mirror of
https://github.com/pese-git/llm-arch-research.git
synced 2026-01-23 21:10:54 +00:00
1182 lines
47 KiB
Plaintext
1182 lines
47 KiB
Plaintext
{
|
||
"cells": [
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "6842e799",
|
||
"metadata": {},
|
||
"source": [
|
||
"\n",
|
||
"Модель **GPT-1 (Generative Pretrained Transformer)** — это первая реализация идеи создания языковой модели на основе архитектуры **Transformer Decoder**, предложенной в работе *“Improving Language Understanding by Generative Pre-Training”* (OpenAI, 2018).\n",
|
||
"Она заложила фундамент всех последующих поколений GPT-моделей, показав, что модель, обученная на большом корпусе текстов в режиме **предсказания следующего токена**, способна эффективно адаптироваться к различным задачам обработки естественного языка."
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 1,
|
||
"id": "a4fba924",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"import dill\n",
|
||
"from torch import nn\n",
|
||
"import torch"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "6ed35205",
|
||
"metadata": {},
|
||
"source": [
|
||
"## BPE Tokenizator"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 2,
|
||
"id": "1a6f2914",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"class BPE:\n",
|
||
" def __init__(self, vocab_size: int):\n",
|
||
" self.vocab_size = vocab_size\n",
|
||
" self.id2token = {}\n",
|
||
" self.token2id = {}\n",
|
||
"\n",
|
||
" def fit(self, text: str):\n",
|
||
" # 1. Получаем уникальные токены (символы)\n",
|
||
" unique_tokens = sorted(set(text))\n",
|
||
" tokens = unique_tokens.copy()\n",
|
||
"\n",
|
||
" # 2. Разбиваем текст на токены-символы\n",
|
||
" sequence = list(text)\n",
|
||
"\n",
|
||
" # 3. Объединяем токены до достижения нужного размера словаря\n",
|
||
" while len(tokens) < self.vocab_size:\n",
|
||
" #print(f'len={len(tokens)} < {self.vocab_size}')\n",
|
||
" # Считаем частоты пар\n",
|
||
" pair_freq = {}\n",
|
||
" for i in range(len(sequence) - 1):\n",
|
||
" pair = (sequence[i], sequence[i + 1])\n",
|
||
" #print(f'pair = {pair}')\n",
|
||
" if pair not in pair_freq:\n",
|
||
" pair_freq[pair] = 0\n",
|
||
" pair_freq[pair] += 1\n",
|
||
"\n",
|
||
"\n",
|
||
" #print(f'pair_freq = {pair_freq}') \n",
|
||
" if not pair_freq:\n",
|
||
" break # нет пар — выходим\n",
|
||
"\n",
|
||
" #for x in pair_freq.items():\n",
|
||
" # self.debug(x, sequence)\n",
|
||
"\n",
|
||
" # Находим самую частую пару (в случае равенства — та, что встретилась первой)\n",
|
||
" most_frequent_pair = max(pair_freq.items(), key=lambda x: (x[1], -self._pair_first_index(sequence, x[0])))[0]\n",
|
||
" #print(most_frequent_pair)\n",
|
||
" # Создаем новый токен\n",
|
||
" new_token = most_frequent_pair[0] + most_frequent_pair[1]\n",
|
||
" #print(f\"new token={new_token}\")\n",
|
||
" tokens.append(new_token)\n",
|
||
" #print(f\"tokens={tokens}\")\n",
|
||
"\n",
|
||
" i = 0\n",
|
||
" new_sequence = []\n",
|
||
"\n",
|
||
" while i < len(sequence):\n",
|
||
" if i < len(sequence) - 1 and (sequence[i], sequence[i + 1]) == most_frequent_pair:\n",
|
||
" new_sequence.append(new_token)\n",
|
||
" i += 2 # пропускаем два символа — заменённую пару\n",
|
||
" else:\n",
|
||
" new_sequence.append(sequence[i])\n",
|
||
" i += 1\n",
|
||
" sequence = new_sequence\n",
|
||
" #break\n",
|
||
" \n",
|
||
" # 4. Создаем словари\n",
|
||
" self.vocab = tokens.copy()\n",
|
||
" self.token2id = dict(zip(tokens, range(self.vocab_size)))\n",
|
||
" self.id2token = dict(zip(range(self.vocab_size), tokens))\n",
|
||
"\n",
|
||
" def _pair_first_index(self, sequence, pair):\n",
|
||
" for i in range(len(sequence) - 1):\n",
|
||
" if (sequence[i], sequence[i + 1]) == pair:\n",
|
||
" return i\n",
|
||
" return float('inf') # если пара не найдена (в теории не должно случиться)\n",
|
||
"\n",
|
||
"\n",
|
||
" def encode(self, text: str):\n",
|
||
" # 1. Разбиваем текст на токены-символы\n",
|
||
" sequence = list(text)\n",
|
||
" # 2. Инициализация пустого списка токенов\n",
|
||
" tokens = []\n",
|
||
" # 3. Установить i = 0\n",
|
||
" i = 0\n",
|
||
" while i < len(text):\n",
|
||
" # 3.1 Найти все токены в словаре, начинающиеся с text[i]\n",
|
||
" start_char = text[i]\n",
|
||
" result = [token for token in self.vocab if token.startswith(start_char)]\n",
|
||
" # 3.2 Выбрать самый длинный подходящий токен\n",
|
||
" find_token = self._find_max_matching_token(text[i:], result)\n",
|
||
" if find_token is None:\n",
|
||
" # Обработка неизвестного символа\n",
|
||
" tokens.append(text[i]) # Добавляем сам символ как токен\n",
|
||
" i += 1\n",
|
||
" else:\n",
|
||
" # 3.3 Добавить токен в результат\n",
|
||
" tokens.append(find_token)\n",
|
||
" # 3.4 Увеличить i на длину токена\n",
|
||
" i += len(find_token)\n",
|
||
"\n",
|
||
" # 4. Заменить токены на их ID\n",
|
||
" return self._tokens_to_ids(tokens)\n",
