая архитектура трансформер-декодера
+
+### GPT-2 Особенности
+- ✅ Улучшенная версия оригинальной GPT
+- ✅ Layer Normalization (перед вниманием и FFN)
+- ✅ GELU активация
+- ✅ Learned positional embeddings
+- ✅ Кэширование для эффективной генерации
+- ✅ Оптимизированные веса инициализации
+
+### LLaMA Особенности
+- ✅ Rotary Positional Embeddings (RoPE)
+- ✅ RMS Normalization вместо LayerNorm
+- ✅ SwiGLU активация вместо GELU
+- ✅ Оптимизированная структура декодера
+- ✅ Эффективное кэширование KV-памяти
+
+## 🧪 Тестирование
+
+Запуск всех тестов:
+```bash
+cd llm
+python -m pytest tests/ -v
+```
+
+**Статус тестов:** ✅ 101 тест пройден
+
+## 📚 Научные концепции
+
+### Трансформерная архитектура
+Основана на механизме **внимания**, позволяющем модели взвешивать важность разных частей входной последовательности.
+
+**Формула внимания:**
+```
+Attention(Q, K, V) = softmax(Q·Kᵀ/√d_k)·V
+```
+
+### RoPE (Rotary Positional Embeddings)
+Инновационный метод кодирования позиционной информации через **вращение векторов** в комплексном пространстве.
+
+**Преимущества:**
+- Относительное позиционное кодирование
+- Лучшая экстраполяция на длинные последовательности
+- Сохранение нормы векторов
+
+### RMSNorm vs LayerNorm
+**RMSNorm** устраняет вычитание среднего, что делает его более стабильным и эффективным при обучении больших моделей.
+
+### SwiGLU vs GELU
+**SwiGLU** с gating mechanism показывает лучшую производительность благодаря способности выборочно передавать информацию.
+
+## 🔧 Настройка и расширение
+
+Библиотека разработана с учетом **расширяемости**. Для добавления новой архитектуры:
+
+1. **Наследоваться** от `BaseModel`
+2. **Реализовать** обязательные методы `forward()` и `generate()`
+3. **Использовать** модульные компоненты из `core/`
+4. **Добавить** конфигурацию модели
+
+### Пример расширения:
+```python
+class NewModel(BaseModel):
+ def __init__(self, config):
+ super().__init__(config)
+ # Использование готовых компонентов
+ self.decoder = CachedDecoder(...)
+
+ def forward(self, input_ids, attention_mask=None):
+ # Реализация прямого прохода
+ pass
+```
+
+## 📄 Лицензия
+
+Проект распространяется под MIT License.
diff --git a/llm/src/llm/core/base_model.py b/llm/src/llm/core/base_model.py
index da362c4..0560b53 100644
--- a/llm/src/llm/core/base_model.py
+++ b/llm/src/llm/core/base_model.py
@@ -1,20 +1,72 @@
-# llm/core/base_model.py
+"""
+Базовый абстрактный класс для всех больших языковых моделей (LLM).
+
+Научная суть:
+Модели типа LLM строятся по модульному принципу — конкретные GPT, LLaMA и др. должны наследоваться от этого класса и реализовывать базовый набор интерфейсов для совместимости с training loop, генерацией, инференсом и т.д.
+
+Пользовательский уровень:
+Базовый интерфейс минимизирует дублирование кода и позволяет быстро добавлять новые архитектуры.
+
+Использование:
+ class MyModel(BaseModel):
+ ...
+ model = MyModel(config)
+ logits = model.forward(input_ids)
+ tokens = model.generate(input_ids)
+"""
import torch.nn as nn
from abc import ABC, abstractmethod
+from typing import Optional, Tuple
+import torch
class BaseModel(nn.Module, ABC):
- """Базовый класс для всех LLM."""
-
- def __init__(self, config):
+ """
+ Абстрактный класс — стандарт для всех архитектур LLM.
+
+ Научная идея:
+ Реализация унифицированного входа/выхода для поддержки построения и обучения любых современных языковых моделей.
+
+ Args:
+ config (dict): Параметры архитектуры (размерность эмбеддингов, число слоев, heads и т.д.)
+
+ Attributes:
+ config (dict): Конфиг модели
+ """
+ def __init__(self, config: dict):
+ """
+ Инициализация модели.
+
+ Args:
+ config (dict): Настройки архитектуры модели (размеры слоев, типы блоков и т.д.)
+ """
super().__init__()
self.config = config
@abstractmethod
- def forward(self, input_ids, attention_mask=None):
- """Прямой проход модели."""
+ def forward(self, input_ids: torch.Tensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """
+ Прямой проход — получение логитов для входных токенов.
+
+ Args:
+ input_ids (Tensor[int]): Индексы токенов [batch, seq_len]
+ attention_mask (Optional[Tensor[bool]]): Маска разрешенных позиций (если требуется) [batch, seq_len]
+ Returns:
+ logits (Tensor[float]): Логиты словаря [batch, seq_len, vocab_size]
+ """
pass
@abstractmethod
- def generate(self, input_ids, max_length=50):
- """Генерация текста (greedy или sampling)."""
+ def generate(self, input_ids: torch.Tensor, max_length: int = 50) -> torch.Tensor:
+ """
+ Генерация текста (авторегрессивно, greedy или sampling).
+
+ Args:
+ input_ids (Tensor[int]): Начальные токены [batch, start_len]
+ max_length (int): Максимальная длина последовательности
+ Returns:
+ output_tokens (Tensor[int]): Сгенерированная последовательность [batch, generated_len]
+ Пример:
+ >>> logits = model.forward(input_ids)
+ >>> generated = model.generate(input_ids, max_length=128)
+ """
pass
diff --git a/llm/src/llm/core/cached_decoder.py b/llm/src/llm/core/cached_decoder.py
index ceeff3b..dcc5a4e 100644
--- a/llm/src/llm/core/cached_decoder.py
+++ b/llm/src/llm/core/cached_decoder.py
@@ -4,32 +4,77 @@ import torch
from torch import nn
from .feed_forward import FeedForward
from .multi_head_attention import MultiHeadAttention
+from .rope import RoPE
class CachedDecoder(nn.Module):
"""
- Универсальный декодер с поддержкой кэша для autoregressive использования (GPT, LLAMA и пр).
- - Поддерживает использование past_key_values для быстрого генеративного инференса.
+ Универсальный декодерный блок для современных LLM (GPT, LLaMA, др.), поддерживает кэширование key-value для эффективной генерации.
+
+ Научная идея:
+ Автопагрессивная авторегрессия в трансформерах требует быстрого доступа к ранее вычисленным self-attention ключам/значениям — этот класс позволяет прозрачно кэшировать такие состояния для быстрой инференс-генерации.
+
+ Алгоритм:
+ - Input -> LayerNorm -> Многоголовое внимание с кэшем (может быть RoPE)
+ - Суммируем residual
+ - LayerNorm -> FeedForward (любой, например SwiGLU) -> Residual
+ - Возвращается кортеж (output, kvcache)
+
+ Args:
+ feed_forward_layer (nn.Module): FeedForward или SwiGLU слой
+ num_heads (int): Количество голов внимания
+ emb_size (int): Размерность эмбеддингов
+ head_size (int): Размерность головы внимания
+ max_seq_len (int): Максимальная длина
+ norm_layer (тип nn.Module): Normalization слой (LayerNorm или RMSNorm)
+ dropout (float): Dropout
+ rope (RoPE|None): Экземпляр RoPE (для LLaMA)
+
+ Пример (GPT2 style):
+ >>> decoder = CachedDecoder(
+ ... feed_forward_layer=FeedForward(...),
+ ... norm_layer=nn.LayerNorm,
+ ... num_heads=4, emb_size=256, head_size=64, max_seq_len=128)
+ >>> out, cache = decoder(x, use_cache=True)
"""
def __init__(
self,
+ feed_forward_layer: nn.Module,
num_heads: int,
emb_size: int,
head_size: int,
max_seq_len: int,
+ norm_layer: type = nn.LayerNorm,
dropout: float = 0.1,
- activation: str = "gelu",
+ rope: RoPE = None,
):
+ """
+ Инициализация декодера с кэшированием.
+
+ Поведение аналогично блоку TransformerDecoderLayer,
+ но с гибкой возможностью подмены любых подкомпонент (активация, norm, позиции).
+
+ Args:
+ feed_forward_layer: Слой feed-forward (должен быть экземпляром, а не классом)
+ num_heads: Количество голов внимания
+ emb_size: Размерность эмбеддингов
+ head_size: Размерность каждой головы
+ max_seq_len: Максимальная длина последовательности
+ norm_layer: Класс нормализации (по умолчанию LayerNorm)
+ dropout: Вероятность dropout
+ rope: Rotary Positional Embeddings (опционально)
+ """
super().__init__()
self._heads = MultiHeadAttention(
num_heads=num_heads,
emb_size=emb_size,
head_size=head_size,
max_seq_len=max_seq_len,
+ rope=rope,
dropout=dropout,
)
- self._ff = FeedForward(emb_size=emb_size, dropout=dropout, activation=activation)
- self._norm1 = nn.LayerNorm(emb_size)
- self._norm2 = nn.LayerNorm(emb_size)
+ self._ff = feed_forward_layer
+ self._norm1 = norm_layer(emb_size)
+ self._norm2 = norm_layer(emb_size)
def forward(
self,
@@ -39,11 +84,19 @@ class CachedDecoder(nn.Module):
cache: list = None,
):
"""
- x: [batch, seq_len, emb_size]
- mask: (optional)
- use_cache: использовать ли кэширование KV-слоев (инкрементальный генератив, GPT-style)
- cache: список кэшей для голов (или None)
- Возвращает: (output, new_cache) если use_cache=True, иначе (output, None)
+ Прямой проход с поддержкой кэша.
