{
"cells": [
{
"cell_type": "markdown",
"id": "efbc675e",
"metadata": {},
"source": [
"# Llama\n",
"\n",
"\n",
"\n",
"\n",
"Llama 1 вышла в феврале 2023 года. Это уже подальше, чем GPT-2. И в ее архитектуре появилось уже больше серьезных изменений:\n",
"\n",
"- Нормализация RMSNorm (вместе с pre-norm).\n",
"- Функция активации SwiGLU.\n",
"- Новый способ кодирования позиций — Rotary Positional Embeddings."
]
},
{
"cell_type": "markdown",
"id": "2cedc663",
"metadata": {},
"source": [
"# RMSNorm\n",
"\n",
"\n",
"\n",
"В Llama используется более быстрая и эффективная нормализация — **RMSNorm (Root Mean Square Normalization)**.\n",
"И, также как в GPT-2, используется *pre-norm* нормализация, то есть слои нормализации располагаются **перед блоками внимания и FNN**.\n",
"\n",
"RMSNorm отличается от обычной нормализации только одним: в нём исключен этап центрирования (вычитание среднего) и используется только масштабирование по RMS.\n",
"Это сокращает вычислительные затраты (на 7–64%) без существенной потери качества.\n",
"На картинке показана разница в распределении после применения RMSNorm и LayerNorm к исходным данным — RMSNorm не разбросан вокруг нуля.\n",
"\n",
"
\n",
" \n",
"
\n",
"\n",
"## Этапы вычисления RMSNorm\n",
"\n",
"1. **Вычисление среднеквадратичного значения:**\n",
"\n",
" $$\\text{RMS}(\\mathbf{x}) = \\sqrt{\\frac{1}{d} \\sum_{j=1}^{d} x_j^2}$$\n",
"\n",
"2. **Нормализация входящего вектора:**\n",
"\n",
" $$\\hat{x}_i = \\frac{x_i}{\\text{RMS}(\\mathbf{x})}$$\n",
"\n",
"3. **Применение масштабирования:**\n",
"\n",
" $$y_i = w_i \\cdot \\hat{x}_i$$\n",
"\n",
"---\n",
"\n",
"**Где:**\n",
"\n",
"* $x_i$ — *i*-й элемент входящего вектора.\n",
"* $w_i$ — *i*-й элемент обучаемого вектора весов.\n",
" Использование весов позволяет модели адаптивно регулировать амплитуду признаков.\n",
" Без них нормализация была бы слишком «жёсткой» и могла бы ограничить качество модели.\n",
"* $d$ — размерность входящего вектора.\n",
"* $\\varepsilon$ — малая константа (например, 1e-6), предотвращает деление на ноль.\n",
"\n",
"---\n",
"\n",
"Так как на вход подаётся тензор, то в векторной форме RMSNorm вычисляется так:\n",
"\n",
"$$\n",
"RMSNorm(x) = w ⊙ \\frac{x}{\\sqrt{mean(x^2) + ϵ}}\n",
"$$\n",
"\n",
"**Где:**\n",
"\n",
"* $x$ — входящий тензор размера `batch_size × ...`\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": 19,
"id": "873704be",
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"from torch import nn\n",
"\n",
"class RMSNorm(nn.Module):\n",
" def __init__(self, dim: int, eps: float = 1e-6):\n",