|
||
"\n",
|
||
" def _find_max_matching_token(self, text: str, tokens: list):\n",
|
||
" \"\"\"Находит самый длинный токен из списка, с которого начинается текст\"\"\"\n",
|
||
" matching = [token for token in tokens if text.startswith(token)]\n",
|
||
" return max(matching, key=len) if matching else None\n",
|
||
"\n",
|
||
" def _tokens_to_ids(self, tokens):\n",
|
||
" \"\"\"Конвертирует список токенов в их ID с обработкой неизвестных токенов\"\"\"\n",
|
||
" ids = []\n",
|
||
" for token in tokens:\n",
|
||
" if token in self.token2id:\n",
|
||
" ids.append(self.token2id[token])\n",
|
||
" else:\n",
|
||
" ids.append(0) # Специальное значение\n",
|
||
" return ids\n",
|
||
"\n",
|
||
"\n",
|
||
" def decode(self, ids: list) -> str:\n",
|
||
" return ''.join(self._ids_to_tokens(ids))\n",
|
||
"\n",
|
||
" def _ids_to_tokens(self, ids: list) -> list:\n",
|
||
" \"\"\"Конвертирует список Ids в их tokens\"\"\"\n",
|
||
" tokens = []\n",
|
||
" for id in ids:\n",
|
||
" if id in self.id2token:\n",
|
||
" tokens.append(self.id2token[id])\n",
|
||
" else:\n",
|
||
" tokens.append('') # Специальное значение\n",
|
||
" return tokens\n",
|
||
"\n",
|
||
"\n",
|
||
" def save(self, filename):\n",
|
||
" with open(filename, 'wb') as f:\n",
|
||
" dill.dump(self, f)\n",
|
||
" print(f\"Объект сохранён в {filename}\")\n",
|
||
"\n",
|
||
"\n",
|
||
" @classmethod\n",
|
||
" def load(cls, filename):\n",
|
||
" with open(filename, 'rb') as f:\n",
|
||
" obj = dill.load(f)\n",
|
||
" \n",
|
||
" print(f\"Объект загружен из {filename}\")\n",
|
||
" return obj"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "ef121b7b",
|
||
"metadata": {},
|
||
"source": [
|
||
"# Архитектура GPT-1: Принципы работы и ключевые компоненты\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"Модель **GPT-1 (Generative Pretrained Transformer)** — это первая версия архитектуры семейства GPT, основанная на **декодере трансформера**. \n",
|
||
"Она была представлена исследователями **OpenAI** в 2018 году и стала основой для всех последующих моделей, включая GPT-2, GPT-3 и GPT-4. \n",
|
||
"\n",
|
||
"Главная идея GPT-1 заключается в том, что модель можно обучить **понимать и генерировать текст**, если она научится предсказывать **следующий токен** в последовательности. \n",
|
||
"Этот простой принцип позволил создать универсальную языковую модель, способную решать множество задач без ручного проектирования под каждую из них.\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "47d11c5c",
|
||
"metadata": {},
|
||
"source": [
|
||
"## 1. Эмбеддинги (Embeddings)\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"Перед тем как текст подается в трансформер, его необходимо преобразовать в числовое представление. \n",
|
||
"Это делается с помощью **эмбеддингов** — плотных векторов, которые кодируют смысл и структуру слов.\n",
|
||
"\n",
|
||
"GPT использует два типа эмбеддингов:"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "e046ecc8",
|
||
"metadata": {},
|
||
"source": [
|
||
"### 1.1 Token Embeddings\n",
|
||
"\n",
|
||
"Каждое слово или подслово сначала токенизируется и преобразуется в уникальный числовой идентификатор. \n",
|
||
"Затем этот идентификатор сопоставляется с вектором фиксированной длины — **эмбеддингом токена**. \n",
|
||
"\n",
|
||
"Вектор можно рассматривать как координаты слова в многомерном пространстве смыслов: токены, близкие по значению, располагаются рядом.\n",
|
||
"\n",
|
||
"Формально:\n",
|
||
"$$\n",
|
||
"E_{token}(t_i) = W_e[t_i]\n",
|
||
"$$\n",
|
||
"\n",
|
||
"где \n",
|
||
"$W_e$ — обучаемая матрица эмбеддингов (размером `vocab_size × d_model`), \n",
|
||
"$t_i$ — индекс токена в словаре."
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 3,
|
||
"id": "1464a012",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"class TokenEmbeddings(nn.Module):\n",
|
||
" def __init__(self, vocab_size: int, emb_size: int):\n",
|
||
" super().__init__()\n",
|
||
" self._embedding = nn.Embedding(\n",
|
||
" num_embeddings=vocab_size,\n",
|
||
" embedding_dim=emb_size,\n",
|
||
" padding_idx=0 # чтобы 0 можно было безопасно использовать\n",
|
||
" )\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor) -> torch.Tensor:\n",
|
||
" return self._embedding(x)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "a7e6025b",
|
||
"metadata": {},
|
||
"source": [
|
||
"### 1.2 Positional Embeddings\n",
|
||
"\n",
|
||
"Архитектура трансформера не учитывает порядок слов, так как внимание обрабатывает все токены параллельно. \n",
|
||
"Чтобы сохранить последовательность, вводятся **позиционные эмбеддинги**, которые добавляют информацию о позиции каждого токена.\n",
|
||
"\n",
|
||
"В GPT-1 используются **синусоиды фиксированной формы**:\n",
|
||
"$$\n",
|
||
"PE_{(pos, 2i)} = \\sin\\left(\\frac{pos}{10000^{2i/d_{model}}}\\right), \\quad\n",
|
||
"PE_{(pos, 2i+1)} = \\cos\\left(\\frac{pos}{10000^{2i/d_{model}}}\\right)\n",
