mirror of
https://github.com/pese-git/llm-arch-research.git
synced 2026-05-16 10:09:42 +00:00
fix: typo in activation attribute for SwiGLU (rename _actvation to _activation) and minor index update
This commit is contained in:
665
notebooks/llama.ipynb
Normal file
665
notebooks/llama.ipynb
Normal file
@@ -0,0 +1,665 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "efbc675e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Llama\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Llama 1 вышла в феврале 2023 года. Это уже подальше, чем GPT-2. И в ее архитектуре появилось уже больше серьезных изменений:\n",
|
||||
"\n",
|
||||
"- Нормализация RMSNorm (вместе с pre-norm).\n",
|
||||
"- Функция активации SwiGLU.\n",
|
||||
"- Новый способ кодирования позиций — Rotary Positional Embeddings."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2cedc663",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# RMSNorm\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"В Llama используется более быстрая и эффективная нормализация — **RMSNorm (Root Mean Square Normalization)**.\n",
|
||||
"И, также как в GPT-2, используется *pre-norm* нормализация, то есть слои нормализации располагаются **перед блоками внимания и FNN**.\n",
|
||||
"\n",
|
||||
"RMSNorm отличается от обычной нормализации только одним: в нём исключен этап центрирования (вычитание среднего) и используется только масштабирование по RMS.\n",
|
||||
"Это сокращает вычислительные затраты (на 7–64%) без существенной потери качества.\n",
|
||||
"На картинке показана разница в распределении после применения RMSNorm и LayerNorm к исходным данным — RMSNorm не разбросан вокруг нуля.\n",
|
||||
"\n",
|
||||
"<p align=\"center\">\n",
|
||||
" <img src=\"https://ucarecdn.com/cbfbb78e-e2b0-40e2-ba56-73e5114d54f6/\" width=\"350\" alt=\"RMSNorm vs LayerNorm\">\n",
|
||||
"</p>\n",
|
||||
"\n",
|
||||
"## Этапы вычисления RMSNorm\n",
|
||||
"\n",
|
||||
"1. **Вычисление среднеквадратичного значения:**\n",
|
||||
"\n",
|
||||
" $$\\text{RMS}(\\mathbf{x}) = \\sqrt{\\frac{1}{d} \\sum_{j=1}^{d} x_j^2}$$\n",
|
||||
"\n",
|
||||
"2. **Нормализация входящего вектора:**\n",
|
||||
"\n",
|
||||
" $$\\hat{x}_i = \\frac{x_i}{\\text{RMS}(\\mathbf{x})}$$\n",
|
||||
"\n",
|
||||
"3. **Применение масштабирования:**\n",
|
||||
"\n",
|
||||
" $$y_i = w_i \\cdot \\hat{x}_i$$\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"**Где:**\n",
|
||||
"\n",
|
||||
"* $x_i$ — *i*-й элемент входящего вектора.\n",
|
||||
"* $w_i$ — *i*-й элемент обучаемого вектора весов.\n",
|
||||
" Использование весов позволяет модели адаптивно регулировать амплитуду признаков.\n",
|
||||
" Без них нормализация была бы слишком «жёсткой» и могла бы ограничить качество модели.\n",
|
||||
"* $d$ — размерность входящего вектора.\n",
|
||||
"* $\\varepsilon$ — малая константа (например, 1e-6), предотвращает деление на ноль.\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"Так как на вход подаётся тензор, то в векторной форме RMSNorm вычисляется так:\n",
|
||||
"\n",
|
||||
"$$\n",
|
||||
"RMSNorm(x) = w ⊙ \\frac{x}{\\sqrt{mean(x^2) + ϵ}}\n",
|
||||
"$$\n",
|
||||
"\n",
|
