2025-10-05 23:01:58 +03:00
{
"cells": [
{
"cell_type": "markdown",
"id": "efbc675e",
"metadata": {},
"source": [
"# Llama\n",
"\n",
"\n",
"\n",
"\n",
"Llama 1 вышла в феврале 2023 года. Это уже подальше, чем GPT-2. И в е е
"\n",
"- Нормализация RMSNorm (вместе с
"- Функция активации SwiGLU.\n",
"- Новый способ кодирования позиций — Rotary Positional Embeddings."
]
},
{
"cell_type": "markdown",
"id": "2cedc663",
"metadata": {},
"source": [
"# RMSNorm\n",
"\n",
"\n",
"\n",
"В
"И, также как в GPT-2, используется *pre-norm* нормализация, то есть слои нормализации располагаются **перед блоками внимания и FNN**.\n",
"\n",
"RMSNorm отличается от обычной нормализации только одним: в нём исключен этап центрирования (вычитание среднего) и используется только масштабирование по RMS.\n",
"Это сокращает вычислительные затраты (на 7–
"Н а
"\n",
"<p align=\"center\">\n",
" <img src=\"https://ucarecdn.com/cbfbb78e-e2b0-40e2-ba56-73e5114d54f6/\" width=\"350\" alt=\"RMSNorm vs LayerNorm\">\n",
"</p>\n",
"\n",
"## Этапы вычисления RMSNorm\n",
"\n",
"1. **Вычисление среднеквадратичного значения:**\n",
"\n",
" $$\\text{RMS}(\\mathbf{x}) = \\sqrt{\\frac{1}{d} \\sum_{j=1}^{d} x_j^2}$$\n",
"\n",
"2. **Нормализация входящего вектора:**\n",
"\n",
" $$\\hat{x}_i = \\frac{x_i}{\\text{RMS}(\\mathbf{x})}$$\n",
"\n",
"3. **Применение масштабирования:**\n",
"\n",
" $$y_i = w_i \\cdot \\hat{x}_i$$\n",
"\n",
"---\n",
"\n",
"**Где:**\n",
"\n",
"* $x_i$ — *i*-й элемент входящего вектора.\n",
"* $w_i$ — *i*-й элемент обучаемого вектора весов.\n",
" Использование весов позволяет модели адаптивно регулировать амплитуду признаков.\n",
" Без них нормализация была бы слишком «жёсткой» и могла бы ограничить качество модели.\n",
"* $d$ — размерность входящего вектора.\n",
"* $\\varepsilon$ — малая константа (например, 1e-6), предотвращает деление на ноль.\n",
"\n",
"---\n",
"\n",
"Так как на вход подаётся тензор, то в векторной форме RMSNorm вычисляется так:\n",
"\n",
"$$\n",
"RMSNorm(x) = w ⊙ \\frac{x}{\\sqrt{mean(x^2) + ϵ}}\n",
"$$\n",
"\n",
"**Где:**\n",
"\n",
"* $x$ — входящий тензор размера `batch_size ×
"\n"
]
},
{
"cell_type": "code",
2025-10-06 12:52:59 +03:00
"execution_count": 1,
2025-10-05 23:01:58 +03:00
"id": "873704be",
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"from torch import nn\n",
"\n",
"class RMSNorm(nn.Module):\n",
" def __init__(self, dim: int, eps: float = 1e-6):\n",
" super().__init__()\n",
" self._eps = eps\n",
" self._w = nn.Parameter(torch.ones(dim))\n",