|
||
"$$\n",
|
||
"\n",
|
||
"Окончательное представление токена:\n",
|
||
"$$\n",
|
||
"x_i = E_{token}(t_i) + PE(pos_i)\n",
|
||
"$$"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 4,
|
||
"id": "94ddd50d",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"class PositionEmbeddings(nn.Module):\n",
|
||
" def __init__(self, max_seq_len: int, emb_size: int):\n",
|
||
" super().__init__()\n",
|
||
" self.max_seq_len = max_seq_len\n",
|
||
" self.emb_size = emb_size\n",
|
||
" self.embedding = nn.Embedding(\n",
|
||
" num_embeddings=max_seq_len,\n",
|
||
" embedding_dim=emb_size\n",
|
||
" )\n",
|
||
"\n",
|
||
" def forward(self, seq_len: int) -> torch.Tensor:\n",
|
||
" if seq_len < 1 or seq_len > self.max_seq_len:\n",
|
||
" raise IndexError(f\"Длина {seq_len} должна быть от 1 до {self.max_seq_len}\")\n",
|
||
" positions = torch.arange(seq_len, device=self.embedding.weight.device)\n",
|
||
" return self.embedding(positions)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "5b04dff2",
|
||
"metadata": {},
|
||
"source": [
|
||
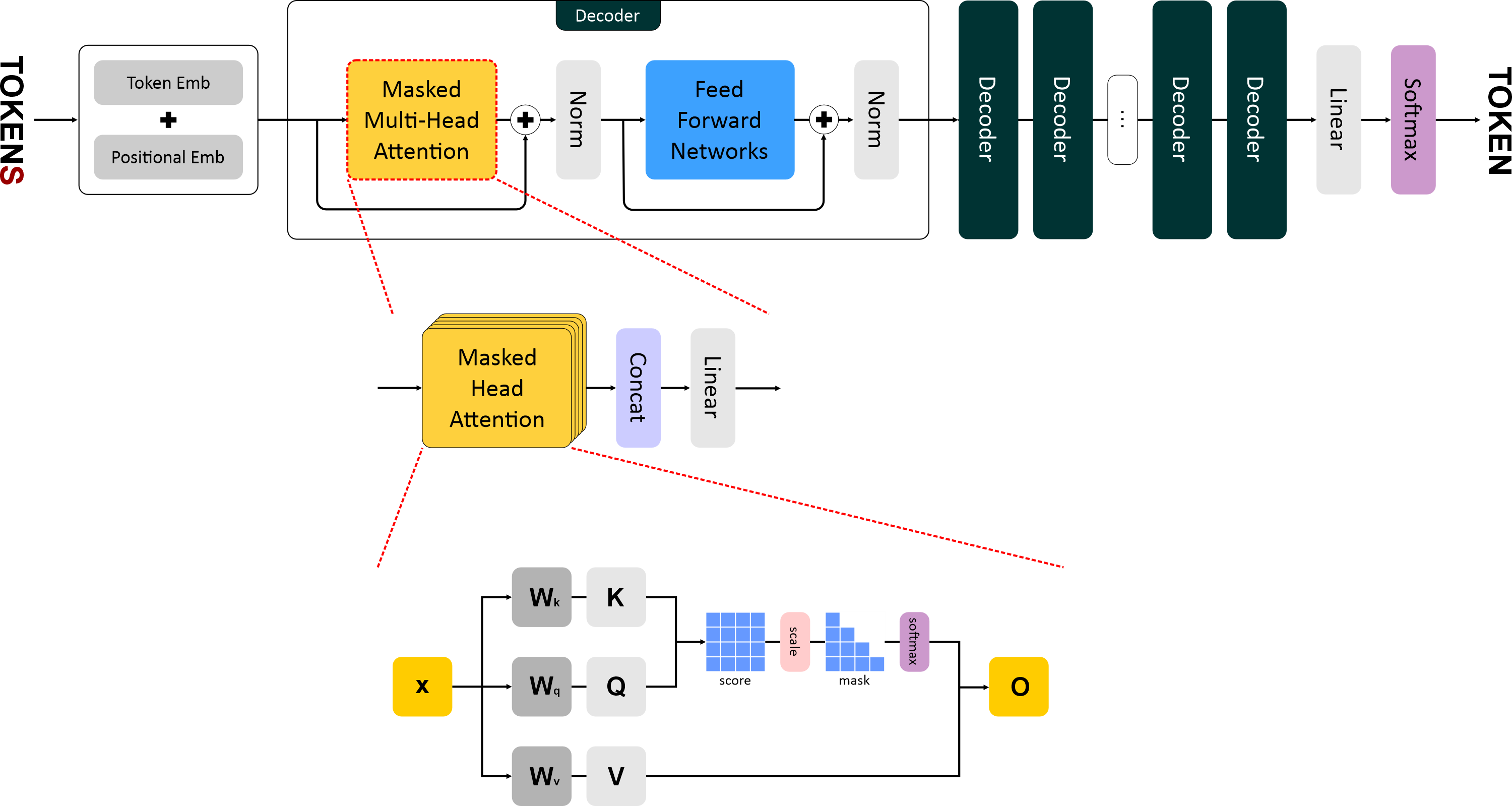
"## 2. Внимание (Attention)\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"Механизм внимания — ключевая идея трансформеров. \n",
|
||
"Он позволяет модели **взвешивать важность других токенов** при обработке текущего, то есть решать, на какие слова нужно обратить внимание при генерации следующего.\n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 2.1 Матрица внимания\n",
|
||
"\n",
|
||
"Каждому токену сопоставляются три обучаемых вектора:\n",
|
||
"- **Query (Q)** — запрос: что текущий токен ищет в других;\n",
|
||
"- **Key (K)** — ключ: какую информацию несет токен;\n",
|
||
"- **Value (V)** — значение: само содержимое токена.\n",
|
||
"\n",
|
||
"Эти векторы вычисляются линейными преобразованиями входных эмбеддингов:\n",
|
||
"$$\n",
|
||
"Q = XW_Q, \\quad K = XW_K, \\quad V = XW_V\n",
|
||
"$$\n",
|
||
"\n",
|
||
"Затем вычисляется **взвешенное внимание**:\n",
|
||
"$$\n",
|
||
"\\text{Attention}(Q, K, V) = \\text{softmax}\\left(\\frac{QK^T}{\\sqrt{d_k}}\\right)V\n",
|
||
"$$\n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 2.2 Матричные операции\n",
|
||
"\n",
|
||
"- $QK^T$ — матрица сходства между токенами; \n",
|
||
"- деление на $\\sqrt{d_k}$ стабилизирует градиенты; \n",
|
||
"- **softmax** превращает оценки в вероятности; \n",
|
||
"- умножение результата на $V$ даёт взвешенные представления токенов.\n",
|
||
"\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 5,
|
||
"id": "8fe8d3bb",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"class HeadAttention(nn.Module):\n",
|
||
" def __init__(self, emb_size: int, head_size: int, max_seq_len: int):\n",
|
||
" super().__init__()\n",
|
||
" self._emb_size = emb_size\n",
|
||
" self._head_size = head_size\n",
|
||
" self._max_seq_len = max_seq_len\n",
|
||
"\n",
|
||
" # Линейные преобразования для Q, K, V\n",
|
||
" self._k = nn.Linear(emb_size, head_size)\n",
|
||
" self._q = nn.Linear(emb_size, head_size)\n",
|
||
" self._v = nn.Linear(emb_size, head_size)\n",
|
||
"\n",
|
||
" # Создание causal маски\n",
|
||
" mask = torch.tril(torch.ones(max_seq_len, max_seq_len))\n",
|
||
" self.register_buffer('_tril_mask', mask.bool() if hasattr(torch, 'bool') else mask.byte())\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor) -> torch.Tensor:\n",
|
||
" seq_len = x.shape[1]\n",
|
||
" if seq_len > self._max_seq_len:\n",
|
||
" raise ValueError(f\"Длина последовательности {seq_len} превышает максимум {self._max_seq_len}\")\n",
|
||
"\n",
|
||
" # 1. Линейные преобразования\n",
|
||
" k = self._k(x) # [B, T, hs]\n",
|
||
" q = self._q(x) # [B, T, hs]\n",
|
||
" \n",
|
||
" # 2. Вычисление scores\n",
|
||
" scores = q @ k.transpose(-2, -1) / self._head_size ** 0.5\n",
|
||
" \n",
|
||
" # 3. Применение causal маски\n",
|
||
" scores = scores.masked_fill(~self._tril_mask[:seq_len, :seq_len], float('-inf'))\n",
|
||
" \n",
|
||
" # 4. Softmax и умножение на V\n",
|
||
" weights = F.softmax(scores, dim=-1)\n",
|
||
" return weights @ self._v(x)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "a920fbcf",
|
||
"metadata": {},
|
||
"source": [
|
||
"### 2.3 Мультихед (Multi-Head Attention)\n",
|
||
"\n",
|
||
"Вместо одной операции внимания GPT-1 использует несколько параллельных **голов внимания**. \n",
|
||
"Каждая голова фокусируется на различных аспектах контекста — синтаксисе, семантике или долгосрочных зависимостях.\n",
|
||
"\n",
|
||
"$$\n",
|
||
"\\text{MultiHead}(Q, K, V) = \\text{Concat}(\\text{head}_1, \\dots, \\text{head}_h)W_O\n",
|
||
"$$\n",
|
||
"\n",
|
||
"где каждая голова:\n",
|
||
"$$\n",
|
||
"\\text{head}_i = \\text{Attention}(QW_{Qi}, KW_{Ki}, VW_{Vi})\n",
|
||
"$$\n",
|
||
"\n",
|
||
"В GPT-1 используется **12 голов**, что обеспечивает богатое контекстное восприятие текста."