||||
"**Где:**\n",
|
||||
"\n",
|
||||
"* $x$ — входящий тензор размера `batch_size × ...`\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "873704be",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"from torch import nn\n",
|
||||
"\n",
|
||||
"class RMSNorm(nn.Module):\n",
|
||||
" def __init__(self, dim: int, eps: float = 1e-6):\n",
|
||||
" super().__init__()\n",
|
||||
" self._eps = eps\n",
|
||||
" self._w = nn.Parameter(torch.ones(dim))\n",
|
||||
" \n",
|
||||
" def forward(self, x: torch.Tensor): # [batch_size × seq_len × emb_size]\n",
|
||||
" rms = (x.pow(2).mean(-1, keepdim=True) + self._eps) ** 0.5\n",
|
||||
" norm_x = x / rms\n",
|
||||
" return self._w * norm_x"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "09dd9625",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# SwiGLU\n",
|
||||
"\n",
|
||||
"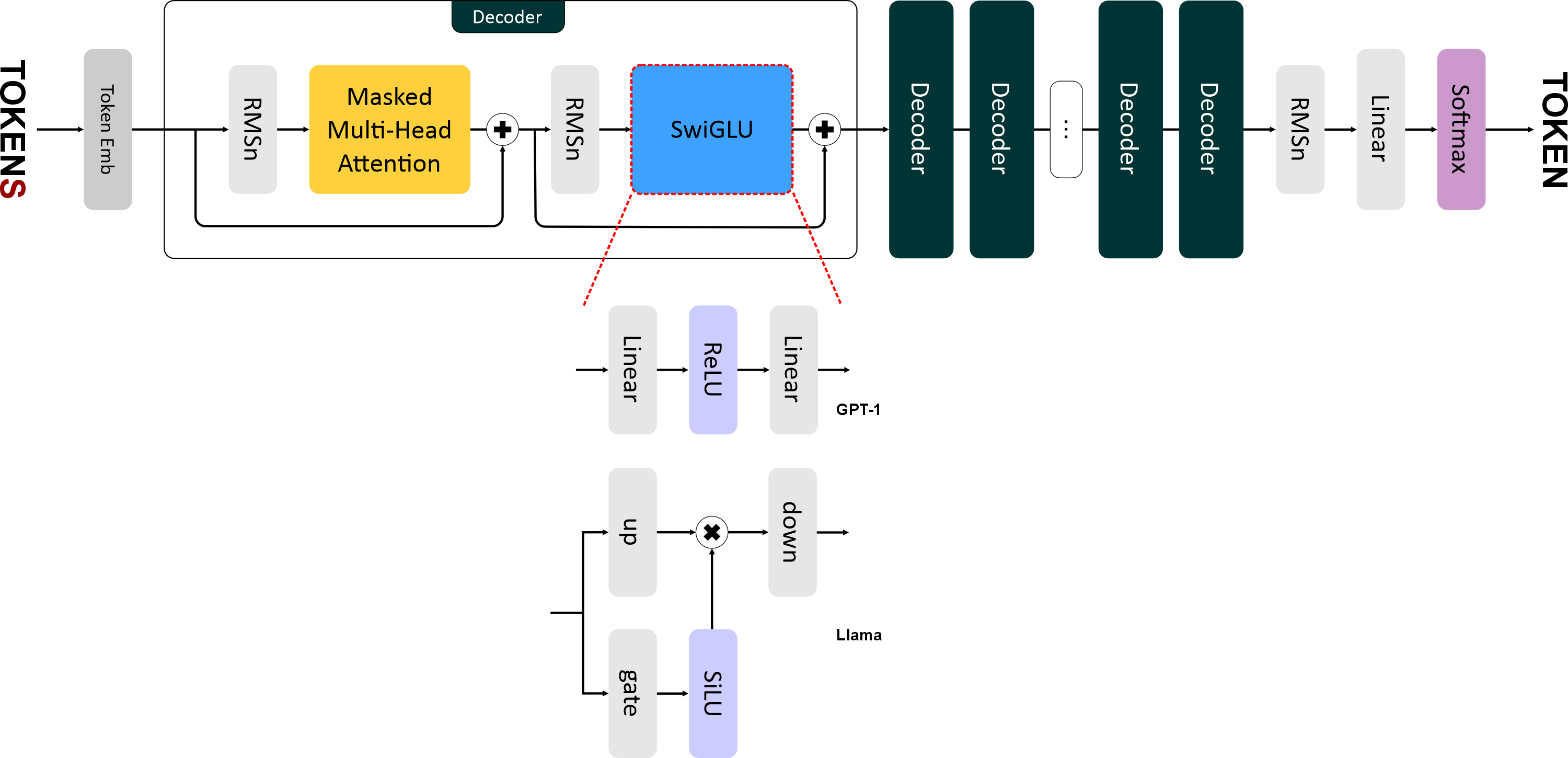\n",
|
||||
"\n",
|
||||
"В **Llama** ввели новую функцию активации — **SwiGLU (Swish-Gated Linear Unit)** — это гибридная функция активации, которая представляет собой комбинацию трёх линейных преобразований и функции активации **SiLU (Sigmoid Linear Unit)**, она же *Swish* в терминологии Google.\n",
|
||||
"\n",
|
||||
"Формула SwiGLU выглядит так:\n",
|
||||
"\n",
|
||||
"$$\n",
|
||||
"\\text{SwiGLU}(x) = \\text{down}(\\text{SiLU}(\\text{gate}(x)) \\otimes \\text{up}(x))\n",
|
||||
"$$\n",
|
||||
"\n",
|
||||
"где:\n",
|
||||
"\n",
|
||||
"* $x$ — входящий тензор.\n",
|
||||
"* $\\text{gate}(x)$ — линейный слой для гейтового механизма. Преобразует вход `x` размерностью `emb_size` в промежуточное представление размерности `4 * emb_size`.\n",
|
||||
"* $\\text{up}(x)$ — линейный слой для увеличения размерности. Также преобразует `x` в размерность `4 * emb_size`.\n",
|
||||
"* $\\text{SiLU}(x) = x \\cdot \\sigma(x)$ — функция активации, где $\\sigma$ — сигмоида.\n",
|
||||
"* $\\otimes$ — поэлементное умножение.\n",
|
||||
"* $\\text{down}(x)$ — линейный слой для уменьшения промежуточного представления до исходного размера (`emb_size`).\n",
|
||||
"\n",
|
||||
"> **Гейтинг** (от слова *gate* — «врата») — это механизм, который позволяет сети динамически фильтровать, какая информация должна проходить дальше.\n",
|
||||
"> При гейтинге создаются как бы два независимых потока:\n",
|
||||
">\n",
|
||||
"> * один предназначен для прямой передачи информации (*up-down*),\n",
|
||||
"> * другой — для контроля передаваемой информации (*gate*).\n",
|
||||
">\n",
|
||||
"> Это позволяет сети учить более сложные паттерны.\n",
|
||||
"> Например, гейт может научиться:\n",
|
||||
"> «если признак A активен, то пропусти признак B»,\n",
|
||||
"> что невозможно с простой функцией активации между линейными слоями.\n",
|
||||
">\n",
|
||||
"> Также гейтинг помогает с затуханием градиентов: вместо простого обнуления (как в ReLU), гейт может тонко модулировать силу сигнала.\n",
|
||||
"\n",
|
||||
"SwiGLU более сложная (дорогая), чем ReLU/GELU, так как требует больше вычислений (три линейных преобразования вместо двух).\n",
|
||||
"Но при этом показывает лучшее качество по сравнению с ReLU и GELU.\n",
|
||||
"\n",
|
||||