" super().__init__()\n",
" self._eps = eps\n",
" self._w = nn.Parameter(torch.ones(dim))\n",
" \n",
" def forward(self, x: torch.Tensor): # [batch_size × seq_len × emb_size]\n",
" rms = (x.pow(2).mean(-1, keepdim=True) + self._eps) ** 0.5\n",
" norm_x = x / rms\n",
" return self._w * norm_x"
]
},
{
"cell_type": "markdown",
"id": "09dd9625",
"metadata": {},
"source": [
"# SwiGLU\n",
"\n",
"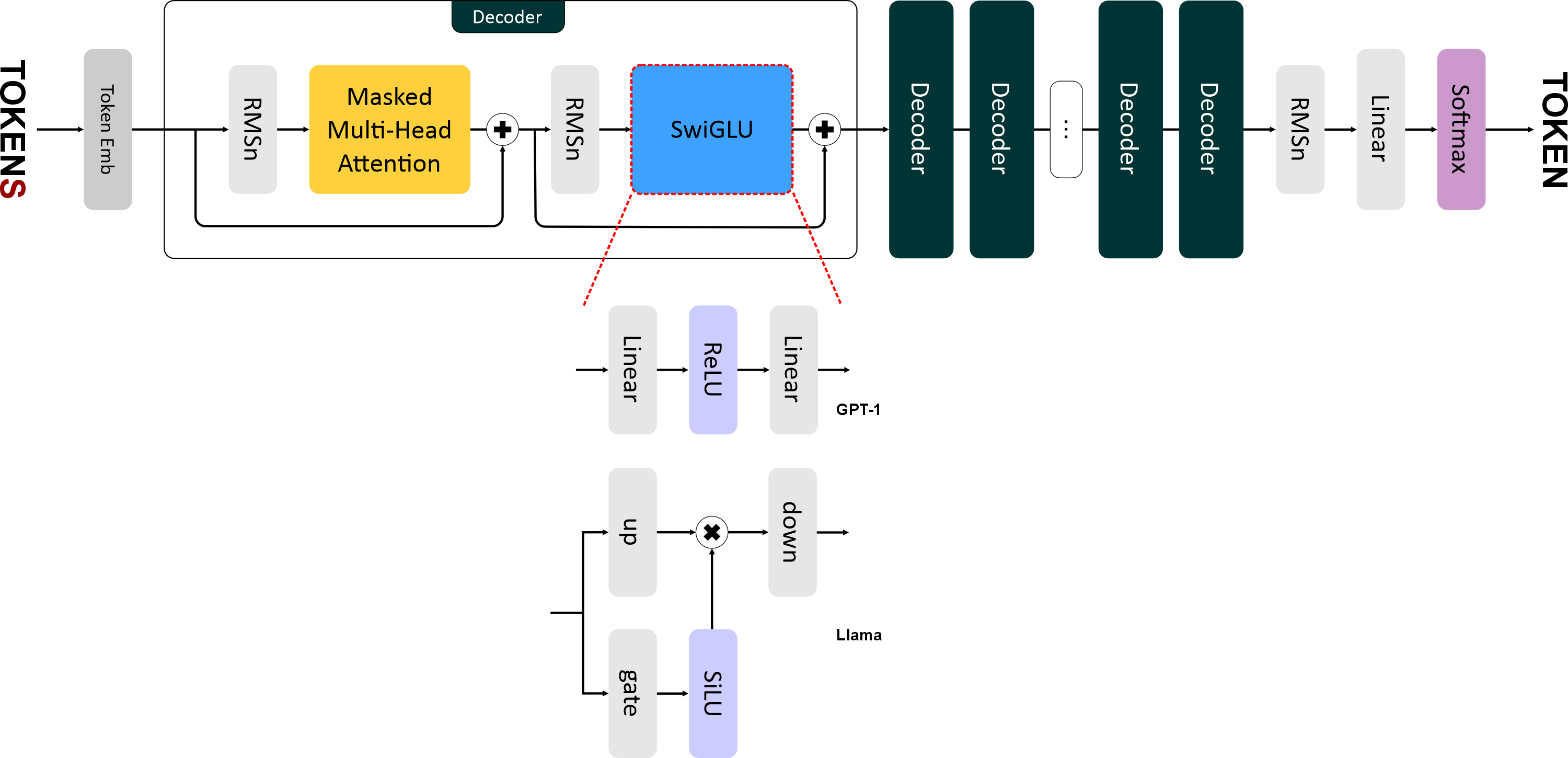\n",
"\n",
"В **Llama** ввели новую функцию активации — **SwiGLU (Swish-Gated Linear Unit)** — это гибридная функция активации, которая представляет собой комбинацию трёх линейных преобразований и функции активации **SiLU (Sigmoid Linear Unit)**, она же *Swish* в терминологии Google.\n",
"\n",
"Формула SwiGLU выглядит так:\n",
"\n",
"$$\n",
"\\text{SwiGLU}(x) = \\text{down}(\\text{SiLU}(\\text{gate}(x)) \\otimes \\text{up}(x))\n",
"$$\n",
"\n",
"где:\n",
"\n",
"* $x$ — входящий тензор.\n",
"* $\\text{gate}(x)$ — линейный слой для гейтового механизма. Преобразует вход `x` размерностью `emb_size` в промежуточное представление размерности `4 * emb_size`.\n",
"* $\\text{up}(x)$ — линейный слой для увеличения размерности. Также преобразует `x` в размерность `4 * emb_size`.\n",
"* $\\text{SiLU}(x) = x \\cdot \\sigma(x)$ — функция активации, где $\\sigma$ — сигмоида.\n",
"* $\\otimes$ — поэлементное умножение.\n",
"* $\\text{down}(x)$ — линейный слой для уменьшения промежуточного представления до исходного размера (`emb_size`).\n",
"\n",
"> **Гейтинг** (от слова *gate* — «врата») — это механизм, который позволяет сети динамически фильтровать, какая информация должна проходить дальше.\n",
"> При гейтинге создаются как бы два независимых потока:\n",
">\n",
"> * один предназначен для прямой передачи информации (*up-down*),\n",
"> * другой — для контроля передаваемой информации (*gate*).\n",
">\n",
"> Это позволяет сети учить более сложные паттерны.\n",
"> Например, гейт может научиться:\n",
"> «если признак A активен, то пропусти признак B»,\n",
"> что невозможно с простой функцией активации между линейными слоями.\n",
">\n",
"> Также гейтинг помогает с затуханием градиентов: вместо простого обнуления (как в ReLU), гейт может тонко модулировать силу сигнала.\n",
"\n",
"SwiGLU более сложная (дорогая), чем ReLU/GELU, так как требует больше вычислений (три линейных преобразования вместо двух).\n",
"Но при этом показывает лучшее качество по сравнению с ReLU и GELU.\n",
"\n",
"График **SiLU** похож на **GELU**, но более гладкий:\n",
"\n",
"
\n",
" \n",
"
\n"
]
},
{
"cell_type": "code",
"execution_count": 20,
"id": "0484cf77",