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 6,
|
||
"id": "d55276a9",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"\n",
|
||
"class MultiHeadAttention(nn.Module):\n",
|
||
" def __init__(self, num_heads: int, emb_size: int, head_size: int, max_seq_len: int, dropout: float = 0.1):\n",
|
||
" super().__init__()\n",
|
||
" self._heads = nn.ModuleList([\n",
|
||
" HeadAttention(\n",
|
||
" emb_size=emb_size, \n",
|
||
" head_size=head_size, \n",
|
||
" max_seq_len=max_seq_len\n",
|
||
" ) for _ in range(num_heads)\n",
|
||
" ])\n",
|
||
" self._layer = nn.Linear(head_size * num_heads, emb_size)\n",
|
||
" self._dropout = nn.Dropout(dropout)\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor, mask: torch.Tensor = None):\n",
|
||
" # 1. Вычисляем attention для каждой головы\n",
|
||
" attention_outputs = [head(x) for head in self._heads]\n",
|
||
" \n",
|
||
" # 2. Объединяем результаты всех голов\n",
|
||
" concatenated_attention = torch.cat(attention_outputs, dim=-1)\n",
|
||
" \n",
|
||
" # 3. Проецируем в пространство эмбеддингов\n",
|
||
" projected_output = self._layer(concatenated_attention)\n",
|
||
" \n",
|
||
" # 4. Применяем dropout для регуляризации\n",
|
||
" final_output = self._dropout(projected_output)\n",
|
||
" \n",
|
||
" return final_output"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "3ffafb56",
|
||
"metadata": {},
|
||
"source": [
|
||
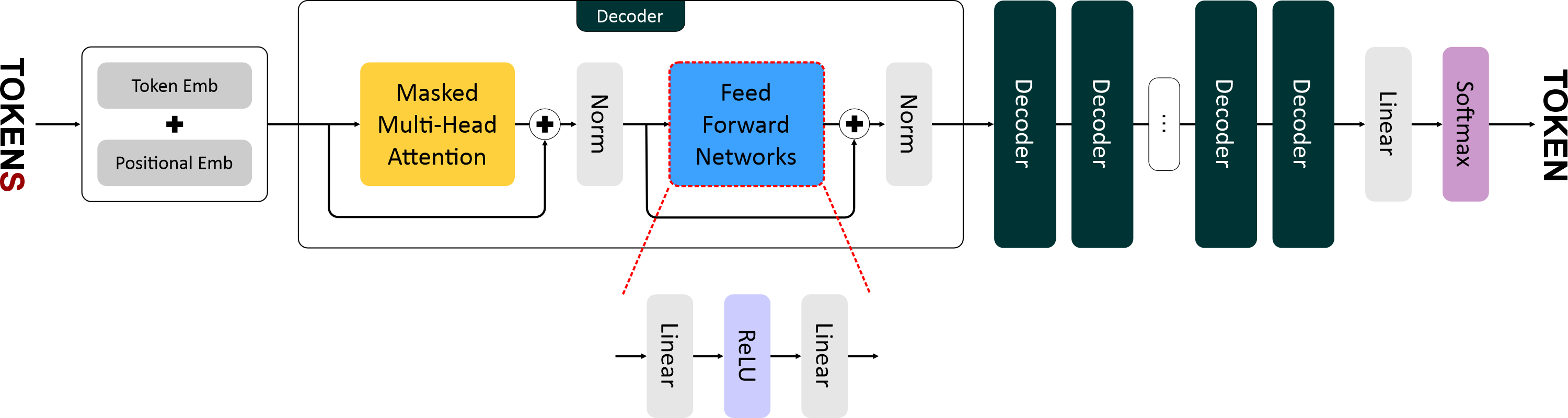
"## 3. Feed Forward Network (FFN)\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"После блока внимания каждый токен независимо проходит через двухслойную нейронную сеть — **Feed Forward Network**. \n",
|
||
"Она добавляет модели способность нелинейно преобразовывать информацию.\n",
|
||
"\n",
|
||
"$$\n",
|
||
"\\text{FFN}(x) = \\max(0, xW_1 + b_1)W_2 + b_2\n",
|
||
"$$\n",
|
||
"\n",
|
||
"Используется активация **ReLU**. \n",
|
||
"FFN применяется одинаково к каждому токену и не зависит от порядка слов, что делает вычисления высокопараллельными.\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 7,
|
||
"id": "84f57562",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"class FeedForward(nn.Module):\n",
|
||
" def __init__(self, emb_size: int, dropout: float = 0.1):\n",
|
||
" super().__init__()\n",
|
||
" self.net = nn.Sequential(\n",
|
||
" nn.Linear(emb_size, 4 * emb_size),\n",
|
||
" nn.ReLU(),\n",
|
||
" nn.Linear(4 * emb_size, emb_size),\n",
|
||
" nn.Dropout(dropout)\n",
|
||
" )\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor):\n",
|
||
" self.net = self.net.to(x.dtype)\n",
|
||
" return self.net(x)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "8d9ce9d8",
|
||
"metadata": {},
|
||
"source": [
|
||
"## 4. Блок Декодера\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"Каждый слой GPT-1 — это **декодер**, состоящий из следующих элементов:\n",
|
||
"\n",
|
||
"1. **Masked Multi-Head Attention** \n",
|
||
" Маска запрещает токену видеть будущие позиции, чтобы сохранить авторегрессионное направление генерации (слева направо).\n",
|
||
"\n",
|
||
"2. **Остаточные связи + Layer Normalization** \n",
|
||
" Результат внимания складывается с входом слоя, а затем нормализуется: \n",
|
||
" $$\n",
|
||
" x' = \\text{LayerNorm}(x + \\text{Attention}(x))\n",
|
||
" $$\n",
|
||
"\n",
|
||
"3. **Feed Forward + Residual + LayerNorm** \n",
|
||
" $$\n",
|
||
" y = \\text{LayerNorm}(x' + \\text{FFN}(x'))\n",
|
||
" $$\n",
|
||
"\n",
|
||
"GPT-1 содержит **12 таких блоков**, соединённых последовательно."
