mirror of
https://github.com/pese-git/llm-arch-research.git
synced 2026-05-16 10:09:42 +00:00
docs: add analysis notebooks for BPE and GPT
- Add bpe.ipynb with Byte Pair Encoding implementation analysis - Update gpt_analysis.ipynb with GPT model experiments and visualizations
This commit is contained in:
278
notebooks/bpe.ipynb
Normal file
278
notebooks/bpe.ipynb
Normal file
@@ -0,0 +1,278 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2bda8231",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Byte Pair Encoding (BPE)\n",
|
||||
"\n",
|
||||
"**Byte Pair Encoding (BPE)** — это алгоритм, изначально предложенный для *сжатия данных*, однако впоследствии он был адаптирован для решения задач *токенизации текстов* в NLP-моделях.\n",
|
||||
"\n",
|
||||
"В контексте обработки естественного языка BPE позволяет представлять текст в виде ограниченного набора токенов, сохраняя при этом способность выразить любые слова, включая редкие или не встречавшиеся ранее (out-of-vocabulary).\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"## Основная идея\n",
|
||||
"\n",
|
||||
"Главная идея BPE заключается в **итеративном объединении наиболее часто встречающихся пар символов** в новые, более крупные единицы — *токены*.\n",
|
||||
"Этот процесс постепенно строит иерархию от отдельных символов до целых подслов и слов, формируя тем самым *оптимальный словарь токенов* для данного корпуса текста.\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"## Алгоритм\n",
|
||||
"\n",
|
||||
"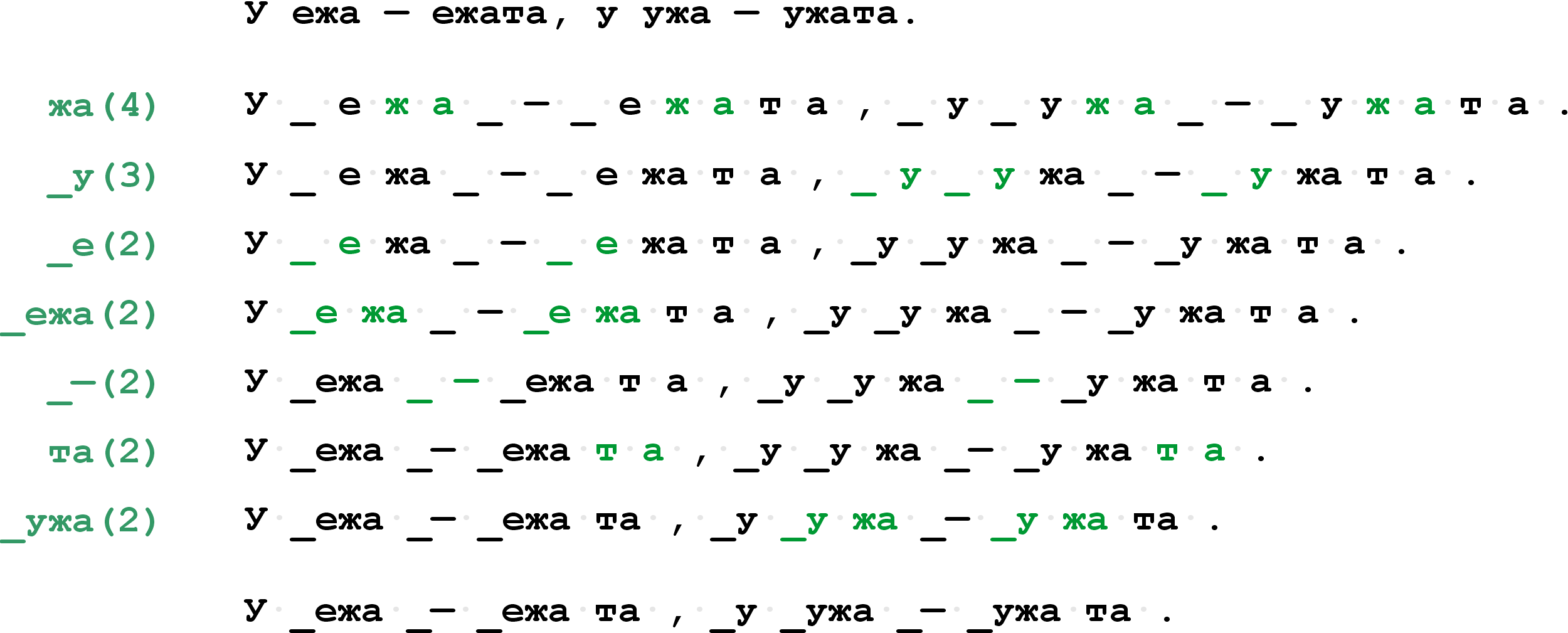\n",
|
||||
"\n",
|
||||
"Рассмотрим пошагово, как работает классический алгоритм BPE:\n",
|
||||
"\n",
|
||||
"1. **Инициализация.**\n",
|
||||
" Текстовый корпус разбивается на отдельные символы.\n",
|
||||
" Например, слово `lower` представляется как `l o w e r`.\n",
|
||||
" Каждый уникальный символ добавляется в словарь токенов — это гарантирует, что любая последовательность текста может быть декодирована обратно.\n",
|
||||
"\n",
|
||||
"2. **Подсчёт частот пар.**\n",
|
||||
" Для каждой последовательности токенов в корпусе подсчитываются частоты всех возможных *соседних пар токенов*.\n",
|
||||
" Например, если в корпусе часто встречается пара `('t', 'h')`, то она имеет высокий приоритет для объединения.\n",
|
||||
"\n",
|
||||
"3. **Объединение самой частой пары.**\n",
|
||||
" Находится наиболее часто встречающаяся пара токенов, например `('t', 'h')`, и заменяется на новый токен `('th')`.\n",
|
||||
" Этот новый токен добавляется в словарь.\n",
|
||||
"\n",
|
||||
"4. **Обновление корпуса.**\n",
|
||||
" Все вхождения выбранной пары заменяются новым токеном.\n",
|
||||
" После этого подсчёт частот повторяется на обновлённом тексте.\n",
|
||||
"\n",
|
||||
"5. **Итерации.**\n",
|
||||
" Процесс продолжается до тех пор, пока:\n",
|
||||
"\n",
|
||||
" * не будет достигнут желаемый размер словаря (например, 50 000 токенов);\n",
|
||||
" * или частоты оставшихся пар перестанут иметь практическое значение.\n",
|
||||
"\n",
|
||||
"В итоге получаем словарь, в котором одни токены представляют отдельные символы, другие — подслова или целые слова.\n",
|
||||
"\n",
|
||||
"Это компромисс между избыточностью (символьная токенизация) и излишней обобщённостью (словная токенизация).\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"## Byte-Level BPE\n",
|
||||
"\n",
|
||||
"В токенизаторах, используемых, например, OpenAI, применяется **Byte-Level BPE** — модификация, работающая не с текстовыми символами, а с их *байтовыми представлениями*.\n",
|
||||
"\n",
|
||||
"Преимущества этого подхода:\n",
|
||||
"\n",
|
||||
"* Полная языковая универсальность — один и тот же словарь способен обрабатывать тексты на любом языке, включая редкие и смешанные языки.\n",
|
||||
"* Поддержка любых Unicode-символов и эмодзи.\n",
|
||||
"* Компактность: итоговый словарь можно ограничить примерно 50 000 токенами без потери выразительности.\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"## Современные модификации\n",
|
||||
"\n",
|
||||
"Оригинальный BPE сегодня практически не используется в чистом виде.\n",