+
+ Args:
+ x (Tensor[float]): [batch, seq_len, emb_size] — скрытые состояния
+ mask (Optional[Tensor]): маска внимания (или causal mask), shape [seq_len, seq_len]
+ use_cache (bool): использовать кэширование KV
+ cache (list): кэш self-attention для быстрого авторегрессива
+ Returns:
+ output (Tensor[float]): выходные состояния [batch, seq_len, emb_size]
+ kv_caches (list): обновленный кэш, если use_cache
+ Пример:
+ >>> out, new_cache = decoder(x, use_cache=True, cache=old_cache)
+ >>> out.shape # [batch, seq_len, emb_size]
"""
norm1_out = self._norm1(x)
# Передаём все cache/use_cache дальше в attention
diff --git a/llm/src/llm/core/decoder.py b/llm/src/llm/core/decoder.py
index da4f01f..40cb9dd 100644
--- a/llm/src/llm/core/decoder.py
+++ b/llm/src/llm/core/decoder.py
@@ -5,41 +5,24 @@ from .multi_head_attention import MultiHeadAttention
class Decoder(nn.Module):
"""
- Декодер трансформера - ключевой компонент архитектуры Transformer.
-
- Предназначен для:
- - Обработки последовательностей с учетом контекста (самовнимание)
- - Постепенного генерирования выходной последовательности
- - Учета масок для предотвращения "заглядывания в будущее"
+ Базовый автогерессивный блок-декодер трансформера (без кэша KV).
- Алгоритм работы:
- 1. Входной тензор (batch_size, seq_len, emb_size)
- 2. Многоголовое внимание с residual connection и LayerNorm
- 3. FeedForward сеть с residual connection и LayerNorm
- 4. Выходной тензор (batch_size, seq_len, emb_size)
-
- Основные характеристики:
- - Поддержка масок внимания
- - Residual connections для стабилизации градиентов
- - Layer Normalization после каждого sub-layer
- - Конфигурируемые параметры внимания
-
- Примеры использования:
-
- 1. Базовый случай:
- >>> decoder = Decoder(num_heads=8, emb_size=512, head_size=64, max_seq_len=1024)
- >>> x = torch.randn(1, 10, 512) # [batch, seq_len, emb_size]
- >>> output = decoder(x)
- >>> print(output.shape)
- torch.Size([1, 10, 512])
-
- 2. С маской внимания:
- >>> mask = torch.tril(torch.ones(10, 10)) # Нижнетреугольная маска
- >>> output = decoder(x, mask)
-
- 3. Инкрементальное декодирование:
- >>> for i in range(10):
- >>> output = decoder(x[:, :i+1, :], mask[:i+1, :i+1])
+ Научная суть:
+ - Осуществляет посимвольное предсказание: каждый токен видит только предыдущие (masked attention)
+ - Состоит из self-attention + feedforward + residual + нормализация
+ - Residual connection и normalization дают стабильность и градиентный “flow” при обучении
+ - Механизм предложен в Vaswani et al., "Attention is All You Need", 2017
+ Args:
+ num_heads (int): количество attention-голов
+ emb_size (int): размер эмбеддинга
+ head_size (int): размер одной attention-головы
+ max_seq_len (int): максимальная длина последовательности
+ dropout (float): вероятность dropout
+ Пример:
+ >>> decoder = Decoder(num_heads=8, emb_size=512, head_size=64, max_seq_len=1024)
+ >>> x = torch.randn(1, 10, 512)
+ >>> out = decoder(x)
+ >>> print(out.shape) # torch.Size([1, 10, 512])
"""
def __init__(self,
num_heads: int,
diff --git a/llm/src/llm/core/feed_forward.py b/llm/src/llm/core/feed_forward.py
index e1d7576..3168dea 100644
--- a/llm/src/llm/core/feed_forward.py
+++ b/llm/src/llm/core/feed_forward.py
@@ -1,25 +1,26 @@
from torch import nn
import torch
import math
+from .gelu import GELU
-class GELU(nn.Module):
- def __init__(self):
- super().__init__()
- self.sqrt_2_over_pi = torch.sqrt(torch.tensor(2.0) / math.pi)
-
- def forward(self, x: torch.Tensor) -> torch.Tensor:
- return 0.5 * x * (1 + torch.tanh(
- self.sqrt_2_over_pi * (x + 0.044715 * torch.pow(x, 3))
- ))
class FeedForward(nn.Module):
"""
- Слой прямой связи (Feed Forward Network) для архитектуры трансформеров.
-
+ Классический слой прямого распространения (FeedForward, или FFN) для архитектуры Transformer.
+
Этот слой состоит из двух линейных преобразований с расширением внутренней размерности
в 4 раза и механизмом dropout для регуляризации. Между линейными слоями применяется
активация ReLU.
+ Научная суть:
+ - После внимания каждому токену применяется одинаковая двухслойная нейросеть.
+ - Дает глубокую нелинейность; позволяет модели не только сопоставлять, но и моделировать сложные связи между токенами.
+ - Изначально предложен в «Attention is All You Need» (Vaswani et al., 2017).
+
+ Формула:
+ FFN(x) = Dropout(W2·act(W1·x))
+ где act — ReLU, GELU и др., обычно expansion x4.
+
Алгоритм работы:
1. Входной тензор x (размерность: [batch_size, seq_len, emb_size])
2. Линейное преобразование: emb_size -> 4*emb_size
@@ -32,21 +33,17 @@ class FeedForward(nn.Module):
- Добавляет нелинейность в архитектуру трансформера
- Обеспечивает взаимодействие между различными размерностями эмбеддингов
- Работает независимо для каждого токена в последовательности
-
- Примеры использования:
- >>> # Инициализация слоя
- >>> ff = FeedForward(emb_size=512, dropout=0.1)
- >>>
- >>> # Прямой проход
- >>> x = torch.randn(32, 10, 512) # [batch_size, seq_len, emb_size]
- >>> output = ff(x)
- >>> print(output.shape) # torch.Size([32, 10, 512])
- >>>
- >>> # Работа с разными типами данных
- >>> x_double = torch.randn(32, 10, 512, dtype=torch.float64)
- >>> output_double = ff(x_double)
- >>> print(output_double.dtype) # torch.float64
+ Args:
+ emb_size (int): размерность входных эмбеддингов
+ dropout (float): вероятность(dropout)
+ activation (str): нелинейная функция (relu, gelu, gelu_exact)
+
+ Пример:
+ >>> ff = FeedForward(emb_size=512, dropout=0.1)
+ >>> x = torch.randn(32, 10, 512)
+ >>> output = ff(x)
+ >>> print(output.shape) # torch.Size([32, 10, 512])
"""
def __init__(self, emb_size: int, dropout: float = 0.1, activation: str = "relu"):
"""
diff --git a/llm/src/llm/core/gelu.py b/llm/src/llm/core/gelu.py
new file mode 100644
index 0000000..95772f6
--- /dev/null
+++ b/llm/src/llm/core/gelu.py
@@ -0,0 +1,27 @@
+import torch
+from torch import nn
+
+class GELU(nn.Module):
+ """
+ Гауссовская Эрф-активация (GELU, Gaussian Error Linear Unit).
+
+ Научная суть:
+ - Одна из самых популярных smooth активаций для трансформеров.
+ - Дает более гибкие аппроксимации, чем ReLU/SiLU, улучшает flow градиентов для больших LLM.
+ - Используется в BERT, GPT, GPT2 и почти всех современных NLP-моделях.
+ Формула:
+ GELU(x) = 0.5 * x * (1 + tanh(\sqrt{2/π} * (x + 0.044715 x³)))
+ Подробнее: Hendrycks & Gimpel, "Gaussian Error Linear Units (GELUs)", arXiv:1606.08415
+ Пример:
+ >>> gelu = GELU()
+ >>> y = gelu(torch.tensor([-1.0, 0.0, 1.0]))
+ >>> print(y)
+ """
+ def __init__(self):
+ super().__init__()
+ self.sqrt_2_over_pi = torch.sqrt(torch.tensor(2.0) / math.pi)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ return 0.5 * x * (1 + torch.tanh(
+ self.sqrt_2_over_pi * (x + 0.044715 * torch.pow(x, 3))
+ ))
\ No newline at end of file
diff --git a/llm/src/llm/core/head_attention.py b/llm/src/llm/core/head_attention.py
index 0cc8ccf..4b32032 100644
--- a/llm/src/llm/core/head_attention.py
+++ b/llm/src/llm/core/head_attention.py
@@ -2,39 +2,45 @@ import torch
from torch import nn
import torch.nn.functional as F
from math import sqrt
+from .rope import RoPE
class HeadAttention(nn.Module):
"""
- Реализация одного головного механизма внимания из архитектуры Transformer.
- Выполняет scaled dot-product attention с маскированием будущих позиций (causal attention).
-
- Основной алгоритм:
- 1. Линейные преобразования входных данных в Q (query), K (key), V (value)
- 2. Вычисление scores = Q·K^T / sqrt(d_k)
- 3. Применение causal маски (заполнение -inf будущих позиций)
- 4. Softmax для получения весов внимания
- 5. Умножение весов на значения V
-
- Пример использования:
- >>> attention = HeadAttention(emb_size=64, head_size=32, max_seq_len=128)
- >>> x = torch.randn(1, 10, 64) # [batch_size, seq_len, emb_size]
- >>> output = attention(x) # [1, 10, 32]
-
- Параметры:
- emb_size (int): Размер входного эмбеддинга
- head_size (int): Размерность выхода головы внимания
- max_seq_len (int): Максимальная длина последовательности
-
+ Одноголовый механизм внимания (scaled dot-product attention) — фундаментальный строительный блок всех современных Transformer.
+
+ Научная суть:
+ - Attention учит модель самостоятельно "выбирать" важные связи между словами, независимо от их положения.
+ - Механизм causal mask гарантирует невозможность "заглядывания в будущее" при генерации (авторегрессия).
+
+ Формула:
+ Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) · V
+ (Q — запросы, K — ключи, V — значения; d_k — размерность ключа)
+
+ Поддерживает Rotary Position Encoding (RoPE) для относительного позиционного кодирования.