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 8,
|
||
"id": "300acc96",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"class Decoder(nn.Module):\n",
|
||
" def __init__(self, \n",
|
||
" num_heads: int,\n",
|
||
" emb_size: int,\n",
|
||
" head_size: int,\n",
|
||
" max_seq_len: int,\n",
|
||
" dropout: float = 0.1\n",
|
||
" ):\n",
|
||
" super().__init__()\n",
|
||
" self._heads = MultiHeadAttention(\n",
|
||
" num_heads=num_heads, \n",
|
||
" emb_size=emb_size, \n",
|
||
" head_size=head_size, \n",
|
||
" max_seq_len=max_seq_len, \n",
|
||
" dropout=dropout\n",
|
||
" )\n",
|
||
" self._ff = FeedForward(\n",
|
||
" emb_size=emb_size, \n",
|
||
" dropout=dropout\n",
|
||
" )\n",
|
||
" self._norm1 = nn.LayerNorm(emb_size)\n",
|
||
" self._norm2 = nn.LayerNorm(emb_size)\n",
|
||
" #self._dropout_attn = nn.Dropout(dropout)\n",
|
||
" #self._dropout_ffn = nn.Dropout(dropout)\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor, mask: torch.Tensor = None):\n",
|
||
" # Приведение типов параметров\n",
|
||
" self._heads = self._heads.to(x.dtype)\n",
|
||
" self._ff = self._ff.to(x.dtype)\n",
|
||
" \n",
|
||
" # Пропустим тензор x через экземпляр MultiHeadAttention.\n",
|
||
" attention = self._heads(x, mask)\n",
|
||
" #attention = self._dropout_attn(attention)\n",
|
||
" \n",
|
||
" # Выходной тензор из блока внимания сложим с исходным x.\n",
|
||
" out = attention + x\n",
|
||
" \n",
|
||
" # Получившийся тензор пропустим через первый слой нормализации.\n",
|
||
" norm_out = self._norm1(out)\n",
|
||
" \n",
|
||
" # Затем подадим его на вход экземпляру FFN.\n",
|
||
" ffn_out = self._ff(norm_out)\n",
|
||
" #ffn_out = self._dropout_ffn(ffn_out)\n",
|
||
" \n",
|
||
" # Выходной тензор из FFN сложим с тем, что поступил на вход.\n",
|
||
" out = ffn_out + norm_out\n",
|
||
" \n",
|
||
" # Пропустим получившийся тензор через второй слой нормализации.\n",
|
||
" norm_out = self._norm2(out)\n",
|
||
" \n",
|
||
" # Вернем итоговый тензор размером batch_size x seq_len x emb_size.\n",
|
||
" return norm_out"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "888d1a1c",
|
||
"metadata": {},
|
||
"source": [
|
||
"## 5. Обучение GPT-1\n",
|
||
"\n",
|
||
"GPT-1 обучается в два этапа:\n",
|
||
"\n",
|
||
"- 1️⃣ **Предобучение (Unsupervised Pretraining)** \n",
|
||
"- 2️⃣ **Дообучение (Supervised Fine-Tuning)**\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 9,
|
||
"id": "0eb26ef3",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"class GPT(nn.Module):\n",
|
||
" \"\"\"GPT-like трансформер для генерации текста\n",
|
||
" \n",
|
||
" Args:\n",
|
||
" vocab_size: Размер словаря\n",
|
||
" max_seq_len: Макс. длина последовательности\n",
|
||
" emb_size: Размерность эмбеддингов\n",
|
||
" num_heads: Количество голов внимания\n",
|
||
" head_size: Размерность голов внимания\n",
|
||
" num_layers: Количество слоёв декодера\n",
|
||
" dropout: Вероятность dropout (default=0.1)\n",
|
||
" device: Устройство (default='cpu')\n",
|
||
" \"\"\"\n",
|
||
" def __init__(self,\n",
|
||
" vocab_size: int,\n",
|
||
" max_seq_len: int,\n",
|
||
" emb_size: int,\n",
|
||
" num_heads: int,\n",
|
||
" head_size: int,\n",
|
||
" num_layers: int,\n",
|
||
" dropout: float = 0.1,\n",
|
||
" device: str = 'cpu'\n",
|
||
" ):\n",
|
||
" super().__init__()\n",
|
||
" self.device = device\n",
|
||
" self.max_seq_len = max_seq_len\n",
|
||
" \n",
|
||
" # Инициализация слоев\n",
|
||
" self._token_embeddings = TokenEmbeddings(\n",
|
||
" vocab_size=vocab_size, \n",
|
||
" emb_size=emb_size\n",
|
||
" )\n",
|
||
" self._position_embeddings = PositionEmbeddings(\n",
|
||
" max_seq_len=max_seq_len, \n",
|
||
" emb_size=emb_size\n",
|
||
" )\n",
|
||
" self._dropout = nn.Dropout(dropout)\n",
|
||
" self._decoders = nn.ModuleList([Decoder(\n",
|
||
" num_heads=num_heads,\n",
|
||
" emb_size=emb_size,\n",
|
||
" head_size=head_size,\n",
|
||
" max_seq_len=max_seq_len,\n",
|
||
" dropout=dropout \n",
|
||
" ) for _ in range(num_layers)])\n",
|
||
" self._linear = nn.Linear(emb_size, vocab_size)\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor) -> torch.Tensor:\n",
|
||
" \"\"\"Прямой проход через GPT\n",
|
||
" \n",
|
||
" Args:\n",
|
||
" x: Входной тензор [batch_size, seq_len]\n",
|
||
" \n",
|
||
" Returns:\n",
|
||
" Тензор логитов [batch_size, seq_len, vocab_size]\n",
|
||
" \"\"\"\n",
|
||
" # Проверка длины последовательности\n",
|
||
" if x.size(1) > self.max_seq_len:\n",
|
||
" raise ValueError(f\"Длина последовательности {x.size(1)} превышает максимальную {self.max_seq_len}\")\n",
|
||
" \n",
|
||
" # Эмбеддинги токенов и позиций\n",
|
||
" tok_out = self._token_embeddings(x) # [batch, seq_len, emb_size]\n",
|
||
" pos_out = self._position_embeddings(x.size(1)) # [seq_len, emb_size]\n",
|
||
" \n",
|
||
" # Комбинирование\n",
|
||
" out = self._dropout(tok_out + pos_out.unsqueeze(0)) # [batch, seq_len, emb_size]\n",
|
||
" \n",
|
||
" # Стек декодеров\n",
|
||
" for decoder in self._decoders:\n",
|
||
" out = decoder(out)\n",
|
||
" \n",
|
||
" return self._linear(out) # [batch, seq_len, vocab_size]\n",
|
||
"\n",
|
||
" def generate(self, x: torch.Tensor, max_new_tokens: int):\n",
|
