mirror of
https://github.com/pese-git/llm-arch-research.git
synced 2026-01-23 13:00:54 +00:00
- Add ipykernel to project dependencies for Jupyter notebook support - Update BPE and GPT analysis notebooks with latest experiments
276 lines
15 KiB
Plaintext
276 lines
15 KiB
Plaintext
{
|
||
"cells": [
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "2bda8231",
|
||
"metadata": {},
|
||
"source": [
|
||
"# Byte Pair Encoding (BPE)\n",
|
||
"\n",
|
||
"**Byte Pair Encoding (BPE)** — это алгоритм, изначально предложенный для *сжатия данных*, однако впоследствии он был адаптирован для решения задач *токенизации текстов* в NLP-моделях.\n",
|
||
"\n",
|
||
"В контексте обработки естественного языка BPE позволяет представлять текст в виде ограниченного набора токенов, сохраняя при этом способность выразить любые слова, включая редкие или не встречавшиеся ранее (out-of-vocabulary).\n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"## Основная идея\n",
|
||
"\n",
|
||
"Главная идея BPE заключается в **итеративном объединении наиболее часто встречающихся пар символов** в новые, более крупные единицы — *токены*.\n",
|
||
"Этот процесс постепенно строит иерархию от отдельных символов до целых подслов и слов, формируя тем самым *оптимальный словарь токенов* для данного корпуса текста.\n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"## Алгоритм\n",
|
||
"\n",
|
||
"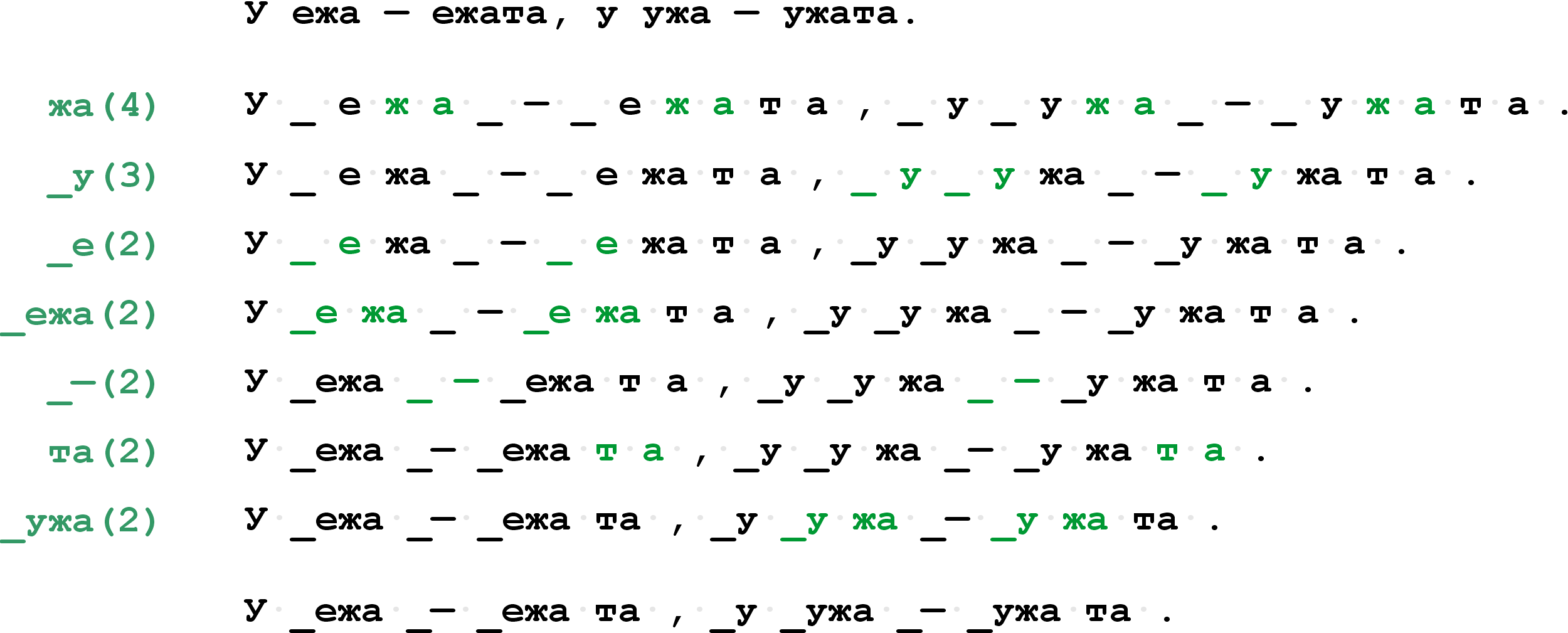\n",
|
||
"\n",
|
||
"Рассмотрим пошагово, как работает классический алгоритм BPE:\n",
|
||
"\n",
|
||
"1. **Инициализация.**\n",
|
||
" Текстовый корпус разбивается на отдельные символы.\n",
|
||
" Например, слово `lower` представляется как `l o w e r`.\n",
|
||
" Каждый уникальный символ добавляется в словарь токенов — это гарантирует, что любая последовательность текста может быть декодирована обратно.\n",
|
||
"\n",
|
||
"2. **Подсчёт частот пар.**\n",
|
||
" Для каждой последовательности токенов в корпусе подсчитываются частоты всех возможных *соседних пар токенов*.\n",
|
||
" Например, если в корпусе часто встречается пара `('t', 'h')`, то она имеет высокий приоритет для объединения.\n",
|
||
"\n",
|
||
"3. **Объединение самой частой пары.**\n",
|
||
" Находится наиболее часто встречающаяся пара токенов, например `('t', 'h')`, и заменяется на новый токен `('th')`.\n",
|
||
" Этот новый токен добавляется в словарь.\n",
|
||
"\n",
|
||
"4. **Обновление корпуса.**\n",
|
||
" Все вхождения выбранной пары заменяются новым токеном.\n",
|
||
" После этого подсчёт частот повторяется на обновлённом тексте.\n",
|
||
"\n",
|
||
"5. **Итерации.**\n",
|
||
" Процесс продолжается до тех пор, пока:\n",
|
||
"\n",
|
||
" * не будет достигнут желаемый размер словаря (например, 50 000 токенов);\n",
|
||
" * или частоты оставшихся пар перестанут иметь практическое значение.\n",
|
||
"\n",
|
||