"График **SiLU** похож на **GELU**, но более гладкий:\n",
|
||||
"\n",
|
||||
"<p align=\"center\">\n",
|
||||
" <img src=\"https://ucarecdn.com/6683e0c8-96b7-4389-826a-a73708b4a835/\" width=\"500\" alt=\"SiLU vs GELU\">\n",
|
||||
"</p>\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "0484cf77",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"from torch import nn\n",
|
||||
"import torch.nn.functional as F\n",
|
||||
"\n",
|
||||
"class SiLU(nn.Module):\n",
|
||||
" def forward(self, x: torch.Tensor): # [batch_size × seq_len × emb_size]\n",
|
||||
" return torch.sigmoid(x) * x"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0b64da5d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## SwiGLU"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "74ca39ba",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"from torch import nn\n",
|
||||
"\n",
|
||||
"class SwiGLU(nn.Module):\n",
|
||||
" def __init__(self, emb_size: int, dropout: float = 0.1):\n",
|
||||
" super().__init__()\n",
|
||||
"\n",
|
||||
" self._gate = nn.Linear(emb_size, 4 * emb_size)\n",
|
||||
" self._up = nn.Linear(emb_size, 4 * emb_size)\n",
|
||||
" self._down = nn.Linear(4 * emb_size, emb_size)\n",
|
||||
" self._actvation = SiLU()\n",
|
||||
" self._dropout = nn.Dropout(dropout)\n",
|
||||
"\n",
|
||||
" def forward(self, x: torch.Tensor): # [batch_size × seq_len × emb_size].\n",
|
||||
" gate_out = self._gate(x) # [batch, seq, 4*emb]\n",
|
||||
" activation_out = self._activation(gate_out) # [batch, seq, 4*emb]\n",
|
||||
" up_out = self._up(x) # [batch, seq, 4*emb]\n",
|
||||
" out = up_out * activation_out # поэлементное!\n",
|
||||
" out = self._down(out) # [batch, seq, emb]\n",
|
||||
" return self._dropout(out)\n",
|
||||
"\n",
|
||||
" "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c386a55c",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c9fe652d",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "fe1274b1",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"from torch import nn\n",
|
||||
"import torch.nn.functional as F\n",
|
||||
"from math import sqrt\n",
|
||||
"import torch\n",
|
||||
"from torch import nn\n",
|
||||
"from torch import Tensor\n",
|
||||
"\n",
|
||||
"class TokenEmbeddings(nn.Module):\n",
|
||||
" def __init__(self, vocab_size: int, emb_size: int):\n",
|
||||
" super().__init__()\n",
|
||||
" self._embedding = nn.Embedding(\n",
|
||||
" num_embeddings=vocab_size,\n",
|
||||
" embedding_dim=emb_size\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" def forward(self, x: Tensor) -> Tensor:\n",
|
||||
" return self._embedding(x)\n",
|
||||
"\n",
|
||||
" @property\n",
|
||||
" def num_embeddings(self) -> int:\n",
|
||||
" return self._embedding.num_embeddings\n",
|
||||
"\n",
|
||||
" @property\n",
|
||||
" def embedding_dim(self) -> int:\n",
|
||||
" return self._embedding.embedding_dim\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"import torch\n",
|
||||
"from torch import nn, Tensor\n",
|
||||
"\n",
|
||||
"class PositionalEmbeddings(nn.Module):\n",
|
||||
" def __init__(self, max_seq_len: int, emb_size: int):\n",
|
||||
" super().__init__()\n",
|