" \n",
" def forward(self, x: torch.Tensor): # [batch_size × ×
" rms = (x.pow(2).mean(-1, keepdim=True) + self._eps) ** 0.5\n",
" norm_x = x / rms\n",
" return self._w * norm_x"
]
},
{
"cell_type": "markdown",
"id": "09dd9625",
"metadata": {},
"source": [
"# SwiGLU\n",
"\n",
"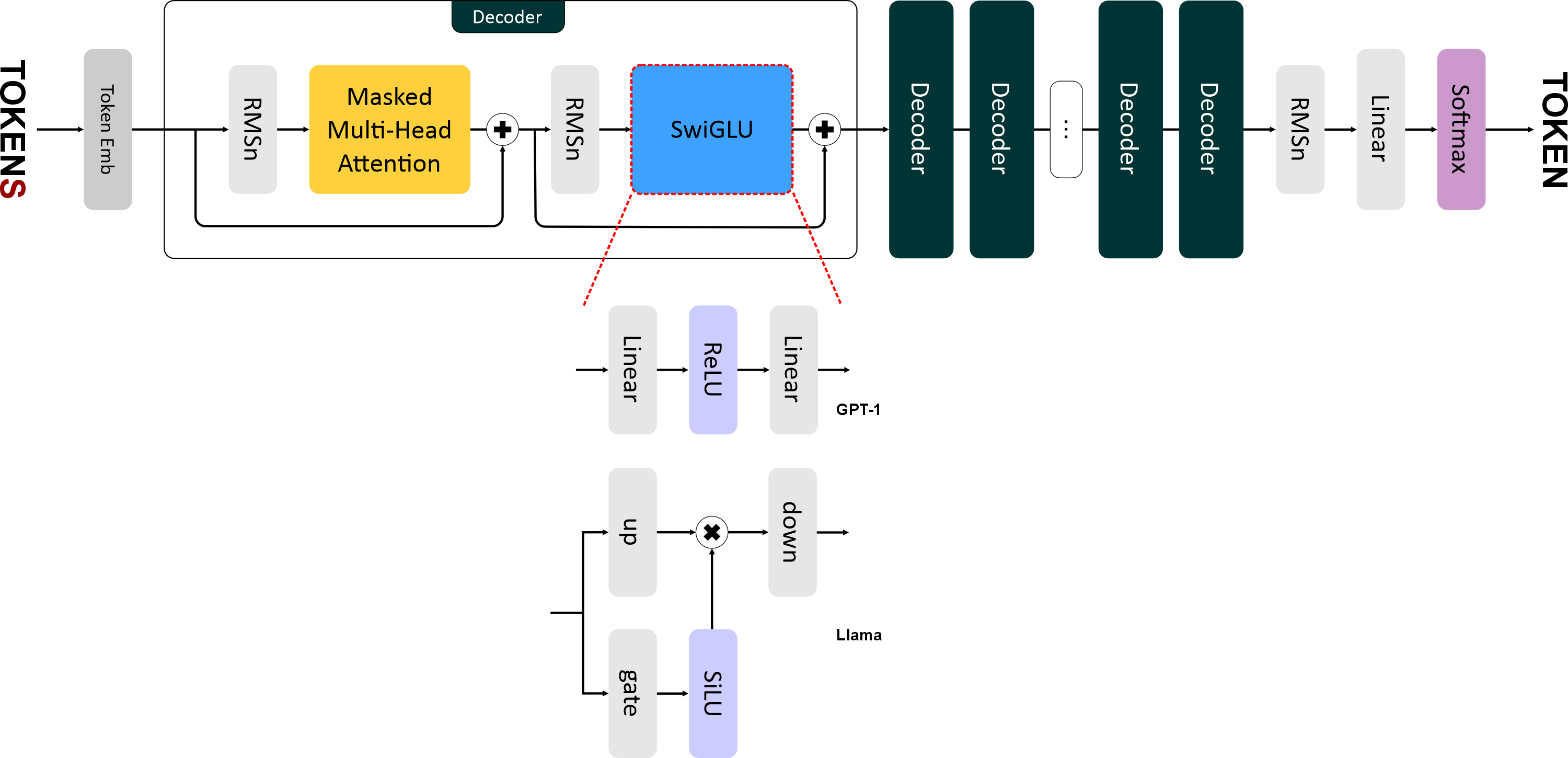\n",
"\n",
"В
"\n",
"Формула SwiGLU выглядит так:\n",
"\n",
"$$\n",
"\\text{SwiGLU}(x) = \\text{down}(\\text{SiLU}(\\text{gate}(x)) \\otimes \\text{up}(x))\n",
"$$\n",
"\n",
"где:\n",
"\n",
"* $x$ — входящий тензор.\n",
"* $\\text{gate}(x)$ — линейный слой для гейтового механизма. Преобразует вход `x` размерностью `emb_size` в промежуточное представление размерности `4 * emb_size`.\n",
"* $\\text{up}(x)$ — линейный слой для увеличения размерности. Также преобразует `x` в размерность `4 * emb_size`.\n",
"* $\\text{SiLU}(x) = x \\cdot \\sigma(x)$ — функция активации, где $\\sigma$ — сигмоида.\n",
"* $\\otimes$ — поэлементное умножение.\n",
"* $\\text{down}(x)$ — линейный слой для уменьшения промежуточного представления до исходного размера (`emb_size`).\n",
"\n",
"> **Гейтинг** (от слова *gate* — «врата») — это механизм, который позволяет сети динамически фильтровать, какая информация должна проходить дальше.\n",
"> При гейтинге создаются как бы два независимых потока:\n",
">\n",
"> * один предназначен для прямой передачи информации (*up-down*),\n",
"> * другой — для контроля передаваемой информации (*gate*).\n",
">\n",
"> Это позволяет сети учить более сложные паттерны.\n",
"> Например, гейт может научиться:\n",
"> «если признак A активен, то пропусти признак B»,\n",
"> что невозможно с
">\n",
"> Также гейтинг помогает с
"\n",
"SwiGLU более сложная (дорогая), чем ReLU/GELU, так как требует больше вычислений (три линейных преобразования вместо двух).\n",
"Н о с
"\n",
"График **SiLU** похож на **GELU**, но более гладкий:\n",
"\n",
"<p align=\"center\">\n",
" <img src=\"https://ucarecdn.com/6683e0c8-96b7-4389-826a-a73708b4a835/\" width=\"500\" alt=\"SiLU vs GELU\">\n",
"</p>\n"
]
},
{
"cell_type": "code",
2025-10-06 12:52:59 +03:00
"execution_count": 2,
2025-10-05 23:01:58 +03:00
"id": "0484cf77",
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"from torch import nn\n",
"import torch.nn.functional as F\n",
"\n",
"class SiLU(nn.Module):\n",
" def forward(self, x: torch.Tensor): # [batch_size × ×
" return torch.sigmoid(x) * x"
]
},
{
"cell_type": "markdown",
"id": "0b64da5d",
"metadata": {},
"source": [
"## SwiGLU"