"В итоге получаем словарь, в котором одни токены представляют отдельные символы, другие — подслова или целые слова.\n",
|
||
"\n",
|
||
"Это компромисс между избыточностью (символьная токенизация) и излишней обобщённостью (словная токенизация).\n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"## Byte-Level BPE\n",
|
||
"\n",
|
||
"В токенизаторах, используемых, например, OpenAI, применяется **Byte-Level BPE** — модификация, работающая не с текстовыми символами, а с их *байтовыми представлениями*.\n",
|
||
"\n",
|
||
"Преимущества этого подхода:\n",
|
||
"\n",
|
||
"* Полная языковая универсальность — один и тот же словарь способен обрабатывать тексты на любом языке, включая редкие и смешанные языки.\n",
|
||
"* Поддержка любых Unicode-символов и эмодзи.\n",
|
||
"* Компактность: итоговый словарь можно ограничить примерно 50 000 токенами без потери выразительности.\n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"## Современные модификации\n",
|
||
"\n",
|
||
"Оригинальный BPE сегодня практически не используется в чистом виде.\n",
|
||
"Каждая крупная модель или библиотека имеет свои вариации алгоритма токенизации, адаптированные под конкретные цели.\n",
|
||
"\n",
|
||
"Некоторые отличия в промышленных реализациях:\n",
|
||
"\n",
|
||
"* **GPT-2:** запрещалось объединять токены разных типов (например, букву и знак препинания `a?`). Это сохраняло читаемость текста.\n",
|
||
"* **GPT-3:** снято ограничение на смешивание типов токенов, но введено правило: нельзя объединять более трёх цифр подряд в один токен.\n",
|
||
"* **GPT-4:** применяется нормализация некоторых редких Unicode-символов — например, разные типы кавычек приводятся к стандартному виду `\"`.\n",
|
||
"* **LLaMA:** запрещено создавать токены, состоящие только из пробелов или управляющих символов (например, `\"\\n\\n\"`).\n",
|
||
"\n",
|
||
"Таким образом, несмотря на общие принципы, **каждый токенизатор уникален**, отражая баланс между эффективностью, универсальностью и удобством декодирования.\n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"\n",
|
||
"## Итог\n",
|
||
"\n",
|
||
"Byte Pair Encoding — это не просто алгоритм токенизации, а компромисс между чисто символьным и чисто словарным представлением текста.\n",
|
||
"Он обеспечивает:\n",
|
||
"\n",
|
||
"* компактный словарь фиксированного размера,\n",
|
||
"* возможность обработки любых текстов, включая ранее невиданные слова,\n",
|
||
"* эффективность при обучении языковых моделей, где баланс между размером словаря и длиной последовательностей критичен.\n",
|
||
"\n",
|
||
"\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 1,
|
||
"id": "e8c52a53",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"import dill\n",
|
||
"\n",
|
||
"class BPE:\n",
|
||
" def __init__(self, vocab_size: int):\n",
|
||
" self.vocab_size = vocab_size\n",
|
||