|
||||
"Каждая крупная модель или библиотека имеет свои вариации алгоритма токенизации, адаптированные под конкретные цели.\n",
|
||||
"\n",
|
||||
"Некоторые отличия в промышленных реализациях:\n",
|
||||
"\n",
|
||||
"* **GPT-2:** запрещалось объединять токены разных типов (например, букву и знак препинания `a?`). Это сохраняло читаемость текста.\n",
|
||||
"* **GPT-3:** снято ограничение на смешивание типов токенов, но введено правило: нельзя объединять более трёх цифр подряд в один токен.\n",
|
||||
"* **GPT-4:** применяется нормализация некоторых редких Unicode-символов — например, разные типы кавычек приводятся к стандартному виду `\"`.\n",
|
||||
"* **LLaMA:** запрещено создавать токены, состоящие только из пробелов или управляющих символов (например, `\"\\n\\n\"`).\n",
|
||||
"\n",
|
||||
"Таким образом, несмотря на общие принципы, **каждый токенизатор уникален**, отражая баланс между эффективностью, универсальностью и удобством декодирования.\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## Итог\n",
|
||||
"\n",
|
||||
"Byte Pair Encoding — это не просто алгоритм токенизации, а компромисс между чисто символьным и чисто словарным представлением текста.\n",
|
||||
"Он обеспечивает:\n",
|
||||
"\n",
|
||||
"* компактный словарь фиксированного размера,\n",
|
||||
"* возможность обработки любых текстов, включая ранее невиданные слова,\n",
|
||||
"* эффективность при обучении языковых моделей, где баланс между размером словаря и длиной последовательностей критичен.\n",
|
||||
"\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e8c52a53",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"ename": "",
|
||||
"evalue": "",
|
||||
"output_type": "error",
|
||||
"traceback": [
|
||||
"\u001b[1;31mRunning cells with '.venv (Python 3.10.9)' requires the ipykernel package.\n",
|
||||
"\u001b[1;31mInstall 'ipykernel' into the Python environment. \n",
|
||||
"\u001b[1;31mCommand: '/Users/sergey/Projects/ML/llm-arch-research/.venv/bin/python -m pip install ipykernel -U --force-reinstall'"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import dill\n",
|
||||
"\n",
|
||||
"class BPE:\n",
|
||||
" def __init__(self, vocab_size: int):\n",
|
||||
" self.vocab_size = vocab_size\n",
|
||||
" self.id2token = {}\n",
|
||||
" self.token2id = {}\n",
|
||||
"\n",
|
||||
" def fit(self, text: str):\n",
|
||||
" # 1. Получаем уникальные токены (символы)\n",
|
||||
" unique_tokens = sorted(set(text))\n",
|
||||
" tokens = unique_tokens.copy()\n",
|
||||
"\n",
|
||||
" # 2. Разбиваем текст на токены-символы\n",
|
||||
" sequence = list(text)\n",
|
||||
"\n",
|
||||
" # 3. Объединяем токены до достижения нужного размера словаря\n",
|
||||
" while len(tokens) < self.vocab_size:\n",
|
||||
" #print(f'len={len(tokens)} < {self.vocab_size}')\n",
|
||||
" # Считаем частоты пар\n",
|
||||
" pair_freq = {}\n",
|
||||
" for i in range(len(sequence) - 1):\n",
|
||||
" pair = (sequence[i], sequence[i + 1])\n",
|
||||
" #print(f'pair = {pair}')\n",
|
||||
" if pair not in pair_freq:\n",
|
||||
" pair_freq[pair] = 0\n",
|
||||
" pair_freq[pair] += 1\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" #print(f'pair_freq = {pair_freq}') \n",
|
||||
" if not pair_freq:\n",
|
||||
" break # нет пар — выходим\n",
|
||||
"\n",
|
||||
" #for x in pair_freq.items():\n",
|
||||
" # self.debug(x, sequence)\n",
|
||||
"\n",
|
||||
" # Находим самую частую пару (в случае равенства — та, что встретилась первой)\n",
|
||||
" most_frequent_pair = max(pair_freq.items(), key=lambda x: (x[1], -self._pair_first_index(sequence, x[0])))[0]\n",
|
||||
" #print(most_frequent_pair)\n",
|
||||
" # Создаем новый токен\n",
|
||||
" new_token = most_frequent_pair[0] + most_frequent_pair[1]\n",
|
||||
" #print(f\"new token={new_token}\")\n",
|
||||
" tokens.append(new_token)\n",
|
||||
" #print(f\"tokens={tokens}\")\n",
|
||||
"\n",
|
||||
" i = 0\n",
|
||||
" new_sequence = []\n",
|
||||
"\n",
|
||||
" while i < len(sequence):\n",
|
||||
" if i < len(sequence) - 1 and (sequence[i], sequence[i + 1]) == most_frequent_pair:\n",
|
||||