+
+ Args:
+ emb_size (int): размер входного эмбеддинга
+ head_size (int): размерность attention-головы
+ max_seq_len (int): максимальная длина последовательности
+ rope (RoPE, optional): экземпляр RoPE для позиций
+
Примечания:
- Использует нижнетреугольную маску для предотвращения "заглядывания в будущее"
- Автоматически адаптируется к разным версиям PyTorch
- Поддерживает batch-обработку входных данных
+
+ Пример использования:
+ >>> attention = HeadAttention(emb_size=64, head_size=32, max_seq_len=128)
+ >>> x = torch.randn(1, 10, 64)
+ >>> output, _ = attention(x)
+ >>> print(output.shape) # torch.Size([1, 10, 32])
"""
- def __init__(self, emb_size: int, head_size: int, max_seq_len: int):
+ def __init__(self, emb_size: int, head_size: int, max_seq_len: int, rope: RoPE = None):
super().__init__()
self._emb_size = emb_size
self._head_size = head_size
self._max_seq_len = max_seq_len
+ self._rope = rope
# Линейные преобразования для Q, K, V
self._k = nn.Linear(emb_size, head_size)
@@ -73,6 +79,11 @@ class HeadAttention(nn.Module):
q = self._q(x) # [B, T, hs]
v = self._v(x) # [B, T, hs]
+ if self._rope is not None:
+ # ✅ Применяем RoPE к Q и K (НЕ к V!)
+ q = self._rope(q) # [B, T, hs]
+ k = self._rope(k) # [B, T, hs]
+
if cache is not None:
k_cache, v_cache = cache
k = torch.cat([k_cache, k], dim=1) # [B, cache_len + T, hs]
diff --git a/llm/src/llm/core/multi_head_attention.py b/llm/src/llm/core/multi_head_attention.py
index 3bf5fc8..c788359 100644
--- a/llm/src/llm/core/multi_head_attention.py
+++ b/llm/src/llm/core/multi_head_attention.py
@@ -1,37 +1,38 @@
from torch import nn
import torch
from .head_attention import HeadAttention
+from .rope import RoPE
class MultiHeadAttention(nn.Module):
"""
- Реализация механизма многоголового внимания (Multi-Head Attention) из архитектуры Transformer.
+ Мультиголовый (многоголовый) механизм внимания — ключевой компонент любого Transformer.
- Основные характеристики:
- - Параллельная обработка входных данных несколькими головами внимания
- - Поддержка маскирования (causal mask и пользовательские маски)
- - Финальная проекция с dropout регуляризацией
+ Научная суть:
+ - Модель параллельно агрегирует информацию через несколько подпространств (головы),
+ чтобы видеть разные связи в последовательности (разный контекст, локально/глобально).
+ - Каждый attention блок работает независимо, выход конкатенируется.
+ - Механизм предложен в статье "Attention is All You Need" (Vaswani et al., 2017).
+
+ Формула внимания для одной головы:
+ Attention(Q, K, V) = softmax(QK^T/sqrt(d_k))·V
+ Мультиголовый:
+ MultiHead(Q, K, V) = Concat([head_i])*W^O
- Математическое описание:
- MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O
- где head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
+ Args:
+ num_heads (int): количество attention "голов"
+ emb_size (int): размерности входа и выхода
+ head_size (int): размер одной attention-головы (emb_size/num_heads)
+ max_seq_len (int): максимальная длина последовательности
+ rope (RoPE, optional): если задан, используется Rotary Positional Encoding
+ dropout (float): вероятность регуляризации
- Примеры использования:
-
- 1. Базовый пример:
- >>> mha = MultiHeadAttention(num_heads=8, emb_size=512, head_size=64, max_seq_len=1024)
- >>> x = torch.randn(2, 50, 512) # [batch_size, seq_len, emb_size]
- >>> output = mha(x) # [2, 50, 512]
-
- 2. С использованием маски:
- >>> mask = torch.tril(torch.ones(50, 50)) # Causal mask
- >>> output = mha(x, mask)
-
- 3. Интеграция в Transformer:
- >>> # В составе Transformer слоя
- >>> self.attention = MultiHeadAttention(...)
- >>> x = self.attention(x, mask)
+ Пример использования:
+ >>> mha = MultiHeadAttention(num_heads=8, emb_size=512, head_size=64, max_seq_len=1024)
+ >>> x = torch.randn(2, 50, 512)
+ >>> out, cache = mha(x)
+ >>> print(out.shape)
"""
- def __init__(self, num_heads: int, emb_size: int, head_size: int, max_seq_len: int, dropout: float = 0.1):
+ def __init__(self, num_heads: int, emb_size: int, head_size: int, max_seq_len: int, rope: RoPE = None, dropout: float = 0.1):
"""
Инициализация многоголового внимания.
@@ -52,7 +53,8 @@ class MultiHeadAttention(nn.Module):
HeadAttention(
emb_size=emb_size,
head_size=head_size,
- max_seq_len=max_seq_len
+ max_seq_len=max_seq_len,
+ rope=rope,
) for _ in range(num_heads)
])
self._layer = nn.Linear(head_size * num_heads, emb_size)
@@ -60,7 +62,8 @@ class MultiHeadAttention(nn.Module):
def forward(self, x: torch.Tensor, mask: torch.Tensor = None, use_cache: bool = True, cache: list = None):
"""
- Прямой проход через слой многоголового внимания.
+ Прямой проход (forward):
+ Для каждого токена оценивает "важность" остальных токенов сразу через несколько attention-блоков.
Подробное описание преобразований тензоров:
1. Входной тензор [batch_size, seq_len, emb_size] разделяется на N голов:
@@ -73,13 +76,20 @@ class MultiHeadAttention(nn.Module):
4. Линейная проекция:
- Выход: [batch_size, seq_len, emb_size]
5. Применение dropout
+
+ Args:
+ x (Tensor[float]): [batch, seq_len, emb_size] — вход
+ mask (Optional[Tensor[bool]]): маска позиции [seq_len, seq_len]
+ use_cache (bool): использовать ли key-value кэш (для генерации)
+ cache (list): предыдущие значения KV для ускорения
- Аргументы:
- x (torch.Tensor): Входной тензор формы [batch_size, seq_len, emb_size]
- mask (torch.Tensor, optional): Маска внимания формы [seq_len, seq_len]
+ Returns:
+ out (Tensor[float]): [batch, seq_len, emb_size] — результат MHA
+ kv_caches (list): списки новых KV-кэшей (если используется)
- Возвращает:
- torch.Tensor: Выходной тензор формы [batch_size, seq_len, emb_size]
+ Типичный паттерн:
+ Вход: [batch, seq, emb] → N голов [batch, seq, head_size] →
+ → concat [batch, seq, N*head_size] → проекция → dropout
Пример преобразований для emb_size=512, num_heads=8:
Вход: [4, 100, 512]
@@ -88,6 +98,10 @@ class MultiHeadAttention(nn.Module):
-> Конкатенация: [4, 100, 512]
-> Проекция: [4, 100, 512]
-> Dropout: [4, 100, 512]
+
+ Пример:
+ >>> out, caches = mha(x)
+ >>> out.shape # [batch, seq_len, emb_size]
"""
# 1. Вычисляем attention для каждой головы
attention_results = []
diff --git a/llm/src/llm/core/positional_embeddings.py b/llm/src/llm/core/positional_embeddings.py
index f167c31..fb0e7fb 100644
--- a/llm/src/llm/core/positional_embeddings.py
+++ b/llm/src/llm/core/positional_embeddings.py
@@ -3,19 +3,19 @@ from torch import nn, Tensor
class PositionalEmbeddings(nn.Module):
"""
- Класс для создания позиционных эмбеддингов через nn.Embedding.
-
+ Обучаемые позиционные эмбеддинги (learnable positional embeddings).
+
Позиционные эмбеддинги используются в нейросетях для передачи информации
о позиции элементов в последовательности (например, в Transformer).
- Особенности:
- - Создаёт обучаемые позиционные эмбеддинги фиксированной длины
- - Поддерживает обработку последовательностей переменной длины
- - Автоматически размещает вычисления на том же устройстве, что и параметры
-
+ Научная суть:
+ - Трансформеры не используют рекуррентность, а значит сами по себе не различают порядок слов.
+ - Позиционные эмбеддинги добавляются к токеновым, чтобы сеть понимала, в каком месте последовательности находится каждый токен.
+ - Обычно реализуются как отдельная матрица (nn.Embedding), которая обучается вместе с моделью (это learnable вариант, как в GPT и BERT).
+
Args:
- max_seq_len (int): Максимальная длина последовательности
- emb_size (int): Размерность векторного представления позиций
+ max_seq_len (int): максимальная длина последовательности
+ emb_size (int): размер вектора позиции
Пример использования:
>>> pos_encoder = PositionalEmbeddings(max_seq_len=100, emb_size=256)
diff --git a/llm/src/llm/core/rms_norm.py b/llm/src/llm/core/rms_norm.py
new file mode 100644
index 0000000..47def26
--- /dev/null
+++ b/llm/src/llm/core/rms_norm.py
@@ -0,0 +1,83 @@
+"""
+RMSNorm (Root Mean Square Normalization) - нормализация по среднеквадратичному значению.
+
+Упрощенная версия LayerNorm без вычисления среднего значения. Широко используется
+в современных архитектурах типа LLaMA благодаря лучшей стабильности и производительности.
+
+Научная статья: "Root Mean Square Layer Normalization"
+https://arxiv.org/abs/1910.07467
+
+Формула:
+RMSNorm(x) = (x / RMS(x)) * w
+где RMS(x) = sqrt(mean(x²) + eps)
+
+Преимущества:
+- Меньше вычислений (нет вычитания среднего)
+- Лучшая стабильность при обучении
+- Сохранение масштаба сигнала
+"""
+
+import torch
+from torch import nn
+from typing import Optional
+
+
+class RMSNorm(nn.Module):
+ """
+ RMS Normalization (Root Mean Square Layer Normalization).