||||
" self.max_seq_len = max_seq_len\n",
|
||||
" self.emb_size = emb_size\n",
|
||||
" self.embedding = nn.Embedding(\n",
|
||||
" num_embeddings=max_seq_len,\n",
|
||||
" embedding_dim=emb_size\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" def forward(self, seq_len: int, start_pos: int = 0) -> Tensor:\n",
|
||||
" if seq_len < 1 or seq_len > self.max_seq_len:\n",
|
||||
" raise IndexError(f\"Длина {seq_len} должна быть от 1 до {self.max_seq_len}\")\n",
|
||||
" if start_pos == 0:\n",
|
||||
" positions = torch.arange(seq_len, device=self.embedding.weight.device)\n",
|
||||
" else:\n",
|
||||
" positions = torch.arange(start=start_pos, end=start_pos + seq_len, device=self.embedding.weight.device)\n",
|
||||
" return self.embedding(positions)\n",
|
||||
" \n",
|
||||
" \n",
|
||||
"class HeadAttention(nn.Module):\n",
|
||||
"\n",
|
||||
" def __init__(self, emb_size: int, head_size: int, max_seq_len: int):\n",
|
||||
" super().__init__()\n",
|
||||
" self._emb_size = emb_size\n",
|
||||
" self._head_size = head_size\n",
|
||||
" self._max_seq_len = max_seq_len\n",
|
||||
"\n",
|
||||
" self._k = nn.Linear(emb_size, head_size)\n",
|
||||
" self._q = nn.Linear(emb_size, head_size)\n",
|
||||
" self._v = nn.Linear(emb_size, head_size)\n",
|
||||
"\n",
|
||||
" mask = torch.tril(torch.ones(max_seq_len, max_seq_len))\n",
|
||||
" self.register_buffer('_tril_mask', mask.bool() if hasattr(torch, 'bool') else mask.byte())\n",
|
||||
"\n",
|
||||
" def forward(self, x: torch.Tensor, use_cache: bool = True, cache: tuple = None) -> tuple:\n",
|
||||
" seq_len = x.shape[1]\n",
|
||||
" if seq_len > self._max_seq_len:\n",
|
||||
" raise ValueError(f\"Длина последовательности {seq_len} превышает максимум {self._max_seq_len}\")\n",
|
||||
"\n",
|
||||
" k = self._k(x) # [B, T, hs]\n",
|
||||
" q = self._q(x) # [B, T, hs]\n",
|
||||
" v = self._v(x) # [B, T, hs]\n",
|
||||
"\n",
|
||||
" if cache is not None:\n",
|
||||
" k_cache, v_cache = cache\n",
|
||||
" k = torch.cat([k_cache, k], dim=1) # [B, cache_len + T, hs]\n",
|
||||
" v = torch.cat([v_cache, v], dim=1) # [B, cache_len + T, hs]\n",
|
||||
" \n",
|
||||
" scores = q @ k.transpose(-2, -1) / sqrt(self._head_size)\n",
|
||||
" \n",
|
||||
" if cache is None:\n",
|
||||
" scores = scores.masked_fill(~self._tril_mask[:seq_len, :seq_len], float('-inf'))\n",
|
||||
" \n",
|
||||
" weights = F.softmax(scores, dim=-1)\n",
|
||||
" x_out = weights @ v # [B, T, hs]\n",
|
||||
"\n",
|
||||
" if use_cache is True:\n",
|
||||
" return (x_out, (k, v))\n",
|
||||
" else:\n",
|
||||
" return (x_out, None)\n",
|
||||
" \n",
|
||||
"from torch import nn\n",
|
||||
"import torch\n",
|
||||
"import math\n",
|
||||
"\n",
|
||||
"class MultiHeadAttention(nn.Module):\n",
|
||||
" def __init__(self, num_heads: int, emb_size: int, head_size: int, max_seq_len: int, dropout: float = 0.1):\n",
|
||||
"\n",
|
||||
" super().__init__()\n",
|
||||
" self._heads = nn.ModuleList([\n",
|
||||
" HeadAttention(\n",
|
||||
" emb_size=emb_size, \n",
|
||||
" head_size=head_size, \n",
|
||||
" max_seq_len=max_seq_len\n",
|
||||
" ) for _ in range(num_heads)\n",
|