" new_sequence.append(new_token)\n",
|
||||
" i += 2 # пропускаем два символа — заменённую пару\n",
|
||||
" else:\n",
|
||||
" new_sequence.append(sequence[i])\n",
|
||||
" i += 1\n",
|
||||
" sequence = new_sequence\n",
|
||||
" #break\n",
|
||||
" \n",
|
||||
" # 4. Создаем словари\n",
|
||||
" self.vocab = tokens.copy()\n",
|
||||
" self.token2id = dict(zip(tokens, range(self.vocab_size)))\n",
|
||||
" self.id2token = dict(zip(range(self.vocab_size), tokens))\n",
|
||||
"\n",
|
||||
" def _pair_first_index(self, sequence, pair):\n",
|
||||
" for i in range(len(sequence) - 1):\n",
|
||||
" if (sequence[i], sequence[i + 1]) == pair:\n",
|
||||
" return i\n",
|
||||
" return float('inf') # если пара не найдена (в теории не должно случиться)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" def encode(self, text: str):\n",
|
||||
" # 1. Разбиваем текст на токены-символы\n",
|
||||
" sequence = list(text)\n",
|
||||
" # 2. Инициализация пустого списка токенов\n",
|
||||
" tokens = []\n",
|
||||
" # 3. Установить i = 0\n",
|
||||
" i = 0\n",
|
||||
" while i < len(text):\n",
|
||||
" # 3.1 Найти все токены в словаре, начинающиеся с text[i]\n",
|
||||
" start_char = text[i]\n",
|
||||
" result = [token for token in self.vocab if token.startswith(start_char)]\n",
|
||||
" # 3.2 Выбрать самый длинный подходящий токен\n",
|
||||
" find_token = self._find_max_matching_token(text[i:], result)\n",
|
||||
" if find_token is None:\n",
|
||||
" # Обработка неизвестного символа\n",
|
||||
" tokens.append(text[i]) # Добавляем сам символ как токен\n",
|
||||
" i += 1\n",
|
||||
" else:\n",
|
||||
" # 3.3 Добавить токен в результат\n",
|
||||
" tokens.append(find_token)\n",
|
||||
" # 3.4 Увеличить i на длину токена\n",
|
||||
" i += len(find_token)\n",
|
||||
"\n",
|
||||
" # 4. Заменить токены на их ID\n",
|
||||
" return self._tokens_to_ids(tokens)\n",
|
||||
"\n",
|
||||
" def _find_max_matching_token(self, text: str, tokens: list):\n",
|
||||
" \"\"\"Находит самый длинный токен из списка, с которого начинается текст\"\"\"\n",
|
||||
" matching = [token for token in tokens if text.startswith(token)]\n",
|
||||
" return max(matching, key=len) if matching else None\n",
|
||||
"\n",
|
||||
" def _tokens_to_ids(self, tokens):\n",
|
||||
" \"\"\"Конвертирует список токенов в их ID с обработкой неизвестных токенов\"\"\"\n",
|
||||
" ids = []\n",
|
||||
" for token in tokens:\n",
|
||||
" if token in self.token2id:\n",
|
||||
" ids.append(self.token2id[token])\n",
|
||||
" else:\n",
|
||||
" ids.append(-1) # Специальное значение\n",
|
||||
" return ids\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" def decode(self, ids: list) -> str:\n",
|
||||
" return ''.join(self._ids_to_tokens(ids))\n",
|
||||
"\n",
|
||||
" def _ids_to_tokens(self, ids: list) -> list:\n",
|
||||
" \"\"\"Конвертирует список Ids в их tokens\"\"\"\n",
|
||||
" tokens = []\n",
|
||||
" for id in ids:\n",
|
||||
" if id in self.id2token:\n",
|
||||
" tokens.append(self.id2token[id])\n",
|
||||
" else:\n",
|
||||
" tokens.append('') # Специальное значение\n",
|
||||
" return tokens\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" def save(self, filename):\n",
|
||||
" with open(filename, 'wb') as f:\n",
|
||||
" dill.dump(self, f)\n",
|
||||
" print(f\"Объект сохранён в {filename}\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" @classmethod\n",
|
||||
" def load(cls, filename):\n",
|
||||
" with open(filename, 'rb') as f:\n",
|
||||
" obj = dill.load(f)\n",
|
||||
" \n",
|
||||
" print(f\"Объект загружен из {filename}\")\n",
|
||||
" return obj"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a9ae19e5",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"name": "python",
|
||||
"version": "3.10.9"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,435 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6842e799",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"\n",
|
||||
"# Архитектура GPT-1: Принципы работы и ключевые компоненты\n",
|
||||
"\n",
|
||||