+
+ Нормализует входные данные по последнему измерению используя среднеквадратичное
+ значение вместо среднего, как в стандартном LayerNorm.
+
+ Научная суть:
+ - Упрощенный вариант LayerNorm без вычисления среднего, только деление на rms.
+ - Лучшая численная стабильность на больших моделях, меньше вычислений.
+ - Применяется в LLaMA, PaLM и др.
+
+ Формула:
+ RMSNorm(x) = (x / sqrt(mean(x²) + eps)) * w (w — обучаемый вектор)
+
+ Args:
+ dim (int): размер последнего измерения (обычно emb_size)
+ eps (float): для численной устойчивости
+
+ Пример:
+ >>> norm = RMSNorm(emb_size)
+ >>> out = norm(x)
+ """
+
+ def __init__(self, dim: int, eps: float = 1e-6):
+ """
+ Инициализация RMSNorm слоя.
+
+ Args:
+ dim: Размерность нормализуемого измерения
+ eps: Малое значение для численной стабильности (по умолчанию 1e-6)
+ """
+ super().__init__()
+ self._eps = eps
+ self._w = nn.Parameter(torch.ones(dim))
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """
+ Прямой проход через RMSNorm слой.
+
+ Args:
+ x: Входной тензор формы [..., dim]
+
+ Returns:
+ Нормализованный тензор той же формы, что и входной
+
+ Формула:
+ output = w * (x / sqrt(mean(x²) + eps))
+ """
+ # Вычисление RMS (Root Mean Square) по последнему измерению
+ rms = (x.pow(2).mean(-1, keepdim=True) + self._eps) ** 0.5
+
+ # Нормализация и масштабирование
+ norm_x = x / rms
+ return self._w * norm_x
+
+ def extra_repr(self) -> str:
+ """Строковое представление для отладки."""
+ return f'dim={self._w.shape[0]}, eps={self._eps}'
\ No newline at end of file
diff --git a/llm/src/llm/core/rope.py b/llm/src/llm/core/rope.py
new file mode 100644
index 0000000..d07b348
--- /dev/null
+++ b/llm/src/llm/core/rope.py
@@ -0,0 +1,104 @@
+"""
+Rotary Positional Embeddings (RoPE) - ротационные позиционные эмбеддинги.
+
+Реализация ротационного позиционного кодирования, которое кодирует позиционную
+информацию через вращение векторов запросов и ключей в комплексном пространстве.
+
+Научная статья: "RoFormer: Enhanced Transformer with Rotary Position Embedding"
+https://arxiv.org/abs/2104.09864
+
+Математическая основа:
+Для позиции m и измерения i:
+θ_i = base^(-2i/d)
+q'_m = q_m * cos(mθ_i) + rotate(q_m) * sin(mθ_i)
+
+Преимущества:
+- Относительное позиционное кодирование
+- Лучшая экстраполяция на длинные последовательности
+- Сохранение нормы векторов
+"""
+
+import torch
+from torch import nn
+from typing import Optional
+
+
+class RoPE(nn.Module):
+ """
+ Rotary Positional Embeddings (RoPE) для механизма внимания.
+
+ Кодирует позиционную информацию через вращение векторов запросов и ключей
+ в многомерном пространстве с использованием синусов и косинусов.
+
+ Args:
+ head_size: Размерность головы внимания (должен быть четным)
+ max_seq_len: Максимальная длина последовательности
+ base: Базовое значение для вычисления частот (по умолчанию 10000)
+
+ Attributes:
+ cos_matrix: Буферизованная матрица косинусов формы [max_seq_len, head_size//2]
+ sin_matrix: Буферизованная матрица синусов формы [max_seq_len, head_size//2]
+ """
+
+ def __init__(self, head_size: int, max_seq_len: int, base: int = 10_000):
+ """
+ Инициализация RoPE эмбеддингов.
+
+ Args:
+ head_size: Размерность головы внимания (должен быть четным)
+ max_seq_len: Максимальная поддерживаемая длина последовательности
+ base: Базовое значение для вычисления частот (типично 10000)
+
+ Raises:
+ AssertionError: Если head_size не четный
+ """
+ super().__init__()
+ assert head_size % 2 == 0, "head_size должен быть четным"
+
+ # Вычисление частот: θ_i = base^(-2i/d) для i ∈ [0, d/2-1]
+ freqs = 1.0 / (base ** (2 * torch.arange(head_size // 2).float() / head_size))
+
+ # Позиции от 0 до max_seq_len-1
+ positions = torch.arange(max_seq_len).float()
+
+ # Внешнее произведение: m * θ_i для всех позиций и частот
+ freq_matrix = positions.unsqueeze(1) * freqs.unsqueeze(0)
+
+ # Предвычисление матриц косинусов и синусов
+ self.register_buffer('cos_matrix', torch.cos(freq_matrix))
+ self.register_buffer('sin_matrix', torch.sin(freq_matrix))
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """
+ Применение ротационного позиционного кодирования к входному тензору.
+
+ Args:
+ x: Входной тензор формы [batch_size, seq_len, head_size]
+
+ Returns:
+ Тензор с примененным RoPE формы [batch_size, seq_len, head_size]
+
+ Алгоритм:
+ 1. Разделение векторов на четные и нечетные компоненты
+ 2. Применение вращения через синусы и косинусы
+ 3. Объединение компонент обратно
+ """
+ seq_len = x.size(1)
+
+ # Берем нужную часть матриц и приводим к типу x
+ cos = self.cos_matrix[:seq_len].to(x.dtype) # [seq_len, head_size//2]
+ sin = self.sin_matrix[:seq_len].to(x.dtype) # [seq_len, head_size//2]
+
+ # Разделяем на четные и нечетные компоненты
+ x_even = x[:, :, 0::2] # [batch_size, seq_len, head_size//2]
+ x_odd = x[:, :, 1::2] # [batch_size, seq_len, head_size//2]
+
+ # Применяем поворот: q' = q * cos(mθ) + rotate(q) * sin(mθ)
+ x_rotated_even = x_even * cos - x_odd * sin
+ x_rotated_odd = x_even * sin + x_odd * cos
+
+ # Объединяем обратно в исходную размерность
+ x_rotated = torch.stack([x_rotated_even, x_rotated_odd], dim=-1)
+ x_rotated = x_rotated.flatten(-2) # [batch_size, seq_len, head_size]
+
+ return x_rotated
\ No newline at end of file
diff --git a/llm/src/llm/core/silu.py b/llm/src/llm/core/silu.py
new file mode 100644
index 0000000..c23d542
--- /dev/null
+++ b/llm/src/llm/core/silu.py
@@ -0,0 +1,19 @@
+import torch
+from torch import nn
+
+class SiLU(nn.Module):
+ """
+ SiLU (Swish) — современная активационная функция для нейросетей.
+
+ Научная суть:
+ - Формула: $SiLU(x) = x * \sigm(x)$, где $\sigm(x)$ — сигмоида.
+ - Более гладкая альтернатива ReLU, улучшает поток градиентов в глубоких сетях.
+ - Используется во многих «state-of-the-art» архитектурах (SwiGLU, PaLM, LLaMA).
+ - Также известна как Swish (Ramachandran et al, 2017).
+ Пример:
+ >>> act = SiLU()
+ >>> x = torch.tensor([-1.0, 0.0, 1.0])
+ >>> print(act(x))
+ """
+ def forward(self, x: torch.Tensor):
+ return torch.sigmoid(x) * x
\ No newline at end of file
diff --git a/llm/src/llm/core/swi_glu.py b/llm/src/llm/core/swi_glu.py
new file mode 100644
index 0000000..ace972d
--- /dev/null
+++ b/llm/src/llm/core/swi_glu.py
@@ -0,0 +1,101 @@
+"""
+SwiGLU (Swish-Gated Linear Unit) - активационная функция с gating mechanism.
+
+Комбинация Swish активации и Gating Linear Unit. Широко используется в современных
+моделях типа LLaMA и PaLM благодаря улучшенной производительности.
+
+Научная статья: "GLU Variants Improve Transformer"
+https://arxiv.org/abs/2002.05202
+
+Формула:
+SwiGLU(x) = Swish(xW_g + b_g) ⊙ (xW_u + b_u) * W_d + b_d
+
+Преимущества:
+- Лучшая производительность чем у ReLU/GELU
+- Gating mechanism позволяет модели лучше выбирать информацию
+- Хорошо масштабируется для больших моделей
+"""
+
+import torch
+from torch import nn
+from typing import Optional
+from .silu import SiLU
+
+
+class SwiGLU(nn.Module):
+ """
+ SwiGLU (Swish-Gated Linear Unit) — современная нелинейность для архитектур LLM (LLaMA, PaLM).
+
+ Реализация SwiGLU активационной функции.
+
+ Состоит из трех линейных слоев и активации SiLU:
+ 1. Gate слой + SiLU активация
+ 2. Up слой (линейное преобразование)
+ 3. Element-wise multiplication gate и up
+ 4. Down слой (линейная проекция)
+
+ Научная суть:
+ - Сохраняет преимущества GLU (раздельные гейтом и телом) + мощность Swish/SiLU активации.
+ - Дает надежную гладкую активацию, хорошо работает на больших масштабах.
+ - Статья: "GLU Variants Improve Transformer" (Shazeer, 2020).
+
+ Формула:
+ SwiGLU(x) = SiLU(W_g·x) * (W_u·x)
+ где SiLU(x) = x*sigma(x)
+
+ Args:
+ emb_size (int): размер входов/выходов
+ dropout (float): после выходной проекции
+ Пример:
+ >>> ff = SwiGLU(emb_size=512, dropout=0.1)
+ >>> y = ff(torch.randn(2,10,512))
+ """
+
+ def __init__(self, emb_size: int, dropout: float = 0.1):
+ """
+ Инициализация SwiGLU слоя.