]
},
{
"cell_type": "code",
2025-10-06 12:52:59 +03:00
"execution_count": 3,
2025-10-05 23:01:58 +03:00
"id": "74ca39ba",
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"from torch import nn\n",
"\n",
"class SwiGLU(nn.Module):\n",
" def __init__(self, emb_size: int, dropout: float = 0.1):\n",
" super().__init__()\n",
"\n",
" self._gate = nn.Linear(emb_size, 4 * emb_size)\n",
" self._up = nn.Linear(emb_size, 4 * emb_size)\n",
" self._down = nn.Linear(4 * emb_size, emb_size)\n",
2025-10-06 12:52:59 +03:00
" self._activation = SiLU()\n",
2025-10-05 23:01:58 +03:00
" self._dropout = nn.Dropout(dropout)\n",
"\n",
" def forward(self, x: torch.Tensor): # [batch_size × ×
" gate_out = self._gate(x) # [batch, seq, 4*emb]\n",
" activation_out = self._activation(gate_out) # [batch, seq, 4*emb]\n",
" up_out = self._up(x) # [batch, seq, 4*emb]\n",
" out = up_out * activation_out # поэлементное!\n",
" out = self._down(out) # [batch, seq, emb]\n",
" return self._dropout(out)\n",
"\n",
" "
]
},
2025-10-06 12:52:59 +03:00
{
"cell_type": "markdown",
"id": "ecd2bcc0",
"metadata": {},
"source": [
"# RoPE\n",
"\n",
"Вот мы и добрались до наиболее серьезного изменения в архитектуре: обычные позиционные эмбеддинги в **Llama** были заменены на **Rotary Positional Embeddings (RoPE)**.\n",
"\n",
"**GPT-1** получал информацию о
"**RoPE** же кодирует позиции токенов с а
"\n",
"Если упрощенно, то выглядит это так:\n",
"\n",
"* Слово на позиции **1**: поворот на 1°\n",
"* Слово на позиции **2**: поворот на 2°\n",
"* Слово на позиции **100**: поворот на 100°\n",
"* Слово на позиции **101**: поворот на 101°\n",
"\n",
"Угол между 1 и 101 словом будет достаточно большим — **100°**, что отражает большую дистанцию между ними.\n",
"А
"\n",
"Такое относительное кодирование позволяет модели лучше понимать расстояние между токенами.\n",
"\n",
"<p align=\"center\">\n",
" <img src=\"https://ucarecdn.com/26cd6249-bb93-4a26-9670-8d3847d9db4d/\" width=\"400\" alt=\"RoPE rotation illustration\">\n",
"</p>\n",
"\n",
"В
"А
"\n",
"---\n",
"\n",
"## Почему RoPE лучше\n",
"\n",
"* **Устойчивость к сдвигу:** модель не переобучается на конкретных позициях в обучающих данных, так как учитывает относительные расстояния.\n",
"* **Экономия:** интегрируется в ключи (*key*) и запросы (*query*) посредством матричных вычислений, без необходимости создавать и хранить отдельный слой для позиционных эмбеддингов.\n",
"* **Экстраполяция:** модель может работать с
]
},
{
"cell_type": "markdown",