" self.id2token = {}\n",
|
||
" self.token2id = {}\n",
|
||
"\n",
|
||
" def fit(self, text: str):\n",
|
||
" # 1. Получаем уникальные токены (символы)\n",
|
||
" unique_tokens = sorted(set(text))\n",
|
||
" tokens = unique_tokens.copy()\n",
|
||
"\n",
|
||
" # 2. Разбиваем текст на токены-символы\n",
|
||
" sequence = list(text)\n",
|
||
"\n",
|
||
" # 3. Объединяем токены до достижения нужного размера словаря\n",
|
||
" while len(tokens) < self.vocab_size:\n",
|
||
" #print(f'len={len(tokens)} < {self.vocab_size}')\n",
|
||
" # Считаем частоты пар\n",
|
||
" pair_freq = {}\n",
|
||
" for i in range(len(sequence) - 1):\n",
|
||
" pair = (sequence[i], sequence[i + 1])\n",
|
||
" #print(f'pair = {pair}')\n",
|
||
" if pair not in pair_freq:\n",
|
||
" pair_freq[pair] = 0\n",
|
||
" pair_freq[pair] += 1\n",
|
||
"\n",
|
||
"\n",
|
||
" #print(f'pair_freq = {pair_freq}') \n",
|
||
" if not pair_freq:\n",
|
||
" break # нет пар — выходим\n",
|
||
"\n",
|
||
" #for x in pair_freq.items():\n",
|
||
" # self.debug(x, sequence)\n",
|
||
"\n",
|
||
" # Находим самую частую пару (в случае равенства — та, что встретилась первой)\n",
|
||
" most_frequent_pair = max(pair_freq.items(), key=lambda x: (x[1], -self._pair_first_index(sequence, x[0])))[0]\n",
|
||
" #print(most_frequent_pair)\n",
|
||
" # Создаем новый токен\n",
|
||
" new_token = most_frequent_pair[0] + most_frequent_pair[1]\n",
|
||
" #print(f\"new token={new_token}\")\n",
|
||
" tokens.append(new_token)\n",
|
||
" #print(f\"tokens={tokens}\")\n",
|
||
"\n",
|
||
" i = 0\n",
|
||
" new_sequence = []\n",
|
||
"\n",
|
||
" while i < len(sequence):\n",
|
||
" if i < len(sequence) - 1 and (sequence[i], sequence[i + 1]) == most_frequent_pair:\n",
|
||
" new_sequence.append(new_token)\n",
|
||
" i += 2 # пропускаем два символа — заменённую пару\n",
|
||
" else:\n",
|
||
" new_sequence.append(sequence[i])\n",
|
||
" i += 1\n",
|
||
" sequence = new_sequence\n",
|
||
" #break\n",
|
||
" \n",
|
||
" # 4. Создаем словари\n",
|
||
" self.vocab = tokens.copy()\n",
|
||
" self.token2id = dict(zip(tokens, range(self.vocab_size)))\n",
|
||
" self.id2token = dict(zip(range(self.vocab_size), tokens))\n",
|
||
"\n",
|
||
" def _pair_first_index(self, sequence, pair):\n",
|
||
" for i in range(len(sequence) - 1):\n",
|
||
" if (sequence[i], sequence[i + 1]) == pair:\n",
|
||
" return i\n",
|
||
" return float('inf') # если пара не найдена (в теории не должно случиться)\n",
|
||
"\n",
|
||
"\n",
|
||
" def encode(self, text: str):\n",
|
||
" # 1. Разбиваем текст на токены-символы\n",
|
||
" sequence = list(text)\n",
|
||
" # 2. Инициализация пустого списка токенов\n",
|
||
" tokens = []\n",
|
||
" # 3. Установить i = 0\n",
|
||
" i = 0\n",
|
||
" while i < len(text):\n",
|
||
" # 3.1 Найти все токены в словаре, начинающиеся с text[i]\n",
|
||