+
+ Args:
+ emb_size: Размерность входных/выходных эмбеддингов
+ dropout: Вероятность dropout (по умолчанию 0.1)
+ """
+ super().__init__()
+ self._gate = nn.Linear(emb_size, 4 * emb_size)
+ self._up = nn.Linear(emb_size, 4 * emb_size)
+ self._down = nn.Linear(4 * emb_size, emb_size)
+ self._activation = SiLU()
+ self._dropout = nn.Dropout(dropout)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """
+ Прямой проход через SwiGLU слой.
+
+ Args:
+ x: Входной тензор формы [batch_size, seq_len, emb_size]
+
+ Returns:
+ Выходной тензор формы [batch_size, seq_len, emb_size]
+
+ Алгоритм:
+ 1. gate = SiLU(linear_gate(x))
+ 2. up = linear_up(x)
+ 3. output = linear_down(gate ⊙ up)
+ 4. apply dropout
+ """
+ # Gate ветвь: линейное преобразование + активация
+ gate_out = self._gate(x) # [batch, seq, 4*emb]
+ activation_out = self._activation(gate_out) # [batch, seq, 4*emb]
+
+ # Up ветвь: линейное преобразование
+ up_out = self._up(x) # [batch, seq, 4*emb]
+
+ # Element-wise multiplication (gating mechanism)
+ out = up_out * activation_out # поэлементное умножение!
+
+ # Final projection and dropout
+ out = self._down(out) # [batch, seq, emb]
+ return self._dropout(out)
+
+ def extra_repr(self) -> str:
+ """Строковое представление для отладки."""
+ return f'emb_size={self._gate.in_features}, dropout={self._dropout.p}'
\ No newline at end of file
diff --git a/llm/src/llm/core/token_embeddings.py b/llm/src/llm/core/token_embeddings.py
index e6e2737..5674e6f 100644
--- a/llm/src/llm/core/token_embeddings.py
+++ b/llm/src/llm/core/token_embeddings.py
@@ -4,29 +4,30 @@ from torch import Tensor
class TokenEmbeddings(nn.Module):
"""
- Модуль PyTorch для преобразования индексов токенов в векторные представления (эмбеддинги).
-
+ Токеновые эмбеддинги — обучаемые векторные представления для каждого токена словаря.
+
Преобразует целочисленные индексы токенов в обучаемые векторные представления фиксированного размера.
Обычно используется как первый слой в нейронных сетях для задач NLP.
- Аргументы:
- vocab_size (int): Размер словаря (количество уникальных токенов)
- emb_size (int): Размерность векторных представлений
-
- Форматы данных:
- - Вход: тензор (batch_size, seq_len) индексов токенов
- - Выход: тензор (batch_size, seq_len, emb_size) векторных представлений
-
- Примеры использования:
- >>> embedding_layer = TokenEmbeddings(vocab_size=10000, emb_size=256)
- >>> tokens = torch.tensor([[1, 2, 3], [4, 5, 6]]) # batch_size=2, seq_len=3
- >>> embeddings = embedding_layer(tokens)
- >>> embeddings.shape
- torch.Size([2, 3, 256])
-
+ Научная суть:
+ - Первый шаг для любого NLP-модуля: вместо индекса токена подаём его dense-вектор.
+ - Эти вектора изучаются в процессе обучения и отражают скрытые взаимосвязи между токенами.
+ - Позволяют обрабатывать тексты как матрицу чисел, а не как символы или индексы.
+ - Аналог словарных эмбеддингов в word2vec, но обучаются энд-ту-энд с моделью.
+
+ Args:
+ vocab_size (int): размер словаря (количество уникальных токенов)
+ emb_size (int): размерность эмбеддинга (длина вектора)
+
Примечание:
- Индексы должны быть в диапазоне [0, vocab_size-1]
- Эмбеддинги инициализируются случайно и обучаются в процессе тренировки модели
+
+ Пример:
+ >>> emb = TokenEmbeddings(vocab_size=10000, emb_size=256)
+ >>> tokens = torch.tensor([[1, 2, 3]])
+ >>> vecs = emb(tokens)
+ >>> vecs.shape # torch.Size([1, 3, 256])
"""
def __init__(self, vocab_size: int, emb_size: int):
super().__init__()
diff --git a/llm/src/llm/models/gpt/gpt.py b/llm/src/llm/models/gpt/gpt.py
index c184a27..2121da8 100644
--- a/llm/src/llm/models/gpt/gpt.py
+++ b/llm/src/llm/models/gpt/gpt.py
@@ -1,24 +1,58 @@
-# llm/models/gpt/gpt2.py
+"""
+Классическая GPT (Generative Pre-trained Transformer), OpenAI 2018.
+
+Научная суть:
+ - Первая массовая архитектура языка на основе исключительно self-attention механизмов (трансформер-декодер).
+ - Обучается сначала на задаче языкового моделирования (unsupervised), далее дообучается на downstream-задачах (transfer learning).
+ - Обеспечивает длинную память и “глобальный” контекст благодаря attention.
+
+ Ключевые элементы:
+ - masked self-attention (causal)
+ - LayerNorm ПОСЛЕ attention и FFN (что отличает от GPT2)
+ - GELU активация
+ - Absolute learned positional embeddings
+
+ Подробнее: Radford et al., "Improving Language Understanding by Generative Pre-Training", arXiv:1801.10198
+ https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
+
+ Пример использования:
+ >>> model = GPT({"vocab_size": 50257, ...})
+ >>> logits = model(input_ids)
+ >>> out = model.generate(input_ids, max_length=30)
+ """
+
import torch
import torch.nn as nn
import torch.nn.functional as F
+from typing import Optional, Dict
from llm.core.base_model import BaseModel
from llm.core.decoder import Decoder
from llm.core.token_embeddings import TokenEmbeddings
from llm.core.positional_embeddings import PositionalEmbeddings
+
class GPT(BaseModel):
- """GPT-like трансформер для генерации текста
+ """
+ Original GPT (Generative Pre-trained Transformer) модель.
+
+ Первая версия трансформерной архитектуры от OpenAI, предназначенная
+ для генеративного предобучения на текстовых данных.
Args:
- vocab_size: Размер словаря
- max_seq_len: Макс. длина последовательности
- emb_size: Размерность эмбеддингов
- num_heads: Количество голов внимания
- head_size: Размерность голов внимания
- num_layers: Количество слоёв декодера
- dropout: Вероятность dropout (default=0.1)
- device: Устройство (default='cpu')
+ config: Словарь конфигурации с параметрами:
+ - vocab_size: Размер словаря токенов
+ - embed_dim: Размерность векторных представлений
+ - num_heads: Количество голов внимания
+ - num_layers: Количество декодерных слоев
+ - max_position_embeddings: Максимальная длина последовательности
+ - dropout: Вероятность dropout
+
+ Attributes:
+ _token_embeddings: Слой векторных представлений токенов
+ _position_embeddings: Слой позиционных эмбеддингов
+ _decoders: Список декодерных слоев
+ _norm: Финальный слой нормализации
+ _linear: Выходной линейный слой
"""
def __init__(self, config):
super().__init__(config)
diff --git a/llm/src/llm/models/gpt/gpt2.py b/llm/src/llm/models/gpt/gpt2.py
index e5036a7..54c60a0 100644
--- a/llm/src/llm/models/gpt/gpt2.py
+++ b/llm/src/llm/models/gpt/gpt2.py
@@ -1,3 +1,23 @@
+"""
+GPT-2 — масштабируемый автогерессивный языковой трансформер второго поколения от OpenAI (2019).
+
+Научная суть:
+ - В сравнении с классическим GPT, layer normalization теперь применяется ПЕРЕД attention и FFN.
+ - Позволило сильно увеличить глубину и размер модели (GPT2-модели имеют от 117M до 1.5B параметров).
+ - Используется GELU активация; эффективное кэширование KV attention для генерации.
+
+Формула attention-блока:
+ LN(x) → Attention → рез. связь → LN → FFN → рез. связь
+
+Подробнее:
+ Radford et al. "Language Models are Unsupervised Multitask Learners"
+ https://cdn.openai.com/better-language-models/language-models.pdf
+
+Пример использования:
+ >>> model = GPT2({"vocab_size": 50257, ...})
+ >>> logits = model(input_ids)
+ >>> out = model.generate(input_ids, max_length=30)
+"""
import torch
from torch import nn, Tensor
import torch.nn.functional as F
@@ -5,9 +25,25 @@ from llm.core.base_model import BaseModel
from llm.core.token_embeddings import TokenEmbeddings
from llm.core.positional_embeddings import PositionalEmbeddings
from llm.core.cached_decoder import CachedDecoder
-
+from llm.core.feed_forward import FeedForward
class GPT2(BaseModel):
+ """
+ GPT2 — автогерессивная языковая модель, архитектура Transformer, предложенная OpenAI.
+
+ Научная суть:
+ - Масштабируемый автогерессивный трансформер для предсказания токенов слева направо.
+ - Главное отличие от классической GPT: порядок layer normalization ПЕРЕД attention и FFN.
+ - Используется GELU, efficient KV-cache, несет наследие классической GPT, но делает архитектуру глубже/шире.
+
+ Args:
+ config (dict): параметры архитектуры (vocab_size, embed_dim, num_heads, num_layers, max_position_embeddings, dropout)
+
+ Пример использования:
+ >>> model = GPT2({"vocab_size": 50257, ...})
+ >>> logits = model(input_ids)
+ >>> out = model.generate(input_ids, max_length=20)
+ """
def __init__(self, config):
super().__init__(config)
@@ -27,6 +63,11 @@ class GPT2(BaseModel):
num_heads=config["num_heads"],
emb_size=config["embed_dim"],
head_size=config["embed_dim"] // config["num_heads"],
+ feed_forward_layer=FeedForward(
+ emb_size=config["embed_dim"],
+ dropout=config["dropout"],
+ activation="gelu"
+ ),
max_seq_len=config["max_position_embeddings"],
dropout=config["dropout"]
) for _ in range(config["num_layers"])])
@@ -34,6 +75,20 @@ class GPT2(BaseModel):
self._linear = nn.Linear(config["embed_dim"], config["vocab_size"])
def forward(self, x: torch.Tensor, use_cache: bool = True, cache: list = None) -> tuple:
+ """
+ Прямой проход GPT2:
+ - Все слои работают как autoregressive transformer (masked self-attention).