"id": "8ba07b89",
"metadata": {},
"source": [
"### Как это работает...\n",
"\n",
"Основная идея: для каждого токена в последовательности е г о
"\n",
"Н а
"Обозначим е г о
"\n",
"<p align=\"center\">\n",
" <img src=\"https://ucarecdn.com/c6d62324-a062-4be7-943c-36cf16b5a424/\" alt=\"rope_0_1.png\" width=\"250\" height=\"127\" />\n",
"</p>\n",
"\n",
"Каждая строка в тензоре — это вектор, соответствующий одному токену в последовательности.\n",
"Обозначим вектор как *xₘ*, где *m* — номер позиции токена.\n",
"\n",
"<p align=\"center\">\n",
" <img src=\"https://ucarecdn.com/8eb58921-02ef-4235-856d-e4cabd691f22/\" alt=\"rope_0_2.png\" width=\"400\" height=\"99\" />\n",
"</p>\n",
"\n",
"Вращать вектор мы будем в двумерном пространстве. Н о
"Чтобы свести вращение к двумерному пространству, вектор разбивают на рядом стоящие пары измерений:\n",
"\n",
"$$\n",
"x_m = [x_{m0}, x_{m1}, x_{m2}, x_{m3}, …, x_{m(d− − − −
"$$\n",
"\n",
"> Из-за того, что вектор обязательно должен быть разбит на пары, RoPE может работать только для четных `head_size`.\n",
"\n",
"После этого мы можем рассматривать каждую пару\n",
"$(x_{m,2k}; x_{m,2k+1})$\n",
"как вектор в двумерном пространстве:\n",
"\n",
"$$\n",
"\\begin{bmatrix}\n",
"x_{m,2k} \\\n",
"x_{m,2k+1}\n",
"\\end{bmatrix}\n",
"$$\n",
"\n",
"А е г о
"$m \\cdot \\theta_k$.\n",
"\n",
"\n"
]
},
2025-10-05 23:01:58 +03:00
{
"cell_type": "markdown",
"id": "c386a55c",
"metadata": {},
"source": []
},
2025-10-06 12:52:59 +03:00
{
"cell_type": "markdown",
"id": "450e03ac",
"metadata": {},
"source": [
"\n",
"\n",
"Каждая пара измерений вектора поворачивается на угол:\n",
"\n",
"$$\n",
"m \\cdot \\theta_k\n",
"$$\n",
"\n",
"<p align=\"center\">\n",
" <img src=\"https://ucarecdn.com/f4eca185-7e82-43e8-a796-c88482fee36f/\" alt=\"rope_0_3.png\" width=\"150\" height=\"109\">\n",
"</p>\n",
"\n",
"Здесь\n",
"$ \\theta_k $ — это частота вращения, которая вычисляется по формуле:\n",
"\n",
"$$\n",
"\\theta_k = \\frac{1}{base^{2k/d}}\n",
"$$\n",
"\n",
"где:\n",
"\n",
"* **base** — гиперпараметр (обычно = 10 000),\n",
"* **k** — индекс пары (от 0 до `d/2 - 1`),\n",
"* **d** — размерность вектора (`head_size`) запроса (*query*) в каждой голове, каждого блока внимания.\n",
"\n",
"\n",
"Само вращение выполняется с
"\n",
"$$\n",
"R(m, \\theta_k) =\n",
"\\begin{bmatrix}\n",
"\\cos(m \\theta_k) & -\\sin(m \\theta_k) \\\\\n",
"\\sin(m \\theta_k) & \\cos(m \\theta_k)\n",
"\\end{bmatrix}\n",
"$$\n",
"\n",
"Для этого каждая пара\n",