||||
" ])\n",
|
||||
" self._layer = nn.Linear(head_size * num_heads, emb_size)\n",
|
||||
" self._dropout = nn.Dropout(dropout)\n",
|
||||
"\n",
|
||||
" def forward(self, x: torch.Tensor, mask: torch.Tensor = None, use_cache: bool = True, cache: list = None):\n",
|
||||
"\n",
|
||||
" attention_results = []\n",
|
||||
" for i, head in enumerate(self._heads):\n",
|
||||
" head_cache = cache[i] if cache is not None else None\n",
|
||||
" result = head(x, use_cache=use_cache, cache=head_cache)\n",
|
||||
" attention_results.append(result)\n",
|
||||
" \n",
|
||||
" outputs, caches = zip(*attention_results)\n",
|
||||
" attention_outputs = list(outputs)\n",
|
||||
" kv_caches = list(caches)\n",
|
||||
" \n",
|
||||
" concatenated_attention = torch.cat(attention_outputs, dim=-1)\n",
|
||||
"\n",
|
||||
" projected_output = self._layer(concatenated_attention)\n",
|
||||
" \n",
|
||||
" final_output = self._dropout(projected_output)\n",
|
||||
" \n",
|
||||
" if use_cache is True:\n",
|
||||
" return (final_output, kv_caches)\n",
|
||||
" else:\n",
|
||||
" return (final_output, None)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class GELU(nn.Module):\n",
|
||||
" def __init__(self):\n",
|
||||
" super().__init__()\n",
|
||||
" self.sqrt_2_over_pi = torch.sqrt(torch.tensor(2.0) / math.pi)\n",
|
||||
" \n",
|
||||
" def forward(self, x: torch.Tensor) -> torch.Tensor:\n",
|
||||
" return 0.5 * x * (1 + torch.tanh(\n",
|
||||
" self.sqrt_2_over_pi * (x + 0.044715 * torch.pow(x, 3))\n",
|
||||
" ))\n",
|
||||
"\n",
|
||||
"class FeedForward(nn.Module):\n",
|
||||
"\n",
|
||||
" def __init__(self, emb_size: int, dropout: float = 0.1):\n",
|
||||
" super().__init__()\n",
|
||||
" self._layer1 = nn.Linear(emb_size, emb_size * 4)\n",
|
||||
" self._gelu = GELU()\n",
|
||||
" self._layer2 = nn.Linear(emb_size * 4, emb_size)\n",
|
||||
" self._dropout = nn.Dropout(dropout)\n",
|
||||
"\n",
|
||||
" def forward(self, x: torch.Tensor):\n",
|
||||
" input_dtype = x.dtype\n",
|
||||
" \n",
|
||||
" if input_dtype != self._layer1.weight.dtype:\n",
|
||||
" self._layer1 = self._layer1.to(dtype=input_dtype)\n",
|
||||
" self._layer2 = self._layer2.to(dtype=input_dtype)\n",
|
||||
" \n",
|
||||
" x = self._layer1(x)\n",
|
||||
" x = self._gelu(x)\n",
|
||||
" x = self._layer2(x)\n",
|
||||
" return self._dropout(x)\n",
|
||||
" \n",
|
||||
"class Decoder(nn.Module):\n",
|
||||
" def __init__(self, \n",
|
||||
" num_heads: int,\n",
|
||||
" emb_size: int,\n",
|
||||
" head_size: int,\n",
|
||||
" max_seq_len: int,\n",
|
||||
" dropout: float = 0.1\n",
|
||||
" ):\n",
|
||||
" super().__init__()\n",
|
||||
" self._heads = MultiHeadAttention(\n",
|
||||
" num_heads=num_heads, \n",
|
||||
" emb_size=emb_size, \n",
|
||||
" head_size=head_size, \n",
|
||||
" max_seq_len=max_seq_len, \n",
|
||||
" dropout=dropout\n",
|
||||
" )\n",
|
||||
" self._ff = FeedForward(emb_size=emb_size, dropout=dropout)\n",
|
||||
" self._norm1 = RMSNorm(emb_size)\n",
|
||||
" self._norm2 = RMSNorm(emb_size)\n",
|
||||
"\n",
|
||||
" def forward(self, x: torch.Tensor, mask: torch.Tensor = None, use_cache: bool = True, cache: list = None) -> torch.Tensor:\n",