"Модель **GPT-1 (Generative Pretrained Transformer)** — это первая реализация идеи создания языковой модели на основе архитектуры **Transformer Decoder**, предложенной в работе *“Improving Language Understanding by Generative Pre-Training”* (OpenAI, 2018).\n",
|
||||
"Она заложила фундамент всех последующих поколений GPT-моделей, показав, что модель, обученная на большом корпусе текстов в режиме **предсказания следующего токена**, способна эффективно адаптироваться к различным задачам обработки естественного языка.\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"## Основная архитектура\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Модель GPT-1 представляет собой **каскад из 12 идентичных слоев декодера трансформера**. Каждый слой обрабатывает входную последовательность токенов, улучшая их представление на каждом этапе.\n",
|
||||
"Основная идея заключается в том, что модель учится предсказывать следующий токен в тексте, имея контекст всех предыдущих.\n",
|
||||
"\n",
|
||||
"Рассмотрим основные компоненты модели подробнее.\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"### 1. Векторные представления (Эмбеддинги)\n",
|
||||
"\n",
|
||||
"Перед тем как текст поступает в трансформер, он преобразуется в числовую форму — **векторные представления**.\n",
|
||||
"\n",
|
||||
"* **Эмбеддинги токенов (Token Embeddings)**\n",
|
||||
" Каждый токен (слово, подслово или символ) преобразуется в вектор фиксированной размерности. Эти векторы формируются в процессе обучения модели и кодируют семантическое значение токенов — токены с похожим смыслом имеют близкие векторы в пространстве.\n",
|
||||
"\n",
|
||||
"* **Позиционные эмбеддинги (Positional Embeddings)**\n",
|
||||
" Поскольку архитектура трансформера не учитывает порядок элементов последовательности (в отличие от RNN), в GPT добавляются позиционные эмбеддинги.\n",
|
||||
" Они вводят информацию о позиции каждого токена в предложении, позволяя модели различать, например, «кот съел рыбу» и «рыба съела кота».\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"### 2. Блоки декодера трансформера\n",
|
||||
"\n",
|
||||
"Каждый слой модели GPT состоит из двух ключевых компонентов:\n",
|
||||
"\n",
|
||||
"#### a. Маскированное многоголовое внимание (Masked Multi-Head Attention)\n",
|
||||
"\n",
|
||||
"Механизм **внимания (attention)** позволяет модели определять, какие части предыдущего контекста наиболее важны для текущего токена.\n",
|
||||
"В GPT используется **маскированное внимание**, что означает, что токен на позиции *i* может \"смотреть\" только на токены, стоящие перед ним (позиции ≤ *i*).\n",
|
||||
"Это обеспечивает **каузальность** — свойство, благодаря которому модель не «знает будущее», что важно для генерации текста слева направо.\n",
|
||||
"\n",
|
||||
"Многоголовое внимание (multi-head attention) разбивает входные векторы на несколько подпространств (голов), каждая из которых учится улавливать разные типы зависимостей — синтаксические, семантические и др.\n",
|
||||
"Результаты всех голов объединяются и проецируются обратно в исходное пространство признаков.\n",
|
||||
"\n",
|
||||
"#### b. Полносвязная сеть (Feed-Forward Network, FFN)\n",
|
||||
"\n",
|
||||
"После внимания каждый токен независимо проходит через небольшую двухслойную нейронную сеть с функцией активации (в GPT-1 используется ReLU).\n",
|
||||
"Эта сеть увеличивает нелинейность модели и помогает ей лучше представлять сложные зависимости в данных.\n",
|
||||
"\n",
|
||||
"#### c. Остаточные связи и нормализация (Residual Connections + Layer Normalization)\n",
|
||||
"\n",
|
||||
"Чтобы стабилизировать обучение, выход каждого подблока (attention и FFN) складывается с его входом (residual connection), а затем нормализуется (LayerNorm).\n",
|
||||
"Остаточные связи помогают избежать исчезновения градиентов, а нормализация ускоряет сходимость при обучении.\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"### 3. Выходной слой\n",
|
||||
"\n",
|
||||
"После прохождения всех блоков декодера итоговое представление токенов передается в **линейный слой**, который проецирует его в пространство размерности словаря.\n",
|
||||