"($x_{m,2k}$; $x_{m,2k+1}$)\n",
"перемножается на матрицу поворота:\n",
"\n",
"\n",
"\n",
"$$\n",
"\\begin{bmatrix} \n",
"x_{m,2k}' \\\\ \n",
"x_{m,2k+1}' \n",
"\\end{bmatrix}\n",
"= \n",
"R(m, \\theta_k) \\cdot \n",
"\\begin{bmatrix} \n",
"x_{m,2k} \\\\ \n",
"x_{m,2k+1} \n",
"\\end{bmatrix}\n",
"$$\n",
"\n",
"$$\n",
"\\begin{bmatrix} \n",
"x_{m,2k}' \\\\ \n",
"x_{m,2k+1}' \n",
"\\end{bmatrix}\n",
"= \n",
"\\begin{bmatrix} \n",
"\\cos(m \\theta_k) & -\\sin(m \\theta_k) \\\\ \n",
"\\sin(m \\theta_k) & \\cos(m \\theta_k) \n",
"\\end{bmatrix} \n",
"\\cdot \n",
"\\begin{bmatrix} \n",
"x_{m,2k} \\\\ \n",
"x_{m,2k+1} \n",
"\\end{bmatrix}\n",
"$$\n",
"\n",
"$$\n",
"\\begin{bmatrix} \n",
"x_{m,2k}' \\\\ \n",
"x_{m,2k+1}' \n",
"\\end{bmatrix}\n",
"= \n",
"\\begin{bmatrix} \n",
"x_{m,2k} \\cdot \\cos(m \\theta_k) - x_{m,2k+1} \\cdot \\sin(m \\theta_k) \\\\ \n",
"x_{m,2k} \\cdot \\sin(m \\theta_k) + x_{m,2k+1} \\cdot \\cos(m \\theta_k) \n",
"\\end{bmatrix}\n",
"$$\n",
"\n",
"Где:\n",
"\n",
"* $R(m, \\theta_k)$ — это стандартная матрица вращения в 2D пространстве. Взята из классической линейной алгебры.\n",
"* $\\theta_k$ — частота вращения для $k$-й пары измерений.\n",
"* $m$ — позиция токена в последовательности.\n",
"* $k$ — индекс пары измерений.\n",
"* $x_{m,2k}$ и $x_{m,2k+1}$ — четное и нечетное измерение вектора.\n",
"* $x_{m,2k}'$ и $x_{m,2k+1}'$ — четное и нечетное измерение вектора после вращения.\n",
"\n",
"И так происходит с
"\n",
"---\n",
"\n",
"**Примечание**\n",
"\n",
"Обратите внимание, что разные вектора и их составляющие вращаются с
"Угол поворота зависит от позиции токена $m$, и позиции пары $k$.\n",
"\n",
"$$\n",
"m \\cdot \\theta_k = m \\cdot \\frac{1}{base^{-2k/d}}\n",
"$$\n",
"\n",
"---\n",
"\n",
"Вот для примера сводная таблица для разных значений $m$ и $k$:\n",
"\n",
"| Позиция $m$ | $k=0$ | $k=1$ | $k=2$ | $k=3$ |\n",
"| ----------- | ------- | ------ | ----- | ------ |\n",
"| 0 | 0° | 0° | 0° | 0° |\n",
"| 1 | 1.0° | 0.1° | 0.01° | 0.001° |\n",
"| 10 | 10.0° | 1.0° | 0.1° | 0.01° |\n",
"| 100 | 100.0° | 10.0° | 1.0° | 0.1° |\n",
"| 1000 | 1000.0° | 100.0° | 10.0° | 1.0° |\n",
"\n",
"\n",
"\n",
"- $m$ напрямую и линейно масштабирует угол: чем больше $m$, тем больше угол поворота.\n",
"- $k$ делает наоборот: чем больше $k$, тем меньше угол.\n",
"И уменьшается он экспоненциально с
"\n",
"Такое неравномерное распределение создает уникальный паттерн для каждого вектора,\n",
"что позволяет модели лучше различать **относительные позиции**."