|
||||
" norm1_out = self._norm1(x)\n",
|
||||
" attention, kv_caches = self._heads(norm1_out, mask, use_cache=use_cache, cache=cache)\n",
|
||||
" out = attention + x\n",
|
||||
" \n",
|
||||
" norm2_out = self._norm2(out)\n",
|
||||
" ffn_out = self._ff(norm2_out)\n",
|
||||
"\n",
|
||||
" if use_cache is True:\n",
|
||||
" return (ffn_out + out, kv_caches)\n",
|
||||
" else:\n",
|
||||
" return (ffn_out + out, None)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"from torch import nn\n",
|
||||
"import torch\n",
|
||||
"import torch.nn.functional as F\n",
|
||||
"\n",
|
||||
"class Llama(nn.Module):\n",
|
||||
" def __init__(self,\n",
|
||||
" vocab_size: int,\n",
|
||||
" max_seq_len: int,\n",
|
||||
" emb_size: int,\n",
|
||||
" num_heads: int,\n",
|
||||
" head_size: int,\n",
|
||||
" num_layers: int,\n",
|
||||
" dropout: float = 0.1,\n",
|
||||
" device: str = 'cpu'\n",
|
||||
" ):\n",
|
||||
" super().__init__()\n",
|
||||
" self._vocab_size = vocab_size\n",
|
||||
" self._max_seq_len = max_seq_len\n",
|
||||
" self._emb_size = emb_size\n",
|
||||
" self._num_heads = num_heads\n",
|
||||
" self._head_size = head_size\n",
|
||||
" self._num_layers = num_layers\n",
|
||||
" self._dropout = dropout\n",
|
||||
" self._device = device\n",
|
||||
" \n",
|
||||
" self.validation_loss = None\n",
|
||||
"\n",
|
||||
" # Инициализация слоев\n",
|
||||
" self._token_embeddings = TokenEmbeddings(\n",
|
||||
" vocab_size=vocab_size, \n",
|
||||
" emb_size=emb_size\n",
|
||||
" )\n",
|
||||
" self._position_embeddings = PositionalEmbeddings(\n",
|
||||
" max_seq_len=max_seq_len, \n",
|
||||
" emb_size=emb_size\n",
|
||||
" )\n",
|
||||
" self._dropout = nn.Dropout(dropout)\n",
|
||||
" self._decoders = nn.ModuleList([Decoder(\n",
|
||||
" num_heads=num_heads,\n",
|
||||
" emb_size=emb_size,\n",
|
||||
" head_size=head_size,\n",
|
||||
" max_seq_len=max_seq_len,\n",
|
||||
" dropout=dropout \n",
|
||||
" ) for _ in range(num_layers)])\n",
|
||||
" self._norm = RMSNorm(emb_size)\n",
|
||||
" self._linear = nn.Linear(emb_size, vocab_size)\n",
|
||||
"\n",
|
||||
" def forward(self, x: torch.Tensor, use_cache: bool = True, cache: list = None) -> tuple:\n",
|
||||
" # Проверка длины последовательности (только при отсутствии кэша)\n",
|
||||
" if cache is None and x.size(1) > self._max_seq_len:\n",
|
||||
" raise ValueError(f\"Длина последовательности {x.size(1)} превышает максимальную {self.max_seq_len}\")\n",
|
||||
" \n",
|
||||
" \n",
|
||||
" # Вычисление start_pos из кэша (если кэш передан)\n",
|
||||
" if cache is not None:\n",
|
||||
" # При кэше обрабатываем только один токен (последний)\n",
|
||||
" seq_len = 1\n",
|
||||
" # Вычисляем start_pos из самого нижнего уровня кэша\n",
|
||||
" if cache and cache[0] and cache[0][0]:\n",
|
||||
" key_cache, _ = cache[0][0] # Первый декодер, первая голова\n",
|
||||
" start_pos = key_cache.size(1) # cache_len\n",
|
||||
" else:\n",
|
||||
" start_pos = 0\n",
|
||||
" else:\n",
|
||||
" # Без кэша работаем как раньше\n",
|
||||
" start_pos = 0\n",
|
||||
" seq_len = x.size(1)\n",
|
||||
"\n",
|
||||