"Результатом являются **логиты** — сырые оценки вероятностей появления каждого токена из словаря.\n",
|
||||
"\n",
|
||||
"Далее применяется функция **Softmax**, которая преобразует логиты в вероятностное распределение.\n",
|
||||
"Наиболее вероятный токен выбирается как следующий элемент последовательности.\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"## Токенизация и авторегрессия\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"### Токенизация\n",
|
||||
"\n",
|
||||
"**Токенизатор** — это отдельный компонент, преобразующий текст в последовательность токенов (целых чисел).\n",
|
||||
"Он делит текст на минимальные осмысленные единицы (например, слова, подслова или символы) и сопоставляет каждой единице уникальный идентификатор.\n",
|
||||
"\n",
|
||||
"Пример:\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"Текст: \"Привет, мир!\"\n",
|
||||
"Токены: [15496, 11, 995]\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"Модель GPT работает именно с этой числовой последовательностью.\n",
|
||||
"На выходе модель также производит последовательность токенов, которые затем декодируются обратно в текст с помощью того же токенизатора.\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"### Авторегрессия\n",
|
||||
"\n",
|
||||
"GPT — **авторегрессионная модель**, то есть она предсказывает следующий токен, используя уже сгенерированные.\n",
|
||||
"Процесс генерации происходит пошагово:\n",
|
||||
"\n",
|
||||
"1. Модели подается начальная последовательность (например, «Once upon a time»).\n",
|
||||
"2. Модель вычисляет распределение вероятностей следующего токена и выбирает наиболее вероятный.\n",
|
||||
"3. Новый токен добавляется в конец входной последовательности.\n",
|
||||
"4. Процесс повторяется, пока не будет достигнут нужный размер текста или не сработает условие остановки.\n",
|
||||
"\n",
|
||||
"Таким образом, каждый новый токен порождается с учетом **всего контекста** — от начала до текущего шага.\n",
|
||||
"Этот принцип обеспечивает связность и контекстуальную осмысленность текста.\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"\n",
|
||||
"## Заключение\n",
|
||||
"\n",
|
||||
"GPT-1 продемонстрировала, что **предобучение на больших объемах неразмеченных данных** с последующим **тонким дообучением** на конкретной задаче может дать отличные результаты в обработке естественного языка.\n",
|
||||
"Несмотря на то, что модель GPT-1 сравнительно мала по современным меркам (117 млн параметров), именно она заложила архитектурные и концептуальные основы для всех последующих поколений — GPT-2, GPT-3 и GPT-4."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d763e797",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6ed35205",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## BPE Tokenizator"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "1a6f2914",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"ename": "",
|
||||
"evalue": "",
|
||||
"output_type": "error",
|
||||
"traceback": [
|
||||
"\u001b[1;31mRunning cells with '.venv (Python 3.10.9)' requires the ipykernel package.\n",
|
||||
"\u001b[1;31mInstall 'ipykernel' into the Python environment. \n",
|
||||
"\u001b[1;31mCommand: '/Users/sergey/Projects/ML/llm-arch-research/.venv/bin/python -m pip install ipykernel -U --force-reinstall'"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# llm/models/gpt/gpt2.py\n",
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import torch.nn.functional as F\n",
|
||||
"from llm.core.base_model import BaseModel\n",
|
||||
"from llm.core.decoder import Decoder\n",
|
||||
"from llm.core.token_embeddings import TokenEmbeddings\n",
|
||||
"from llm.core.positional_embeddings import PositionalEmbeddings\n",
|
||||
"\n",
|
||||
"class GPT(BaseModel):\n",
|
||||
" \"\"\"GPT-like трансформер для генерации текста\n",
|
||||
" \n",
|
||||
" Args:\n",
|
||||
" vocab_size: Размер словаря\n",
|
||||
" max_seq_len: Макс. длина последовательности\n",
|
||||
" emb_size: Размерность эмбеддингов\n",
|
||||
" num_heads: Количество голов внимания\n",
|
||||
" head_size: Размерность голов внимания\n",