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"from torch import nn\n",
"import torch.nn.functional as F\n",
"\n",
"class SiLU(nn.Module):\n",
" def forward(self, x: torch.Tensor): # [batch_size × seq_len × emb_size]\n",
" return torch.sigmoid(x) * x"
]
},
{
"cell_type": "markdown",
"id": "0b64da5d",
"metadata": {},
"source": [
"## SwiGLU"
]
},
{
"cell_type": "code",
"execution_count": 21,
"id": "74ca39ba",
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"from torch import nn\n",
"\n",
"class SwiGLU(nn.Module):\n",
" def __init__(self, emb_size: int, dropout: float = 0.1):\n",
" super().__init__()\n",
"\n",
" self._gate = nn.Linear(emb_size, 4 * emb_size)\n",
" self._up = nn.Linear(emb_size, 4 * emb_size)\n",
" self._down = nn.Linear(4 * emb_size, emb_size)\n",
" self._activation = SiLU()\n",
" self._dropout = nn.Dropout(dropout)\n",
"\n",
" def forward(self, x: torch.Tensor): # [batch_size × seq_len × emb_size].\n",
" gate_out = self._gate(x) # [batch, seq, 4*emb]\n",
" activation_out = self._activation(gate_out) # [batch, seq, 4*emb]\n",
" up_out = self._up(x) # [batch, seq, 4*emb]\n",
" out = up_out * activation_out # поэлементное!\n",
" out = self._down(out) # [batch, seq, emb]\n",
" return self._dropout(out)\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"id": "ecd2bcc0",
"metadata": {},
"source": [
"# RoPE\n",
"\n",
"Вот мы и добрались до наиболее серьезного изменения в архитектуре: обычные позиционные эмбеддинги в **Llama** были заменены на **Rotary Positional Embeddings (RoPE)**.\n",
"\n",
"**GPT-1** получал информацию о позициях токенов путем сложения эмбеддингов токенов и позиционных эмбеддингов.\n",
"**RoPE** же кодирует позиции токенов с помощью *вращения (rotation)* векторов **запроса (query)** и **ключа (key)** в двумерном пространстве. При этом каждая позиция в последовательности получает уникальный поворот, а угол поворота зависит от расположения токена в последовательности.\n",
"\n",
"Если упрощенно, то выглядит это так:\n",
"\n",
"* Слово на позиции **1**: поворот на 1°\n",
"* Слово на позиции **2**: поворот на 2°\n",
"* Слово на позиции **100**: поворот на 100°\n",
"* Слово на позиции **101**: поворот на 101°\n",
"\n",
"Угол между 1 и 101 словом будет достаточно большим — **100°**, что отражает большую дистанцию между ними.\n",
"А разница между 100 и 101 словом будет такой же как между 1 и 2, тем самым показывая одинаковую дистанцию между ними.\n",
"\n",
"Такое относительное кодирование позволяет модели лучше понимать расстояние между токенами.\n",
"\n",
"
\n",
" \n",
"
\n",