" # Эмбеддинги токенов и позиций\n",
|
||||
" tok_out = self._token_embeddings(x) # [batch, seq_len, emb_size]\n",
|
||||
" pos_out = self._position_embeddings(seq_len, start_pos=start_pos) # [seq_len, emb_size]\n",
|
||||
" \n",
|
||||
" # Комбинирование\n",
|
||||
" out = self._dropout(tok_out + pos_out.unsqueeze(0)) # [batch, seq_len, emb_size]\n",
|
||||
" \n",
|
||||
" # Стек декодеров с передачей кэша\n",
|
||||
" new_cache = []\n",
|
||||
" for i, decoder in enumerate(self._decoders):\n",
|
||||
" decoder_cache = cache[i] if cache is not None else None\n",
|
||||
" decoder_result = decoder(out, use_cache=use_cache, cache=decoder_cache)\n",
|
||||
"\n",
|
||||
" # Извлекаем результат из кортежа\n",
|
||||
" if use_cache:\n",
|
||||
" out, decoder_new_cache = decoder_result\n",
|
||||
" new_cache.append(decoder_new_cache)\n",
|
||||
" else:\n",
|
||||
" out = decoder_result[0]\n",
|
||||
"\n",
|
||||
" out = self._norm(out)\n",
|
||||
" logits = self._linear(out)\n",
|
||||
" \n",
|
||||
" # Возвращаем результат с учетом use_cache\n",
|
||||
" if use_cache:\n",
|
||||
" return (logits, new_cache)\n",
|
||||
" else:\n",
|
||||
" return (logits, None)\n",
|
||||
"\n",
|
||||
" def generate(self,\n",
|
||||
" x: torch.Tensor, \n",
|
||||
" max_new_tokens: int, \n",
|
||||
" do_sample: bool,\n",
|
||||
" temperature: float = 1.0,\n",
|
||||
" top_k: int = None,\n",
|
||||
" top_p: float = None,\n",
|
||||
" use_cache: bool = True\n",
|
||||
" ) -> torch.Tensor:\n",
|
||||
" cache = None\n",
|
||||
"\n",
|
||||
" for _ in range(max_new_tokens):\n",
|
||||
" if use_cache and cache is not None:\n",
|
||||
" # Используем кэш - передаем только последний токен\n",
|
||||
" x_input = x[:, -1:] # [batch_size, 1]\n",
|
||||
" else:\n",
|
||||
" # Первая итерация или кэш отключен - передаем всю последовательность\n",
|
||||
" x_input = x\n",
|
||||
" \n",
|
||||
" # Прямой проход с кэшем\n",
|
||||
" logits, new_cache = self.forward(x_input, use_cache=use_cache, cache=cache)\n",
|
||||
" \n",
|
||||
" # Обновляем кэш для следующей итерации\n",
|
||||
" if use_cache:\n",
|
||||
" cache = new_cache\n",
|
||||
"\n",
|
||||
" last_logits = logits[:, -1, :] # [batch_size, vocab_size]\n",
|
||||
"\n",
|
||||
" # Масштабируем логиты температурой\n",
|
||||
" if temperature > 0:\n",
|
||||
" logits_scaled = last_logits / temperature\n",
|
||||
" else:\n",
|
||||
" logits_scaled = last_logits\n",
|
||||
"\n",
|
||||
" if do_sample == True and top_k != None:\n",
|
||||
" _, topk_indices = torch.topk(logits_scaled, top_k, dim=-1)\n",
|
||||
"\n",
|
||||
" # # Заменим все НЕ top-k логиты на -inf\n",
|
||||
" masked_logits = logits_scaled.clone()\n",
|
||||
" vocab_size = logits_scaled.size(-1)\n",
|
||||
"\n",
|
||||
" # создаём маску: 1, если токен НЕ в topk_indices\n",
|
||||
" mask = torch.ones_like(logits_scaled, dtype=torch.uint8)\n",
|
||||
" mask.scatter_(1, topk_indices, 0) # 0 там, где top-k индексы\n",
|
||||
" masked_logits[mask.byte()] = float('-inf')\n",
|
||||
"\n",
|
||||
" logits_scaled = masked_logits\n",
|
||||
"\n",
|
||||
" if do_sample == True and top_p != None:\n",
|
||||