|
||||
" num_layers: Количество слоёв декодера\n",
|
||||
" dropout: Вероятность dropout (default=0.1)\n",
|
||||
" device: Устройство (default='cpu')\n",
|
||||
" \"\"\"\n",
|
||||
" def __init__(self, config):\n",
|
||||
" super().__init__(config)\n",
|
||||
"\n",
|
||||
" # Инициализация слоев\n",
|
||||
" self._max_seq_len = config[\"max_position_embeddings\"]\n",
|
||||
" self._token_embeddings = TokenEmbeddings(\n",
|
||||
" vocab_size=config[\"vocab_size\"], \n",
|
||||
" emb_size=config[\"embed_dim\"]\n",
|
||||
" )\n",
|
||||
" self._position_embeddings = PositionalEmbeddings(\n",
|
||||
" max_seq_len=config[\"max_position_embeddings\"], \n",
|
||||
" emb_size=config[\"embed_dim\"]\n",
|
||||
" )\n",
|
||||
" self._dropout = nn.Dropout(config[\"dropout\"])\n",
|
||||
" # head_size = emb_size // num_heads\n",
|
||||
" self._decoders = nn.ModuleList([Decoder(\n",
|
||||
" num_heads=config[\"num_heads\"],\n",
|
||||
" emb_size=config[\"embed_dim\"],\n",
|
||||
" head_size=config[\"embed_dim\"] // config[\"num_heads\"],\n",
|
||||
" max_seq_len=config[\"max_position_embeddings\"],\n",
|
||||
" dropout=config[\"dropout\"] \n",
|
||||
" ) for _ in range(config[\"num_layers\"])])\n",
|
||||
" self._linear = nn.Linear(config[\"embed_dim\"], config[\"vocab_size\"])\n",
|
||||
" \n",
|
||||
" @property\n",
|
||||
" def max_seq_len(self):\n",
|
||||
" \"\"\"Возвращает максимальную длину последовательности.\"\"\"\n",
|
||||
" return self._max_seq_len\n",
|
||||
"\n",
|
||||
" def forward(self, x: torch.Tensor, attention_mask=None) -> torch.Tensor:\n",
|
||||
" \"\"\"Прямой проход через GPT\n",
|
||||
" \n",
|
||||
" Args:\n",
|
||||
" x: Входной тензор [batch_size, seq_len]\n",
|
||||
" \n",
|
||||
" Returns:\n",
|
||||
" Тензор логитов [batch_size, seq_len, vocab_size]\n",
|
||||
" \"\"\"\n",
|
||||
" # Проверка длины последовательности\n",
|
||||
" if x.size(1) > self._max_seq_len:\n",
|
||||
" raise ValueError(f\"Длина последовательности {x.size(1)} превышает максимальную {self._max_seq_len}\")\n",
|
||||
" \n",
|
||||
" # Эмбеддинги токенов и позиций\n",
|
||||
" tok_out = self._token_embeddings(x) # [batch, seq_len, emb_size]\n",
|
||||
" pos_out = self._position_embeddings(x.size(1)) # [seq_len, emb_size]\n",
|
||||
" \n",
|
||||
" # Комбинирование\n",
|
||||
" out = self._dropout(tok_out + pos_out.unsqueeze(0)) # [batch, seq_len, emb_size]\n",
|
||||
" \n",
|
||||
" # Стек декодеров\n",
|
||||
" for decoder in self._decoders:\n",
|
||||
" out = decoder(out)\n",
|
||||
" \n",
|
||||
" return self._linear(out) # [batch, seq_len, vocab_size]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# def forward(self, input_ids, attention_mask=None):\n",
|
||||
"# B, T = input_ids.size()\n",
|
||||
"# pos = torch.arange(0, T, device=input_ids.device).unsqueeze(0)\n",
|
||||
"#\n",
|
||||
"# x = self.token_emb(input_ids) + self.pos_emb(pos)\n",
|
||||
"#\n",
|
||||
"# for block in self.blocks:\n",
|
||||
"# x = block(x, attention_mask)\n",
|
||||
"#\n",
|
||||
"# x = self.ln_f(x)\n",
|
||||
"# logits = self.head(x)\n",
|
||||
"# return logits\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" def generate(self,\n",
|
||||
" x: torch.Tensor, \n",
|
||||
" max_new_tokens: int, \n",
|
||||
" do_sample: bool,\n",
|
||||
" temperature: float = 1.0,\n",
|
||||
" top_k: int = None,\n",
|
||||
" top_p: float = None,\n",
|
||||
" attention_mask: torch.Tensor = None, # Добавляем для совместимости с HF\n",
|
||||
" **kwargs # Игнорируем остальные параметры\n",
|
||||
" ) -> torch.Tensor:\n",
|
||||
" \"\"\"Авторегрессивная генерация текста.\n",
|
||||
" \n",
|
||||
" Параметры:\n",
|
||||
" x: Входной тензор с индексами токенов формы [batch_size, seq_len],\n",
|
||||
" где batch_size - размер батча, seq_len - длина последовательности.\n",
|
||||
" max_new_tokens: Максимальное количество новых токенов для генерации.\n",
|
||||
" do_sample: Флаг выбора режима генерации:\n",
|
||||
" - True: вероятностное сэмплирование\n",
|
||||
" - False: жадный поиск (argmax)\n",
|
||||