"\n",
"В последующем тензоры **запроса (query)** и **ключа (key)** перемножаются для вычисления **матрицы внимания**.\n",
"А это означает, что теперь вычисление внимания напрямую зависит от относительных позиций слов.\n",
"\n",
"---\n",
"\n",
"## Почему RoPE лучше\n",
"\n",
"* **Устойчивость к сдвигу:** модель не переобучается на конкретных позициях в обучающих данных, так как учитывает относительные расстояния.\n",
"* **Экономия:** интегрируется в ключи (*key*) и запросы (*query*) посредством матричных вычислений, без необходимости создавать и хранить отдельный слой для позиционных эмбеддингов.\n",
"* **Экстраполяция:** модель может работать с последовательностями длиннее, чем видела при обучении — потому что она выучивает закономерности поворотов в зависимости от дистанции.\n"
]
},
{
"cell_type": "markdown",
"id": "8ba07b89",
"metadata": {},
"source": [
"### Как это работает...\n",
"\n",
"Основная идея: для каждого токена в последовательности его эмбеддинг поворачивается на угол, зависящий от позиции токена и фиксированных частот.\n",
"\n",
"На вход к нам поступают либо тензор ключа (key), либо тензор запроса (query) размерностью `head_size`.\n",
"Обозначим его как *x*.\n",
"\n",
"
\n",
" \n",
"
\n",
"\n",
"Каждая строка в тензоре — это вектор, соответствующий одному токену в последовательности.\n",
"Обозначим вектор как *xₘ*, где *m* — номер позиции токена.\n",
"\n",
"
\n",
" \n",
"
\n",
"\n",
"Вращать вектор мы будем в двумерном пространстве. Но размерность вектора многомерная!\n",
"Чтобы свести вращение к двумерному пространству, вектор разбивают на рядом стоящие пары измерений:\n",
"\n",
"$$\n",
"x_m = [x_{m0}, x_{m1}, x_{m2}, x_{m3}, …, x_{m(d−2)}, x_{m(d−1)}] \\Rightarrow \\text{пары: } (x_{m0}, x_{m1}), (x_{m2}, x_{m3}), …, (x_{m(d−2)}, x_{m(d−1)})\n",
"$$\n",
"\n",
"> Из-за того, что вектор обязательно должен быть разбит на пары, RoPE может работать только для четных `head_size`.\n",
"\n",
"После этого мы можем рассматривать каждую пару\n",
"$(x_{m,2k}; x_{m,2k+1})$\n",
"как вектор в двумерном пространстве:\n",
"\n",
"$$\n",
"\\begin{bmatrix}\n",
"x_{m,2k} \\\n",
"x_{m,2k+1}\n",
"\\end{bmatrix}\n",
"$$\n",
"\n",
"А раз это вектор в двумерном пространстве, то мы можем повернуть его на угол\n",
"$m \\cdot \\theta_k$.\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"id": "c386a55c",
"metadata": {},
"source": []
},
{
"cell_type": "markdown",
"id": "450e03ac",
"metadata": {},
"source": [
"\n",
"\n",
"Каждая пара измерений вектора поворачивается на угол:\n",
"\n",
"$$\n",
"m \\cdot \\theta_k\n",
"$$\n",
"\n",
"