" # 1. Применим softmax, чтобы получить вероятности:\n",
|
||||
" probs = F.softmax(logits_scaled, dim=-1) # [B, vocab_size]\n",
|
||||
" # 2. Отсортируем токены по убыванию вероятностей:\n",
|
||||
" sorted_probs, sorted_indices = torch.sort(probs, descending=True, dim=-1)\n",
|
||||
" # 3. Посчитаем кумулятивную сумму вероятностей:\n",
|
||||
" cum_probs = torch.cumsum(sorted_probs, dim=-1) # [B, vocab_size]\n",
|
||||
" # 4. Определим маску: оставить токены, пока сумма < top_p\n",
|
||||
" sorted_mask = (cum_probs <= top_p).byte() # [B, vocab_size]\n",
|
||||
" # Гарантируем, что хотя бы первый токен останется\n",
|
||||
" sorted_mask[:, 0] = 1\n",
|
||||
" # 5. Преобразуем маску обратно в оригинальный порядок:\n",
|
||||
" # Создаём полную маску из 0\n",
|
||||
" mask = torch.zeros_like(probs, dtype=torch.uint8)\n",
|
||||
" # Устанавливаем 1 в местах нужных токенов\n",
|
||||
" mask.scatter_(dim=1, index=sorted_indices, src=sorted_mask)\n",
|
||||
" # 6. Зануляем логиты токенов вне топ-p:\n",
|
||||
" logits_scaled[~mask] = float('-inf')\n",
|
||||
"\n",
|
||||
" # 4. Применяем Softmax\n",
|
||||
" probs = F.softmax(logits_scaled, dim=-1) # [batch_size, vocab_size]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" if do_sample == True:\n",
|
||||
" # 5. Если do_sample равен True, то отбираем токен случайно с помощью torch.multinomial\n",
|
||||
" next_token = torch.multinomial(probs, num_samples=1) # [batch_size, 1]\n",
|
||||
" else:\n",
|
||||
" # 5. Если do_sample равен False, то выбираем токен с максимальной вероятностью\n",
|
||||
" next_token = torch.argmax(probs, dim=-1, keepdim=True) # [batch_size, 1]\n",
|
||||
" \n",
|
||||
" # 6. Добавляем его к последовательности\n",
|
||||
" x = torch.cat([x, next_token], dim=1) # [batch_size, seq_len+1]\n",
|
||||
" return x\n",
|
||||
"\n",
|
||||
" def save(self, path):\n",
|
||||
" torch.save({\n",
|
||||
" 'model_state_dict': self.state_dict(),\n",
|
||||
" 'vocab_size': self._vocab_size,\n",
|
||||
" 'max_seq_len': self._max_seq_len,\n",
|
||||
" 'emb_size': self._emb_size,\n",
|
||||
" 'num_heads': self._num_heads,\n",
|
||||
" 'head_size': self._head_size,\n",
|
||||
" 'num_layers': self._num_layers\n",
|
||||
" }, path)\n",
|
||||
"\n",
|
||||
" @classmethod\n",
|
||||
" def load(cls, path, device):\n",
|
||||
" checkpoint = torch.load(path, map_location=device)\n",
|
||||
" model = cls(\n",
|
||||
" vocab_size=checkpoint['vocab_size'],\n",
|
||||
" max_seq_len=checkpoint['max_seq_len'],\n",
|
||||
" emb_size=checkpoint['emb_size'],\n",
|
||||
" num_heads=checkpoint['num_heads'],\n",
|
||||
" head_size=checkpoint['head_size'],\n",
|
||||
" num_layers=checkpoint['num_layers']\n",
|
||||
" )\n",
|
||||
" model.load_state_dict(checkpoint['model_state_dict'])\n",
|
||||
" model.to(device)\n",
|
||||
" return model\n",
|
||||
"\n",
|
||||
" @property\n",
|
||||
" def max_seq_len(self) -> int:\n",
|
||||
" return self._max_seq_len"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "8efb1396",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.9"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
Reference in New Issue
Block a user