||
" for _ in range(max_new_tokens):\n",
|
||
" # 1. Обрезаем вход, если последовательность слишком длинная\n",
|
||
" x_cond = x[:, -self.max_seq_len:]\n",
|
||
"\n",
|
||
" # 2. Передаем последовательность в метод forward класса GPT и полуаем логиты.\n",
|
||
" logits = self.forward(x_cond)\n",
|
||
"\n",
|
||
" # 3. Берем логиты для последнего токена\n",
|
||
" last_logits = logits[:, -1, :] # [batch_size, vocab_size]\n",
|
||
"\n",
|
||
" # 4. Применяем Softmax\n",
|
||
" probs = F.softmax(last_logits, dim=-1) # [batch_size, vocab_size]\n",
|
||
"\n",
|
||
" # 5. Выбираем токен с максимальной вероятностью\n",
|
||
" next_token = torch.argmax(probs, dim=-1, keepdim=True) # [batch_size, 1]\n",
|
||
"\n",
|
||
" # 6. Добавляем его к последовательности\n",
|
||
" x = torch.cat([x, next_token], dim=1) # [batch_size, seq_len+1] \n",
|
||
" return x"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "b47966ba",
|
||
"metadata": {},
|
||
"source": [
|
||
"\n",
|
||
"\n",
|
||
"### 5.1 Предобучение\n",
|
||
"\n",
|
||
"На первом этапе модель обучается без разметки: она получает большой корпус текстов и учится **предсказывать следующий токен** по предыдущим.\n",
|
||
"\n",
|
||
"Функция потерь:\n",
|
||
"$$\n",
|
||
"L = - \\sum_{t=1}^{T} \\log P(x_t | x_1, x_2, ..., x_{t-1})\n",
|
||
"$$\n",
|
||
"\n",
|
||
"Таким образом, модель учится строить вероятностную модель языка, \"угадывая\" продолжение текста.\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "12e4624e",
|
||
"metadata": {},
|
||
"source": [
|
||
"Во время **предобучения** GPT-1 учится **предсказывать следующий токен** (language modeling task). \n",
|
||
"Формально: \n",
|
||
"$$ \n",
|
||
"P(x_t ,|, x_1, x_2, \\dots, x_{t-1}) \n",
|
||
"$$ \n",
|
||
"То есть, если на вход подаётся предложение `\"I love deep\"`, модель должна предсказать `\"learning\"`.\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "87dcc10e",
|
||
"metadata": {},
|
||
"source": [
|
||
"### ✅ 5.1.1 Подготовка данных\n",
|
||
"\n",
|
||
"Создадим **датасет** на основе BPE-токенизатора:"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 10,
|
||
"id": "632eec77",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"import torch\n",
|
||
"from torch.utils.data import Dataset, DataLoader\n",
|
||
"\n",
|
||
"class GPTDataset(Dataset):\n",
|
||
" def __init__(self, text: str, bpe: BPE, block_size: int):\n",
|
||
" self.bpe = bpe\n",
|
||
" self.block_size = block_size\n",
|
||
" self.data = bpe.encode(text)\n",
|
||
" \n",
|
||
" def __len__(self):\n",
|
||
" return len(self.data) - self.block_size\n",
|
||
"\n",
|
||
" def __getitem__(self, idx):\n",
|
||
" x = torch.tensor(self.data[idx:idx+self.block_size], dtype=torch.long)\n",
|
||
" y = torch.tensor(self.data[idx+1:idx+self.block_size+1], dtype=torch.long)\n",
|
||
" return x, y"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "bb5d83d8",
|
||
"metadata": {},
|
||
"source": [
|
||
"- `x` — входная последовательность токенов\n",
|
||
" \n",
|
||
"- `y` — та же последовательность, но сдвинутая на один токен вперёд (цель)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "24de37be",
|
||
"metadata": {},
|
||
"source": [
|
||
"### ✅ 5.1.2 Цикл обучения\n",
|
||
"\n",
|
||
"Для обучения создадим функцию:"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 11,
|
||
"id": "8003ea24",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"import torch.nn.functional as F\n",
|
||
"from torch import optim\n",
|
||
"\n",
|
||
"def train_gpt(model, dataset, epochs=5, batch_size=32, lr=3e-4, device='cpu'):\n",
|
||
" dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)\n",
|
||
" optimizer = optim.AdamW(model.parameters(), lr=lr)\n",
|
||
"\n",
|
||
" model.to(device)\n",
|
||
" model.train()\n",
|
||
"\n",
|
||
" for epoch in range(epochs):\n",
|
||
" total_loss = 0\n",
|
||
" for x, y in dataloader:\n",
|
||
" x, y = x.to(device), y.to(device)\n",
|
||
"\n",
|
||
" # Прямой проход\n",
|
||
" logits = model(x) # [B, T, vocab_size]\n",
|
||
"\n",
|
||
" # Перестроим выход под CrossEntropy\n",
|
||
" loss = F.cross_entropy(logits.view(-1, logits.size(-1)), y.view(-1))\n",
|
||
"\n",
|
||
" # Обратное распространение\n",
|
||
" optimizer.zero_grad()\n",
|
||
" loss.backward()\n",
|
||
" optimizer.step()\n",
|
||
"\n",
|
||
" total_loss += loss.item()\n",
|
||
"\n",
|
||
" avg_loss = total_loss / len(dataloader)\n",
|
||
" print(f\"Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}\")\n",
|
||
"\n",
|
||
" return model"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "3c351b56",
|
||
"metadata": {},
|
||
"source": [
|
||
"### ✅ 5.1.3 Пример запуска"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 12,
|
||
"id": "dd700a5c",
|
||
"metadata": {},
|
||
"outputs": [
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"Dataset length: 20\n",
|
||
"Epoch 1/100, Loss: 4.5466\n",
|
||
"Epoch 2/100, Loss: 4.2532\n",
|
||
"Epoch 3/100, Loss: 3.9998\n",
|
||
"Epoch 4/100, Loss: 3.7857\n",
|
||
"Epoch 5/100, Loss: 3.5823\n",
|
||
"Epoch 6/100, Loss: 3.3802\n",
|
||
"Epoch 7/100, Loss: 3.2312\n",
|
||
"Epoch 8/100, Loss: 3.0589\n",
|
||
"Epoch 9/100, Loss: 2.8971\n",
|
||
"Epoch 10/100, Loss: 2.7329\n",