" temperature: Параметр температуры для сэмплирования:\n",
|
||||
" - >1.0 - более случайные результаты\n",
|
||||
" - 1.0 - нейтральное значение\n",
|
||||
" - <1.0 - более предсказуемые результаты\n",
|
||||
" Должна быть > 0 (по умолчанию: 1.0)\n",
|
||||
" top_k: Если задан (и do_sample=True), используется top-k сэмплирование:\n",
|
||||
" - Выбираются только top_k самых вероятных токенов\n",
|
||||
" - Остальным токенам устанавливается вероятность 0\n",
|
||||
" - None: отключено (по умолчанию)\n",
|
||||
" top_p: Если задан (и do_sample=True), используется nucleus (top-p) сэмплирование:\n",
|
||||
" - Выбираются токены с кумулятивной вероятностью ≤ top_p\n",
|
||||
" - Гарантируется, что хотя бы один токен остаётся (даже если его вероятность > top_p)\n",
|
||||
" - None: отключено (по умолчанию)\n",
|
||||
" - Должен быть в диапазоне (0, 1]\n",
|
||||
" \n",
|
||||
" Возвращает:\n",
|
||||
" torch.Tensor: Тензор с расширенной последовательностью токенов формы \n",
|
||||
" [batch_size, seq_len + max_new_tokens]\n",
|
||||
"\n",
|
||||
" Исключения:\n",
|
||||
" ValueError: Если входная последовательность длиннее max_seq_len\n",
|
||||
" ValueError: Если temperature <= 0\n",
|
||||
" ValueError: Если одновременно заданы top_k и top_p\n",
|
||||
" ValueError: Если top_k задан и ≤ 0\n",
|
||||
" ValueError: Если top_p задан и не в диапазоне (0, 1]\n",
|
||||
"\n",
|
||||
" Примеры:\n",
|
||||
" >>> # Жадная генерация\n",
|
||||
" >>> output = model.generate(input_ids, max_new_tokens=10, do_sample=False)\n",
|
||||
" >>> \n",
|
||||
" >>> # Вероятностная генерация с top-k\n",
|
||||
" >>> output = model.generate(input_ids, max_new_tokens=10, do_sample=True, top_k=50)\n",
|
||||
" >>>\n",
|
||||
" >>> # Nucleus sampling (top-p)\n",
|
||||
" >>> output = model.generate(input_ids, max_new_tokens=10, do_sample=True, top_p=0.9)\n",
|
||||
" >>>\n",
|
||||
" >>> # Комбинация температуры и top-k\n",
|
||||
" >>> output = model.generate(input_ids, max_new_tokens=10, do_sample=True, \n",
|
||||
" ... temperature=0.7, top_k=50)\n",
|
||||
"\n",
|
||||
" Примечания:\n",
|
||||
" 1. Для детерминированных результатов в режиме сэмплирования \n",
|
||||
" зафиксируйте random seed (torch.manual_seed).\n",
|
||||
" 2. Температура влияет только на режим сэмплирования (do_sample=True).\n",
|
||||
" 3. Одновременное использование top_k и top_p запрещено.\n",
|
||||
" 4. При do_sample=False параметры top_k, top_p и temperature игнорируются.\n",
|
||||
"\n",
|
||||
" Args:\n",
|
||||
" x (torch.Tensor): Входной тензор с индексами токенов формы [batch_size, seq_len],\n",
|
||||
" где batch_size - размер батча, seq_len - длина последовательности.\n",
|
||||
" max_new_tokens (int): Максимальное количество новых токенов для генерации.\n",
|
||||
" do_sample (bool): Флаг выбора режима генерации:\n",
|
||||
" - True: вероятностное сэмплирование\n",
|
||||
" - False: жадный поиск (argmax)\n",
|
||||
" temperature (float): Параметр температуры для сэмплирования:\n",
|
||||
" - >1.0 - более случайные результаты\n",
|
||||
" - 1.0 - нейтральное значение\n",
|
||||
" - <1.0 - более предсказуемые результаты\n",
|
||||
" Должна быть > 0 (по умолчанию: 1.0)\n",
|
||||
"\n",
|
||||
" Returns:\n",
|
||||
" torch.Tensor: Тензор с расширенной последовательностью токенов формы \n",
|
||||
" [batch_size, seq_len + max_new_tokens]\n",
|
||||
"\n",
|
||||
" Raises:\n",
|
||||
" ValueError: Если входная последовательность длиннее max_seq_len\n",
|
||||
" ValueError: Если temperature <= 0\n",
|
||||
"\n",
|
||||
" Examples:\n",
|
||||
" >>> # Жадная генерация\n",
|
||||
" >>> output = model.generate(input_ids, max_new_tokens=10, do_sample=False)\n",
|
||||
" >>>\n",
|
||||
" >>> # Вероятностная генерация с температурой\n",
|
||||
" >>> output = model.generate(input_ids, max_new_tokens=10, do_sample=True, temperature=0.7)\n",
|
||||
" >>>\n",
|
||||
" >>> # Более случайная генерация\n",
|
||||
" >>> output = model.generate(input_ids, max_new_tokens=10, do_sample=True, temperature=1.5)\n",
|
||||
"\n",
|
||||
" Note:\n",
|
||||
" Для детерминированных результатов в режиме сэмплирования \n",