" start_char = text[i]\n",
|
||
" result = [token for token in self.vocab if token.startswith(start_char)]\n",
|
||
" # 3.2 Выбрать самый длинный подходящий токен\n",
|
||
" find_token = self._find_max_matching_token(text[i:], result)\n",
|
||
" if find_token is None:\n",
|
||
" # Обработка неизвестного символа\n",
|
||
" tokens.append(text[i]) # Добавляем сам символ как токен\n",
|
||
" i += 1\n",
|
||
" else:\n",
|
||
" # 3.3 Добавить токен в результат\n",
|
||
" tokens.append(find_token)\n",
|
||
" # 3.4 Увеличить i на длину токена\n",
|
||
" i += len(find_token)\n",
|
||
"\n",
|
||
" # 4. Заменить токены на их ID\n",
|
||
" return self._tokens_to_ids(tokens)\n",
|
||
"\n",
|
||
" def _find_max_matching_token(self, text: str, tokens: list):\n",
|
||
" \"\"\"Находит самый длинный токен из списка, с которого начинается текст\"\"\"\n",
|
||
" matching = [token for token in tokens if text.startswith(token)]\n",
|
||
" return max(matching, key=len) if matching else None\n",
|
||
"\n",
|
||
" def _tokens_to_ids(self, tokens):\n",
|
||
" \"\"\"Конвертирует список токенов в их ID с обработкой неизвестных токенов\"\"\"\n",
|
||
" ids = []\n",
|
||
" for token in tokens:\n",
|
||
" if token in self.token2id:\n",
|
||
" ids.append(self.token2id[token])\n",
|
||
" else:\n",
|
||
" ids.append(-1) # Специальное значение\n",
|
||
" return ids\n",
|
||
"\n",
|
||
"\n",
|
||
" def decode(self, ids: list) -> str:\n",
|
||
" return ''.join(self._ids_to_tokens(ids))\n",
|
||
"\n",
|
||
" def _ids_to_tokens(self, ids: list) -> list:\n",
|
||
" \"\"\"Конвертирует список Ids в их tokens\"\"\"\n",
|
||
" tokens = []\n",
|
||
" for id in ids:\n",
|
||
" if id in self.id2token:\n",
|
||
" tokens.append(self.id2token[id])\n",
|
||
" else:\n",
|
||
" tokens.append('') # Специальное значение\n",
|
||
" return tokens\n",
|
||
"\n",
|
||
"\n",
|
||
" def save(self, filename):\n",
|
||
" with open(filename, 'wb') as f:\n",
|
||
" dill.dump(self, f)\n",
|
||
" print(f\"Объект сохранён в {filename}\")\n",
|
||
"\n",
|
||
"\n",
|
||
" @classmethod\n",
|
||
" def load(cls, filename):\n",
|
||
" with open(filename, 'rb') as f:\n",
|
||
" obj = dill.load(f)\n",
|
||
" \n",
|
||
" print(f\"Объект загружен из {filename}\")\n",
|
||
" return obj"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "a9ae19e5",
|
||
"metadata": {},
|
||
"source": []
|
||
}
|
||
],
|
||
"metadata": {
|
||
"kernelspec": {
|
||
"display_name": ".venv",
|
||
"language": "python",
|
||
"name": "python3"
|
||
},
|
||
"language_info": {
|
||
"codemirror_mode": {
|
||
"name": "ipython",
|
||
"version": 3
|
||
},
|
||
"file_extension": ".py",
|
||
"mimetype": "text/x-python",
|
||
"name": "python",
|
||
"nbconvert_exporter": "python",
|
||
"pygments_lexer": "ipython3",
|
||
"version": "3.10.9"
|
||
}
|
||
},
|
||
"nbformat": 4,
|
||
"nbformat_minor": 5
|
||
}
|