+ - При use_cache=True возвращает также новый кэш KV attention (ускоряет генерацию).
+ Args:
+ x (Tensor): Входные индексы токенов [batch, seq_len]
+ use_cache (bool): Кэшировать KV attention для ускорения autoregressive генерации
+ cache (list|None): Список KV-кэшей от предыдущих шагов (или None)
+ Returns:
+ logits (Tensor): [batch, seq_len, vocab_size]
+ cache (list): новый кэш если use_cache=True, иначе None
+ Пример:
+ >>> logits, cache = model.forward(x, use_cache=True)
+ """
# Проверка длины последовательности (только при отсутствии кэша)
if cache is None and x.size(1) > self._max_seq_len:
raise ValueError(f"Длина последовательности {x.size(1)} превышает максимальную {self.max_seq_len}")
@@ -92,6 +147,24 @@ class GPT2(BaseModel):
top_p: float = None,
use_cache: bool = True
) -> torch.Tensor:
+ """
+ Генерация текста с использованием autoregressive трансформера (GPT2).
+ Поддерживаются greedy, sampling, top-k/top-p (nucleus sampling) режимы.
+ Args:
+ x (Tensor[int]): начальная последовательность [batch, seq_len]
+ max_new_tokens (int): сколько токенов сгенерировать
+ do_sample (bool): использовать стохастическое сэмплирование вместо жадного выбора
+ temperature (float): коэффициент сглаживания логитов (низкое — более консервативно)
+ top_k (int|None): ограничить выбор top-k наиболее вероятных токенов
+ top_p (float|None): ограничить суммарную вероятность (nucleus sampling)
+ use_cache (bool): ускорять autoregressive инференс
+ Returns:
+ output (Tensor[int]): сгенерированный тензор токенов [batch, seq_len + max_new_tokens]
+ Пример:
+ >>> prompt = tokenizer.encode('Привет', return_tensors="pt")
+ >>> output = model.generate(prompt, max_new_tokens=20, do_sample=True)
+ >>> print(tokenizer.decode(output[0]))
+ """
cache = None
for _ in range(max_new_tokens):
diff --git a/llm/src/llm/models/llama/__init__.py b/llm/src/llm/models/llama/__init__.py
new file mode 100644
index 0000000..7954c93
--- /dev/null
+++ b/llm/src/llm/models/llama/__init__.py
@@ -0,0 +1,3 @@
+from .llama import Llama
+
+__all__ = ["Llama"]
diff --git a/llm/src/llm/models/llama/llama.py b/llm/src/llm/models/llama/llama.py
new file mode 100644
index 0000000..7e63221
--- /dev/null
+++ b/llm/src/llm/models/llama/llama.py
@@ -0,0 +1,233 @@
+import torch
+from torch import nn, Tensor
+import torch.nn.functional as F
+
+from llm.core.base_model import BaseModel
+from llm.core.token_embeddings import TokenEmbeddings
+from llm.core.swi_glu import SwiGLU
+from llm.core.rms_norm import RMSNorm
+from llm.core.rope import RoPE
+from llm.core.cached_decoder import CachedDecoder
+
+
+
+class Llama(BaseModel):
+ """
+ LLaMA (Large Language Model Meta AI) — высокоэффективная масштабируемая языковая модель, разработанная Meta AI Research.
+
+ Ключевые идеи:
+ - Rotary Positional Encoding (RoPE) вместо стандартных позиционных эмбеддингов
+ - RMSNorm (Root Mean Square LayerNorm) вместо LayerNorm
+ - SwiGLU как нелинейность вместо ReLU/GELU (больше экспрессивности)
+ - Глубокая оптимизация inference (большая экономия памяти и FLOPs)
+ Подробнее: https://arxiv.org/abs/2302.13971
+
+ Args:
+ config (dict): параметры архитектуры (vocab_size, embed_dim, num_heads, num_layers, max_position_embeddings, dropout)
+ Пример:
+ >>> model = Llama({...})
+ >>> logits, cache = model(input_ids, use_cache=True)
+ >>> out = model.generate(input_ids, max_new_tokens=20)
+ """
+ def __init__(self,config):
+ super().__init__(config)
+
+ # Инициализация слоев
+ self._max_seq_len = config["max_position_embeddings"]
+ self._token_embeddings = TokenEmbeddings(
+ vocab_size=config["vocab_size"],
+ emb_size=config["embed_dim"]
+ )
+ self._position_embeddings = RoPE(
+ head_size=config["embed_dim"] // config["num_heads"],
+ max_seq_len=config["max_position_embeddings"]
+ )
+
+ self._dropout = nn.Dropout(config["dropout"])
+ self._decoders = nn.ModuleList([CachedDecoder(
+ norm_layer=RMSNorm,
+ num_heads=config["num_heads"],
+ emb_size=config["embed_dim"],
+ head_size=config["embed_dim"] // config["num_heads"],
+ feed_forward_layer=SwiGLU(
+ emb_size=config["embed_dim"],
+ dropout=config["dropout"],
+ ),
+ max_seq_len=config["max_position_embeddings"],
+ rope=self._position_embeddings,
+ dropout=config["dropout"],
+ ) for _ in range(config["num_layers"])])
+ self._norm = RMSNorm(config["embed_dim"])
+ self._linear = nn.Linear(config["embed_dim"], config["vocab_size"])
+
+ def forward(self, x: torch.Tensor, use_cache: bool = True, cache: list = None) -> tuple:
+ """
+ Прямой проход через LLaMA (inference/train): авторегрессионное предсказание токенов.
+
+ Args:
+ x (Tensor[int]): входные токены [batch, seq_len]
+ use_cache (bool): использовать ли кэш (ускоряет генерацию)
+ cache (list|None): ключи и значения attention для autoregressive режима
+ Returns:
+ logits (Tensor): [batch, seq_len, vocab_size]
+ new_cache (list|None): новый кэш attention (если use_cache)
+ Пример:
+ >>> logits, cache = model.forward(x, use_cache=True)
+ """
+ # Проверка длины последовательности (только при отсутствии кэша)
+ if cache is None and x.size(1) > self._max_seq_len:
+ raise ValueError(f"Длина последовательности {x.size(1)} превышает максимальную {self.max_seq_len}")
+
+
+ # Вычисление start_pos из кэша (если кэш передан)
+ #if cache is not None:
+ # # При кэше обрабатываем только один токен (последний)
+ # seq_len = 1
+ # # Вычисляем start_pos из самого нижнего уровня кэша
+ # if cache and cache[0] and cache[0][0]:
+ # key_cache, _ = cache[0][0] # Первый декодер, первая голова
+ # start_pos = key_cache.size(1) # cache_len
+ # else:
+ # start_pos = 0
+ #else:
+ # # Без кэша работаем как раньше
+ # start_pos = 0
+ # seq_len = x.size(1)
+
+ # Эмбеддинги токенов и позиций
+ tok_out = self._token_embeddings(x) # [batch, seq_len, emb_size]
+ #pos_out = self._position_embeddings(x) # [batch, seq_len, emb_size]
+
+ # Комбинирование
+ out = self._dropout(tok_out) # [batch, seq_len, emb_size]
+
+ # Стек декодеров с передачей кэша
+ new_cache = []
+ for i, decoder in enumerate(self._decoders):
+ decoder_cache = cache[i] if cache is not None else None
+ decoder_result = decoder(out, use_cache=use_cache, cache=decoder_cache)
+
+ # Извлекаем результат из кортежа
+ if use_cache:
+ out, decoder_new_cache = decoder_result
+ new_cache.append(decoder_new_cache)
+ else:
+ out = decoder_result[0]
+
+ out = self._norm(out)
+ logits = self._linear(out)
+
+ # Возвращаем результат с учетом use_cache
+ if use_cache:
+ return (logits, new_cache)
+ else:
+ return (logits, None)
+
+ def generate(self,
+ x: torch.Tensor,
+ max_new_tokens: int,
+ do_sample: bool,
+ temperature: float = 1.0,
+ top_k: int = None,
+ top_p: float = None,
+ use_cache: bool = True
+ ) -> torch.Tensor:
+ """
+ Генерация текста c помощью LLaMA (autoregressive Transformer).