|
||||
" зафиксируйте random seed (torch.manual_seed).\n",
|
||||
" Температура влияет только на режим сэмплирования (do_sample=True).\n",
|
||||
" \"\"\"\n",
|
||||
" for _ in range(max_new_tokens):\n",
|
||||
" # 1. Обрезаем вход, если последовательность слишком длинная\n",
|
||||
" x_cond = x[:, -self._max_seq_len:]\n",
|
||||
"\n",
|
||||
" # 2. Передаем последовательность в метод forward класса GPT и полуаем логиты.\n",
|
||||
" logits = self.forward(x_cond)\n",
|
||||
"\n",
|
||||
" # 3. Берем логиты для последнего токена\n",
|
||||
" last_logits = logits[:, -1, :] # [batch_size, vocab_size]\n",
|
||||
"\n",
|
||||
" # Масштабируем логиты температурой\n",
|
||||
" if temperature > 0:\n",
|
||||
" logits_scaled = last_logits / temperature\n",
|
||||
" else:\n",
|
||||
" logits_scaled = last_logits\n",
|
||||
"\n",
|
||||
" if do_sample == True and top_k != None:\n",
|
||||
" _, topk_indices = torch.topk(logits_scaled, top_k, dim=-1)\n",
|
||||
"\n",
|
||||
" # # Заменим все НЕ top-k логиты на -inf\n",
|
||||
" masked_logits = logits_scaled.clone()\n",
|
||||
" vocab_size = logits_scaled.size(-1)\n",
|
||||
"\n",
|
||||
" # создаём маску: True, если токен НЕ в topk_indices\n",
|
||||
" mask = torch.ones_like(logits_scaled, dtype=torch.bool if hasattr(torch, 'bool') else torch.uint8)\n",
|
||||
" mask.scatter_(1, topk_indices, False if hasattr(torch, 'bool') else 0) # False там, где top-k индексы\n",
|
||||
" masked_logits[mask] = float('-inf')\n",
|
||||
"\n",
|
||||
" logits_scaled = masked_logits\n",
|
||||
"\n",
|
||||
" if do_sample == True and top_p != None:\n",
|
||||
" # 1. Применим softmax, чтобы получить вероятности:\n",
|
||||
" probs = F.softmax(logits_scaled, dim=-1) # [B, vocab_size]\n",
|
||||
" # 2. Отсортируем токены по убыванию вероятностей:\n",
|
||||
" sorted_probs, sorted_indices = torch.sort(probs, descending=True, dim=-1)\n",
|
||||
" # 3. Посчитаем кумулятивную сумму вероятностей:\n",
|
||||
" cum_probs = torch.cumsum(sorted_probs, dim=-1) # [B, vocab_size]\n",
|
||||
" # 4. Определим маску: оставить токены, пока сумма < top_p\n",
|
||||
" sorted_mask = (cum_probs <= top_p) # [B, vocab_size]\n",
|
||||
" # Гарантируем, что хотя бы первый токен останется\n",
|
||||
" sorted_mask[:, 0] = True\n",
|
||||
" # 5. Преобразуем маску обратно в оригинальный порядок:\n",
|
||||
" # Создаём полную маску из False\n",
|
||||
" mask = torch.zeros_like(probs, dtype=torch.bool if hasattr(torch, 'bool') else torch.uint8)\n",
|
||||
" # Устанавливаем True в местах нужных токенов\n",
|
||||
" mask.scatter_(dim=1, index=sorted_indices, src=sorted_mask)\n",
|
||||
" # 6. Зануляем логиты токенов вне топ-p:\n",
|
||||
" logits_scaled[~mask] = float('-inf')\n",
|
||||
"\n",
|
||||
" # 4. Применяем Softmax\n",
|
||||
" probs = F.softmax(logits_scaled, dim=-1) # [batch_size, vocab_size]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" if do_sample == True:\n",
|
||||
" # 5. Если do_sample равен True, то отбираем токен случайно с помощью torch.multinomial\n",
|
||||
" next_token = torch.multinomial(probs, num_samples=1) # [batch_size, 1]\n",
|
||||
" else:\n",
|
||||
" # 5. Если do_sample равен False, то выбираем токен с максимальной вероятностью\n",
|
||||
" next_token = torch.argmax(probs, dim=-1, keepdim=True) # [batch_size, 1]\n",
|
||||
" \n",
|
||||
" # 6. Добавляем его к последовательности\n",
|
||||
" x = torch.cat([x, next_token], dim=1) # [batch_size, seq_len+1]\n",
|
||||
" return x\n",
|
||||
"\n",
|
||||
"# def generate(self, input_ids, max_length=50):\n",
|
||||
"# for _ in range(max_length):\n",
|
||||
"# logits = self.forward(input_ids)\n",
|
||||
"# next_token = torch.argmax(logits[:, -1, :], dim=-1, keepdim=True)\n",
|
||||
"# input_ids = torch.cat([input_ids, next_token], dim=1)\n",
|
||||
"# return input_ids\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "303c8f8c",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"name": "python",
|
||||
"version": "3.10.9"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
||||
Reference in New Issue
Block a user