|
||
"Epoch 11/100, Loss: 2.5889\n",
|
||
"Epoch 12/100, Loss: 2.4817\n",
|
||
"Epoch 13/100, Loss: 2.3101\n",
|
||
"Epoch 14/100, Loss: 2.1343\n",
|
||
"Epoch 15/100, Loss: 2.0490\n",
|
||
"Epoch 16/100, Loss: 1.8943\n",
|
||
"Epoch 17/100, Loss: 1.7862\n",
|
||
"Epoch 18/100, Loss: 1.6848\n",
|
||
"Epoch 19/100, Loss: 1.5660\n",
|
||
"Epoch 20/100, Loss: 1.4896\n",
|
||
"Epoch 21/100, Loss: 1.3954\n",
|
||
"Epoch 22/100, Loss: 1.3091\n",
|
||
"Epoch 23/100, Loss: 1.2422\n",
|
||
"Epoch 24/100, Loss: 1.1602\n",
|
||
"Epoch 25/100, Loss: 1.1006\n",
|
||
"Epoch 26/100, Loss: 1.0547\n",
|
||
"Epoch 27/100, Loss: 0.9972\n",
|
||
"Epoch 28/100, Loss: 0.9414\n",
|
||
"Epoch 29/100, Loss: 0.8983\n",
|
||
"Epoch 30/100, Loss: 0.8630\n",
|
||
"Epoch 31/100, Loss: 0.7975\n",
|
||
"Epoch 32/100, Loss: 0.7723\n",
|
||
"Epoch 33/100, Loss: 0.7307\n",
|
||
"Epoch 34/100, Loss: 0.7038\n",
|
||
"Epoch 35/100, Loss: 0.6767\n",
|
||
"Epoch 36/100, Loss: 0.6498\n",
|
||
"Epoch 37/100, Loss: 0.6052\n",
|
||
"Epoch 38/100, Loss: 0.5923\n",
|
||
"Epoch 39/100, Loss: 0.5587\n",
|
||
"Epoch 40/100, Loss: 0.5362\n",
|
||
"Epoch 41/100, Loss: 0.5186\n",
|
||
"Epoch 42/100, Loss: 0.4819\n",
|
||
"Epoch 43/100, Loss: 0.4704\n",
|
||
"Epoch 44/100, Loss: 0.4753\n",
|
||
"Epoch 45/100, Loss: 0.4510\n",
|
||
"Epoch 46/100, Loss: 0.4102\n",
|
||
"Epoch 47/100, Loss: 0.3981\n",
|
||
"Epoch 48/100, Loss: 0.3920\n",
|
||
"Epoch 49/100, Loss: 0.3864\n",
|
||
"Epoch 50/100, Loss: 0.3532\n",
|
||
"Epoch 51/100, Loss: 0.3462\n",
|
||
"Epoch 52/100, Loss: 0.3315\n",
|
||
"Epoch 53/100, Loss: 0.3281\n",
|
||
"Epoch 54/100, Loss: 0.3150\n",
|
||
"Epoch 55/100, Loss: 0.3121\n",
|
||
"Epoch 56/100, Loss: 0.3134\n",
|
||
"Epoch 57/100, Loss: 0.2914\n",
|
||
"Epoch 58/100, Loss: 0.2914\n",
|
||
"Epoch 59/100, Loss: 0.2678\n",
|
||
"Epoch 60/100, Loss: 0.2641\n",
|
||
"Epoch 61/100, Loss: 0.2631\n",
|
||
"Epoch 62/100, Loss: 0.2479\n",
|
||
"Epoch 63/100, Loss: 0.2349\n",
|
||
"Epoch 64/100, Loss: 0.2383\n",
|
||
"Epoch 65/100, Loss: 0.2283\n",
|
||
"Epoch 66/100, Loss: 0.2229\n",
|
||
"Epoch 67/100, Loss: 0.2152\n",
|
||
"Epoch 68/100, Loss: 0.2116\n",
|
||
"Epoch 69/100, Loss: 0.2042\n",
|
||
"Epoch 70/100, Loss: 0.1961\n",
|
||
"Epoch 71/100, Loss: 0.1787\n",
|
||
"Epoch 72/100, Loss: 0.1907\n",
|
||
"Epoch 73/100, Loss: 0.1777\n",
|
||
"Epoch 74/100, Loss: 0.1813\n",
|
||
"Epoch 75/100, Loss: 0.1711\n",
|
||
"Epoch 76/100, Loss: 0.1836\n",
|
||
"Epoch 77/100, Loss: 0.1748\n",
|
||
"Epoch 78/100, Loss: 0.1684\n",
|
||
"Epoch 79/100, Loss: 0.1622\n",
|
||
"Epoch 80/100, Loss: 0.1739\n",
|
||
"Epoch 81/100, Loss: 0.1607\n",
|
||
"Epoch 82/100, Loss: 0.1657\n",
|
||
"Epoch 83/100, Loss: 0.1579\n",
|
||
"Epoch 84/100, Loss: 0.1588\n",
|
||
"Epoch 85/100, Loss: 0.1526\n",
|
||
"Epoch 86/100, Loss: 0.1405\n",
|
||
"Epoch 87/100, Loss: 0.1420\n",
|
||
"Epoch 88/100, Loss: 0.1531\n",
|
||
"Epoch 89/100, Loss: 0.1392\n",
|
||
"Epoch 90/100, Loss: 0.1355\n",
|
||
"Epoch 91/100, Loss: 0.1278\n",
|
||
"Epoch 92/100, Loss: 0.1331\n",
|
||
"Epoch 93/100, Loss: 0.1343\n",
|
||
"Epoch 94/100, Loss: 0.1355\n",
|
||
"Epoch 95/100, Loss: 0.1298\n",
|
||
"Epoch 96/100, Loss: 0.1254\n",
|
||
"Epoch 97/100, Loss: 0.1149\n",
|
||
"Epoch 98/100, Loss: 0.1265\n",
|
||
"Epoch 99/100, Loss: 0.1308\n",
|
||
"Epoch 100/100, Loss: 0.1178\n"
|
||
]
|
||
},
|
||
{
|
||
"data": {
|
||
"text/plain": [
|
||
"GPT(\n",
|
||
" (_token_embeddings): TokenEmbeddings(\n",
|
||
" (_embedding): Embedding(100, 64, padding_idx=0)\n",
|
||
" )\n",
|
||
" (_position_embeddings): PositionEmbeddings(\n",
|
||
" (embedding): Embedding(8, 64)\n",
|
||
" )\n",
|
||
" (_dropout): Dropout(p=0.1, inplace=False)\n",
|
||
" (_decoders): ModuleList(\n",
|
||
" (0-1): 2 x Decoder(\n",
|
||
" (_heads): MultiHeadAttention(\n",
|
||
" (_heads): ModuleList(\n",
|
||
" (0-3): 4 x HeadAttention(\n",
|
||
" (_k): Linear(in_features=64, out_features=16, bias=True)\n",
|
||
" (_q): Linear(in_features=64, out_features=16, bias=True)\n",
|
||
" (_v): Linear(in_features=64, out_features=16, bias=True)\n",
|
||
" )\n",
|
||
" )\n",
|
||
" (_layer): Linear(in_features=64, out_features=64, bias=True)\n",
|
||
" (_dropout): Dropout(p=0.1, inplace=False)\n",
|
||
" )\n",
|
||
" (_ff): FeedForward(\n",
|
||
" (net): Sequential(\n",
|
||
" (0): Linear(in_features=64, out_features=256, bias=True)\n",
|
||
" (1): ReLU()\n",
|
||
" (2): Linear(in_features=256, out_features=64, bias=True)\n",
|
||
" (3): Dropout(p=0.1, inplace=False)\n",
|
||
" )\n",
|
||
" )\n",
|
||
" (_norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)\n",
|
||
" (_norm2): LayerNorm((64,), eps=1e-05, elementwise_affine=True)\n",
|
||
" )\n",
|
||
" )\n",
|
||
" (_linear): Linear(in_features=64, out_features=100, bias=True)\n",
|
||
")"
|
||
]
|
||
},
|
||
"execution_count": 12,
|
||
"metadata": {},
|
||
"output_type": "execute_result"
|
||
}
|
||
],
|
||
"source": [
|
||
"# 1. Исходный текст\n",
|
||
"text = \"Deep learning is amazing. Transformers changed the world. Attention is all you need. GPT models revolutionized NLP.\"\n",
|
||
"\n",
|
||
"# 2. Обучаем токенизатор\n",
|
||
"bpe = BPE(vocab_size=100)\n",
|
||
"bpe.fit(text)\n",