+ Поддерживается:
+ - greedy и вероятностное сэмплирование (top-k, top-p, temperature)
+ - кэш attention для ускорения генерации длинных последовательностей
+
+ Args:
+ x (Tensor[int]): начальная последовательность [batch, seq_len]
+ max_new_tokens (int): сколько новых токенов сгенерировать
+ do_sample (bool): использовать стохастику (True) или жадный выбор (False)
+ temperature (float): масштаб для softmax (важно для sampling)
+ top_k (int|None): ограничение на количество кандидатов (top-k sampling)
+ top_p (float|None): nucleus sampling
+ use_cache (bool): ускоряет autoregressive при длинной генерации
+ Returns:
+ output (Tensor[int]): [batch, seq_len + max_new_tokens]
+ Пример:
+ >>> prompt = tokenizer.encode('Meta AI', return_tensors="pt")
+ >>> generated = model.generate(prompt, max_new_tokens=30, do_sample=True)
+ >>> print(tokenizer.decode(generated[0]))
+ """
+ cache = None
+
+ for _ in range(max_new_tokens):
+ if use_cache and cache is not None:
+ # Используем кэш - передаем только последний токен
+ x_input = x[:, -1:] # [batch_size, 1]
+ else:
+ # Первая итерация или кэш отключен - передаем всю последовательность
+ x_input = x
+
+ # Прямой проход с кэшем
+ logits, new_cache = self.forward(x_input, use_cache=use_cache, cache=cache)
+
+ # Обновляем кэш для следующей итерации
+ if use_cache:
+ cache = new_cache
+
+ last_logits = logits[:, -1, :] # [batch_size, vocab_size]
+
+ # Масштабируем логиты температурой
+ if temperature > 0:
+ logits_scaled = last_logits / temperature
+ else:
+ logits_scaled = last_logits
+
+ if do_sample == True and top_k != None:
+ _, topk_indices = torch.topk(logits_scaled, top_k, dim=-1)
+
+ # # Заменим все НЕ top-k логиты на -inf
+ masked_logits = logits_scaled.clone()
+ vocab_size = logits_scaled.size(-1)
+
+ # создаём маску: 1, если токен НЕ в topk_indices
+ mask = torch.ones_like(logits_scaled, dtype=torch.uint8)
+ mask.scatter_(1, topk_indices, 0) # 0 там, где top-k индексы
+ masked_logits[mask.byte()] = float('-inf')
+
+ logits_scaled = masked_logits
+
+ if do_sample == True and top_p != None:
+ # 1. Применим softmax, чтобы получить вероятности:
+ probs = F.softmax(logits_scaled, dim=-1) # [B, vocab_size]
+ # 2. Отсортируем токены по убыванию вероятностей:
+ sorted_probs, sorted_indices = torch.sort(probs, descending=True, dim=-1)
+ # 3. Посчитаем кумулятивную сумму вероятностей:
+ cum_probs = torch.cumsum(sorted_probs, dim=-1) # [B, vocab_size]
+ # 4. Определим маску: оставить токены, пока сумма < top_p
+ sorted_mask = (cum_probs <= top_p).byte() # [B, vocab_size]
+ # Гарантируем, что хотя бы первый токен останется
+ sorted_mask[:, 0] = 1
+ # 5. Преобразуем маску обратно в оригинальный порядок:
+ # Создаём полную маску из 0
+ mask = torch.zeros_like(probs, dtype=torch.uint8)
+ # Устанавливаем 1 в местах нужных токенов
+ mask.scatter_(dim=1, index=sorted_indices, src=sorted_mask)
+ # 6. Зануляем логиты токенов вне топ-p:
+ logits_scaled[~mask] = float('-inf')
+
+ # 4. Применяем Softmax
+ probs = F.softmax(logits_scaled, dim=-1) # [batch_size, vocab_size]
+
+
+ if do_sample == True:
+ # 5. Если do_sample равен True, то отбираем токен случайно с помощью torch.multinomial
+ next_token = torch.multinomial(probs, num_samples=1) # [batch_size, 1]
+ else:
+ # 5. Если do_sample равен False, то выбираем токен с максимальной вероятностью
+ next_token = torch.argmax(probs, dim=-1, keepdim=True) # [batch_size, 1]
+
+ # 6. Добавляем его к последовательности
+ x = torch.cat([x, next_token], dim=1) # [batch_size, seq_len+1]
+ return x
+
+
+
+ @property
+ def max_seq_len(self) -> int:
+ return self._max_seq_len
\ No newline at end of file
diff --git a/notebooks/llama.ipynb b/notebooks/llama.ipynb
new file mode 100644
index 0000000..34e487f
--- /dev/null
+++ b/notebooks/llama.ipynb
@@ -0,0 +1,1629 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "efbc675e",
+ "metadata": {},
+ "source": [
+ "# Llama\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "Llama 1 вышла в феврале 2023 года. Это уже подальше, чем GPT-2. И в ее архитектуре появилось уже больше серьезных изменений:\n",
+ "\n",
+ "- Нормализация RMSNorm (вместе с pre-norm).\n",
+ "- Функция активации SwiGLU.\n",
+ "- Новый способ кодирования позиций — Rotary Positional Embeddings."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2cedc663",
+ "metadata": {},
+ "source": [
+ "# RMSNorm\n",
+ "\n",
+ "\n",
+ "\n",
+ "В Llama используется более быстрая и эффективная нормализация — **RMSNorm (Root Mean Square Normalization)**.\n",
+ "И, также как в GPT-2, используется *pre-norm* нормализация, то есть слои нормализации располагаются **перед блоками внимания и FNN**.\n",
+ "\n",
+ "RMSNorm отличается от обычной нормализации только одним: в нём исключен этап центрирования (вычитание среднего) и используется только масштабирование по RMS.\n",
+ "Это сокращает вычислительные затраты (на 7–64%) без существенной потери качества.\n",
+ "На картинке показана разница в распределении после применения RMSNorm и LayerNorm к исходным данным — RMSNorm не разбросан вокруг нуля.\n",
+ "\n",
+ "
\n",
+ " \n",
+ "
\n",
+ "\n",
+ "## Этапы вычисления RMSNorm\n",
+ "\n",
+ "1. **Вычисление среднеквадратичного значения:**\n",
+ "\n",
+ " $$\\text{RMS}(\\mathbf{x}) = \\sqrt{\\frac{1}{d} \\sum_{j=1}^{d} x_j^2}$$\n",
+ "\n",
+ "2. **Нормализация входящего вектора:**\n",
+ "\n",
+ " $$\\hat{x}_i = \\frac{x_i}{\\text{RMS}(\\mathbf{x})}$$\n",
+ "\n",
+ "3. **Применение масштабирования:**\n",
+ "\n",
+ " $$y_i = w_i \\cdot \\hat{x}_i$$\n",
+ "\n",
+ "---\n",
+ "\n",
+ "**Где:**\n",
+ "\n",
+ "* $x_i$ — *i*-й элемент входящего вектора.\n",
+ "* $w_i$ — *i*-й элемент обучаемого вектора весов.\n",
+ " Использование весов позволяет модели адаптивно регулировать амплитуду признаков.\n",
+ " Без них нормализация была бы слишком «жёсткой» и могла бы ограничить качество модели.\n",
+ "* $d$ — размерность входящего вектора.\n",
+ "* $\\varepsilon$ — малая константа (например, 1e-6), предотвращает деление на ноль.\n",
+ "\n",
+ "---\n",
+ "\n",
+ "Так как на вход подаётся тензор, то в векторной форме RMSNorm вычисляется так:\n",
+ "\n",
+ "$$\n",
+ "RMSNorm(x) = w ⊙ \\frac{x}{\\sqrt{mean(x^2) + ϵ}}\n",
+ "$$\n",
+ "\n",
+ "**Где:**\n",
+ "\n",
+ "* $x$ — входящий тензор размера `batch_size × ...`\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "873704be",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from torch import nn\n",
+ "\n",
+ "class RMSNorm(nn.Module):\n",
+ " def __init__(self, dim: int, eps: float = 1e-6):\n",
+ " super().__init__()\n",
+ " self._eps = eps\n",
+ " self._w = nn.Parameter(torch.ones(dim))\n",
+ " \n",
+ " def forward(self, x: torch.Tensor): # [batch_size × seq_len × emb_size]\n",
+ " rms = (x.pow(2).mean(-1, keepdim=True) + self._eps) ** 0.5\n",
+ " norm_x = x / rms\n",
+ " return self._w * norm_x"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "09dd9625",
+ "metadata": {},
+ "source": [
+ "# SwiGLU\n",
+ "\n",
+ "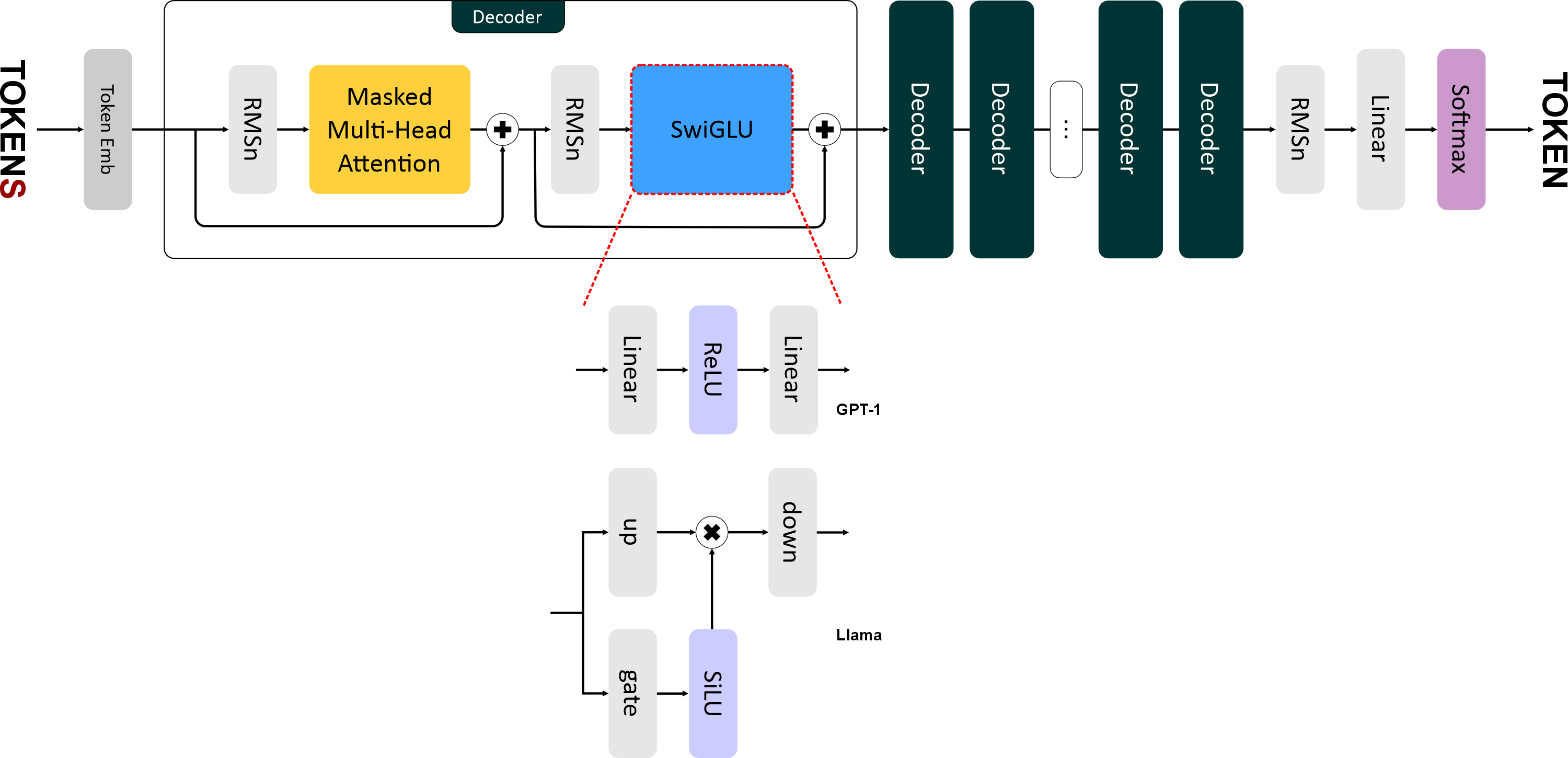\n",
+ "\n",
+ "В **Llama** ввели новую функцию активации — **SwiGLU (Swish-Gated Linear Unit)** — это гибридная функция активации, которая представляет собой комбинацию трёх линейных преобразований и функции активации **SiLU (Sigmoid Linear Unit)**, она же *Swish* в терминологии Google.\n",
+ "\n",