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "02c300f9",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"cos shape: torch.Size([512, 32])\n",
"sin shape: torch.Size([512, 32])\n"
]
}
],
"source": [
"def create_rotary_embeddings(head_size, max_seq_len, base=10000):\n",
" \"\"\"\n",
" Создает матрицы косинусов и синусов для RoPE.\n",
" \n",
" Returns:\n",
" cos_matrix: [max_seq_len, head_size//2]\n",
" sin_matrix: [max_seq_len, head_size//2]\n",
" \"\"\"\n",
" # Обратные частоты\n",
" freqs = 1.0 / (base ** (2 * torch.arange(head_size // 2) / head_size))\n",
" \n",
" # Позиции\n",
" positions = torch.arange(max_seq_len)\n",
" \n",
" # Матрица частот (внешнее произведение)\n",
" freq_matrix = torch.outer(positions, freqs)\n",
" \n",
" # Матрицы косинусов и синусов\n",
" cos_matrix = torch.cos(freq_matrix)\n",
" sin_matrix = torch.sin(freq_matrix)\n",
" \n",
" return cos_matrix, sin_matrix\n",
"\n",
"# Использование\n",
"head_size = 64\n",
"max_seq_len = 512\n",
"\n",
"cos_m, sin_m = create_rotary_embeddings(head_size, max_seq_len)\n",
"print(f\"cos shape: {cos_m.shape}\") # torch.Size([512, 32])\n",
"print(f\"sin shape: {sin_m.shape}\") # torch.Size([512, 32])"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "ac072b9b",
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABKUAAAGGCAYAAACqvTJ0AAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjYsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvq6yFwwAAAAlwSFlzAAAPYQAAD2EBqD+naQAAfxFJREFUeJzt3QeYk1X2x/GbZJLpM/ShN+liFxWxi2DHurqyu6jYVsVed+2rYlkFEcWytnXtvXcQG1bsIIgivcP0nuT/3Nf/jAygQn7XJJN8P88zypR735PMMDnc9557fNFoNGoAAAAAAACAOPLH82IAAAAAAACAxaIUAAAAAAAA4o5FKQAAAAAAAMQdi1IAAAAAAACIOxalAAAAAAAAEHcsSgEAAAAAACDuWJQCAAAAAABA3LEoBQAAAAAAgLhjUQoAAAAAAABxx6IUgKTn8/nMFVdckegwkoZ9LuxzAgAA0k/37t3Nsccem+gwksb999/v5UU//fRTokMBEAMWpQBskh9++MGcfPLJpmfPniYrK8sUFBSYIUOGmFtuucVUVVWZVExy7Nt777233uej0ajp0qWL9/kDDzwwpmtce+215tlnn3UQLQAAaM6+/vprc8QRR5hu3bp5OVanTp3MPvvsY2699VaTDN5+++3GvOh///vfBr/G5oT28wMHDozpGrfffruXfwFIH76o/VcVAGyEl156yRx55JEmMzPT/O1vf/MSjtraWm/B5qmnnvLu2t11113Or1tdXW0yMjK8t3iySdFxxx3nJYb2/zZRWjc523PPPb3nY+jQoebFF1/c5Gvk5eV5CeimJGD19fXem40LAAA0fx988IGXU3Tt2tWMGjXKtG/f3ixYsMB8+OGH3