|
||
"\n",
|
||
"# 3. Создаем датасет\n",
|
||
"dataset = GPTDataset(text, bpe, block_size=8)\n",
|
||
"print(f\"Dataset length: {len(dataset)}\")\n",
|
||
"\n",
|
||
"# 4. Инициализируем модель\n",
|
||
"gpt = GPT(\n",
|
||
" vocab_size=len(bpe.vocab),\n",
|
||
" max_seq_len=8,\n",
|
||
" emb_size=64,\n",
|
||
" num_heads=4,\n",
|
||
" head_size=16,\n",
|
||
" num_layers=2,\n",
|
||
" dropout=0.1\n",
|
||
")\n",
|
||
"\n",
|
||
"# 5. Обучаем\n",
|
||
"train_gpt(gpt, dataset, epochs=100, batch_size=4)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "c3714dfc",
|
||
"metadata": {},
|
||
"source": [
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 5.2 Дообучение\n",
|
||
"\n",
|
||
"После предобучения GPT-1 уже знает структуру и грамматику языка. \n",
|
||
"На втором этапе она дообучается на конкретных задачах (например, классификация, QA) с помощью размеченных данных.\n",
|
||
"\n",
|
||
"Технически это почти то же обучение, только:\n",
|
||
"\n",
|
||
"- Загружаем модель с уже обученными весами.\n",
|
||
"- Используем новые данные.\n",
|
||
"- Можно уменьшить скорость обучения.\n",
|
||
"- Иногда замораживают часть слоёв (например, эмбеддинги).\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 13,
|
||
"id": "4afd7733",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"def fine_tune_gpt(model, dataset, epochs=3, batch_size=16, lr=1e-5, device='cpu', freeze_embeddings=True):\n",
|
||
" if freeze_embeddings:\n",
|
||
" for param in model._token_embeddings.parameters():\n",
|
||
" param.requires_grad = False\n",
|
||
" for param in model._position_embeddings.parameters():\n",
|
||
" param.requires_grad = False\n",
|
||
"\n",
|
||
" dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)\n",
|
||
" optimizer = optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=lr)\n",
|
||
"\n",
|
||
" model.to(device)\n",
|
||
" model.train()\n",
|
||
"\n",
|
||
" for epoch in range(epochs):\n",
|
||
" total_loss = 0\n",
|
||
" for x, y in dataloader:\n",
|
||
" x, y = x.to(device), y.to(device)\n",
|
||
" logits = model(x)\n",
|
||
" loss = F.cross_entropy(logits.view(-1, logits.size(-1)), y.view(-1))\n",
|
||
" optimizer.zero_grad()\n",
|
||
" loss.backward()\n",
|
||
" optimizer.step()\n",
|
||
" total_loss += loss.item()\n",
|
||
" print(f\"Fine-tune Epoch {epoch+1}/{epochs}, Loss: {total_loss / len(dataloader):.4f}\")"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "d1698def",
|
||
"metadata": {},
|
||
"source": []
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 14,
|
||
"id": "71bb6b24",
|
||
"metadata": {},
|
||
"outputs": [
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"Fine-tune Epoch 1/10, Loss: 4.3808\n",
|
||
"Fine-tune Epoch 2/10, Loss: 3.9245\n",
|
||
"Fine-tune Epoch 3/10, Loss: 3.5217\n",
|
||
"Fine-tune Epoch 4/10, Loss: 3.2451\n",
|
||
"Fine-tune Epoch 5/10, Loss: 3.0076\n",
|
||
"Fine-tune Epoch 6/10, Loss: 2.8133\n",
|
||
"Fine-tune Epoch 7/10, Loss: 2.6857\n",
|
||
"Fine-tune Epoch 8/10, Loss: 2.5984\n",
|
||
"Fine-tune Epoch 9/10, Loss: 2.5168\n",
|
||
"Fine-tune Epoch 10/10, Loss: 2.4128\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"# Например, мы хотим дообучить модель на стиле коротких технических фраз\n",
|
||
"fine_tune_text = \"\"\"\n",
|
||
"Transformers revolutionize NLP.\n",
|
||
"Deep learning enables self-attention.\n",
|
||
"GPT generates text autoregressively.\n",
|
||
"\"\"\"\n",
|
||
"\n",
|
||
"dataset = GPTDataset(fine_tune_text, bpe, block_size=8)\n",
|
||
"\n",
|
||
"\n",
|
||
"# Запуск дообучения\n",
|
||
"fine_tune_gpt(gpt, dataset, epochs=10, batch_size=4, lr=1e-4)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "d5ff63e9",
|
||
"metadata": {},
|
||
"source": [
|
||
"## 📝 6. Генерация текста после обучения"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 15,
|
||
"id": "ccb9621a",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"def generate_text(model, bpe, prompt: str, max_new_tokens=20, device='cpu'):\n",
|
||
" model.eval()\n",
|
||
" ids = torch.tensor([bpe.encode(prompt)], dtype=torch.long).to(device)\n",
|
||
" out = model.generate(ids, max_new_tokens=max_new_tokens)\n",
|
||
" text = bpe.decode(out[0].tolist())\n",
|
||
" return text"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 16,
|
||
"id": "f1b82472",
|
||
"metadata": {},
|
||
"outputs": [
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"Deep learning e els revolutionized NLP.\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"print(generate_text(gpt, bpe, \"Deep learning\", max_new_tokens=20))"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": null,
|
||
"id": "eb376510",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": []
|
||
}
|
||
],
|
||
"metadata": {
|
||
"kernelspec": {
|
||
"display_name": ".venv",
|
||
"language": "python",
|
||
"name": "python3"
|
||
},
|
||
"language_info": {
|
||
"codemirror_mode": {
|
||
"name": "ipython",
|
||
"version": 3
|
||
},
|
||
"file_extension": ".py",
|
||
"mimetype": "text/x-python",
|
||
"name": "python",
|
||
"nbconvert_exporter": "python",
|
||
"pygments_lexer": "ipython3",
|
||
"version": "3.10.9"
|
||
}
|
||
},
|
||
"nbformat": 4,
|
||
"nbformat_minor": 5
|
||
}
|