+ "Формула SwiGLU выглядит так:\n",
+ "\n",
+ "$$\n",
+ "\\text{SwiGLU}(x) = \\text{down}(\\text{SiLU}(\\text{gate}(x)) \\otimes \\text{up}(x))\n",
+ "$$\n",
+ "\n",
+ "где:\n",
+ "\n",
+ "* $x$ — входящий тензор.\n",
+ "* $\\text{gate}(x)$ — линейный слой для гейтового механизма. Преобразует вход `x` размерностью `emb_size` в промежуточное представление размерности `4 * emb_size`.\n",
+ "* $\\text{up}(x)$ — линейный слой для увеличения размерности. Также преобразует `x` в размерность `4 * emb_size`.\n",
+ "* $\\text{SiLU}(x) = x \\cdot \\sigma(x)$ — функция активации, где $\\sigma$ — сигмоида.\n",
+ "* $\\otimes$ — поэлементное умножение.\n",
+ "* $\\text{down}(x)$ — линейный слой для уменьшения промежуточного представления до исходного размера (`emb_size`).\n",
+ "\n",
+ "> **Гейтинг** (от слова *gate* — «врата») — это механизм, который позволяет сети динамически фильтровать, какая информация должна проходить дальше.\n",
+ "> При гейтинге создаются как бы два независимых потока:\n",
+ ">\n",
+ "> * один предназначен для прямой передачи информации (*up-down*),\n",
+ "> * другой — для контроля передаваемой информации (*gate*).\n",
+ ">\n",
+ "> Это позволяет сети учить более сложные паттерны.\n",
+ "> Например, гейт может научиться:\n",
+ "> «если признак A активен, то пропусти признак B»,\n",
+ "> что невозможно с простой функцией активации между линейными слоями.\n",
+ ">\n",
+ "> Также гейтинг помогает с затуханием градиентов: вместо простого обнуления (как в ReLU), гейт может тонко модулировать силу сигнала.\n",
+ "\n",
+ "SwiGLU более сложная (дорогая), чем ReLU/GELU, так как требует больше вычислений (три линейных преобразования вместо двух).\n",
+ "Но при этом показывает лучшее качество по сравнению с ReLU и GELU.\n",
+ "\n",
+ "График **SiLU** похож на **GELU**, но более гладкий:\n",
+ "\n",
+ "
\n",
+ " \n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "0484cf77",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from torch import nn\n",
+ "import torch.nn.functional as F\n",
+ "\n",
+ "class SiLU(nn.Module):\n",
+ " def forward(self, x: torch.Tensor): # [batch_size × seq_len × emb_size]\n",
+ " return torch.sigmoid(x) * x"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0b64da5d",
+ "metadata": {},
+ "source": [
+ "## SwiGLU"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "74ca39ba",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from torch import nn\n",
+ "\n",
+ "class SwiGLU(nn.Module):\n",
+ " def __init__(self, emb_size: int, dropout: float = 0.1):\n",
+ " super().__init__()\n",
+ "\n",
+ " self._gate = nn.Linear(emb_size, 4 * emb_size)\n",
+ " self._up = nn.Linear(emb_size, 4 * emb_size)\n",
+ " self._down = nn.Linear(4 * emb_size, emb_size)\n",
+ " self._activation = SiLU()\n",
+ " self._dropout = nn.Dropout(dropout)\n",
+ "\n",
+ " def forward(self, x: torch.Tensor): # [batch_size × seq_len × emb_size].\n",
+ " gate_out = self._gate(x) # [batch, seq, 4*emb]\n",
+ " activation_out = self._activation(gate_out) # [batch, seq, 4*emb]\n",
+ " up_out = self._up(x) # [batch, seq, 4*emb]\n",
+ " out = up_out * activation_out # поэлементное!\n",
+ " out = self._down(out) # [batch, seq, emb]\n",
+ " return self._dropout(out)\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ecd2bcc0",
+ "metadata": {},
+ "source": [
+ "# RoPE\n",
+ "\n",
+ "Вот мы и добрались до наиболее серьезного изменения в архитектуре: обычные позиционные эмбеддинги в **Llama** были заменены на **Rotary Positional Embeddings (RoPE)**.\n",
+ "\n",
+ "**GPT-1** получал информацию о позициях токенов путем сложения эмбеддингов токенов и позиционных эмбеддингов.\n",
+ "**RoPE** же кодирует позиции токенов с помощью *вращения (rotation)* векторов **запроса (query)** и **ключа (key)** в двумерном пространстве. При этом каждая позиция в последовательности получает уникальный поворот, а угол поворота зависит от расположения токена в последовательности.\n",
+ "\n",
+ "Если упрощенно, то выглядит это так:\n",
+ "\n",
+ "* Слово на позиции **1**: поворот на 1°\n",
+ "* Слово на позиции **2**: поворот на 2°\n",
+ "* Слово на позиции **100**: поворот на 100°\n",
+ "* Слово на позиции **101**: поворот на 101°\n",
+ "\n",
+ "Угол между 1 и 101 словом будет достаточно большим — **100°**, что отражает большую дистанцию между ними.\n",
+ "А разница между 100 и 101 словом будет такой же как между 1 и 2, тем самым показывая одинаковую дистанцию между ними.\n",
+ "\n",
+ "Такое относительное кодирование позволяет модели лучше понимать расстояние между токенами.\n",
+ "\n",
+ "
\n",
+ " \n",
+ "
\n",
+ "\n",
+ "В последующем тензоры **запроса (query)** и **ключа (key)** перемножаются для вычисления **матрицы внимания**.\n",
+ "А это означает, что теперь вычисление внимания напрямую зависит от относительных позиций слов.\n",
+ "\n",
+ "---\n",
+ "\n",
+ "## Почему RoPE лучше\n",
+ "\n",
+ "* **Устойчивость к сдвигу:** модель не переобучается на конкретных позициях в обучающих данных, так как учитывает относительные расстояния.\n",
+ "* **Экономия:** интегрируется в ключи (*key*) и запросы (*query*) посредством матричных вычислений, без необходимости создавать и хранить отдельный слой для позиционных эмбеддингов.\n",
+ "* **Экстраполяция:** модель может работать с последовательностями длиннее, чем видела при обучении — потому что она выучивает закономерности поворотов в зависимости от дистанции.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8ba07b89",
+ "metadata": {},
+ "source": [
+ "### Как это работает...\n",
+ "\n",
+ "Основная идея: для каждого токена в последовательности его эмбеддинг поворачивается на угол, зависящий от позиции токена и фиксированных частот.\n",
+ "\n",
+ "На вход к нам поступают либо тензор ключа (key), либо тензор запроса (query) размерностью `head_size`.\n",
+ "Обозначим его как *x*.\n",
+ "\n",
+ "
\n",
+ " \n",
+ "
\n",
+ "\n",
+ "Каждая строка в тензоре — это вектор, соответствующий одному токену в последовательности.\n",
+ "Обозначим вектор как *xₘ*, где *m* — номер позиции токена.\n",
+ "\n",
+ "
\n",
+ " \n",
+ "
\n",
+ "\n",
+ "Вращать вектор мы будем в двумерном пространстве. Но размерность вектора многомерная!\n",
+ "Чтобы свести вращение к двумерному пространству, вектор разбивают на рядом стоящие пары измерений:\n",
+ "\n",
+ "$$\n",
+ "x_m = [x_{m0}, x_{m1}, x_{m2}, x_{m3}, …, x_{m(d−2)}, x_{m(d−1)}] \\Rightarrow \\text{пары: } (x_{m0}, x_{m1}), (x_{m2}, x_{m3}), …, (x_{m(d−2)}, x_{m(d−1)})\n",
+ "$$\n",
+ "\n",
+ "> Из-за того, что вектор обязательно должен быть разбит на пары, RoPE может работать только для четных `head_size`.\n",
+ "\n",
+ "После этого мы можем рассматривать каждую пару\n",
+ "$(x_{m,2k}; x_{m,2k+1})$\n",
+ "как вектор в двумерном пространстве:\n",
+ "\n",
+ "$$\n",
+ "\\begin{bmatrix}\n",
+ "x_{m,2k} \\\n",
+ "x_{m,2k+1}\n",
+ "\\end{bmatrix}\n",
+ "$$\n",
+ "\n",
+ "А раз это вектор в двумерном пространстве, то мы можем повернуть его на угол\n",
+ "$m \\cdot \\theta_k$.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c386a55c",
+ "metadata": {},
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "id": "450e03ac",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "Каждая пара измерений вектора поворачивается на угол:\n",
+ "\n",
+ "$$\n",
+ "m \\cdot \\theta_k\n",
+ "$$\n",
+ "\n",
+ "