g3BOXPmNH5tTU2N8fv9JhgMxjXGhrzH5h/2/y+//HKTz9udSj169PA+v9lmm5lvvvlmk69hc8s2bdp419pY4XDY1NXVefkYO8mB5ie+/8ID0GzNnTvXHH300d7du8mTJ5sOHTo0fu60007zkiW7aPVHSPTiy/7772+eeOIJM2HChCYLYw8//LDZbrvtzMqVK+MSR0VFhcnNzU3IAh0AAPjjXHPNNaawsNB88sknpkWLFk0+t3z58ibv28WXROdFzz//vJf/2AWktfOioqIi07t3b7NmzZq45UWBQMB7A9A8Ub4HYKPccMMNpry83Nxzzz1NFqQa9OrVy5x55pmN79udPP/617+8O2U2ebLnH/zjH//w7u6t7dNPPzXDhw/3kprs7GzvDtvxxx//m2dKNZypZBfC7O4sm7zZRM7uZqqsrFwvNrvF3C4e2flbtWrlLa7Zu48b689//rNZtWqVeeONNxo/ZneIPfnkk+aYY47Z4Jh///vfZueddzatW7f2rmuvb79+3cdlE6oHHnigcTt8wxkRDY9xxowZ3jVatmxpdtlllyafa3Dfffd57997773rlQbaj697JxMAACQXuxtq8803X29BymrXrt1vninVcNzA+++/b8455xzTtm1bb7Hm0EMPNStWrFhvvldeecXsuuuu3tfk5+ebAw44wHz77bcbHeuIESO83M7esFubXZT605/+tMEFIpur7LXXXt5jsWMHDBhgJk2atN7jsnFMnTq1MS/aY489mjxG+7lTTz3Vm6dz584bPFPK3jy1O8kuu+yy9eKzX7fudQEkFotSADbKCy+84J0jZRdaNsYJJ5zgJQPbbrutGTdunNl9993N2LFjvQWhte/8DRs2zEsiLrroIu/MhJEjR3pb1TeGTXzKysq8ee2fbVJy5ZVXrnfn0ZYa2rt2N998sznrrLPMW2+9ZXbbbTdTXFy8UdexSdLgwYPNI4880iShKykpafJ41mbP2Npmm23MVVdd5S0O2Z1NtvRx7d1kDz74oJeY2cTQ/tm+2fO61mbH2IU2O8eJJ564wWvZxTh7ppVNRBsW2+y5FPa5GD16tHdHEwAAJC+7E/2zzz6LqeStwZgxY8yXX35pLr/8cvP3v//dy91OP/30Jl9jcw27CGWPD7j++uvNpZde6t0Asze+Nvag8JycHG9hau28yF7XLij92s06uxBkH6O9QXnTTTd5Z3LaxaXbbrut8WvGjx/vLTT169evMS/65z//2WQeO8bGa3NMmztuiF38sl9n88Pp06d7H1uyZIn3/NjjFk455ZSNepwA4sSeKQUAv6WkpMSePRcdMWLERn39F1984X39CSec0OTj5513nvfxyZMne+8/88wz3vuffPLJb85nv+byyy9vfN/+2X7s+OOPb/J1hx56aLR169aN7//000/RQCAQveaaa5p83ddffx3NyMhY7+Pruu+++xrjmzhxYjQ/Pz9aWVnpfe7II4+M7rnnnt6fu3XrFj3ggAOajG34uga1tbXRgQMHRvfaa68mH8/NzY2OGjVqvWs3PMY///nPv/q5tS1ZsiTaqlWr6D777BOtqamJbrPNNtGuXbt63zsAAJDcXn/9dS9nsW+DBw+OXnDBBdHXXnvNyx/WZfOOtXOHhnxl6NCh0Ugk0vjxs88+25uvuLjYe7+srCzaokWL6IknnthkvqVLl0YLCwvX+/i6pkyZ4l3niSeeiL744otRn88XnT9/vve5888/P9qzZ0/vz7vvvnt08803/828yBo+fHjjmAZ2nB2/robHuMsuu0Tr6+s3+Lm5c+c2fqyioiLaq1cvb77q6movTysoKIjOmzfvNx8jgPhjpxSA31VaWur9327x3hgN5WJ2587azj33XO//DbuFGrao2wPC7QGVm2rdO112x5Ets2uI9+mnnzaRSMTbRWXPPWh4s4eH2p1TU6ZM2ehr2Tlsd0Ebq92dZf//a3cDLVuy18Ceq2B3Vdn4Gu7YxfoYf419TPZuoy0xtNf54osvvHI+2x0RAAAkN9tlb9q0aebggw/2dh3ZYxPs8Qa2A589v2ljnHTSSU3K+20+YA8Bnzdvnve+zRHsLnF7LMHaeZEtt9txxx03KS+yO93tkQiPPvqo143Y/t/OuzF5kc2J7HXtLvoff/zRe39j2V3jG3N+lN3NZXfQz5w509sdb3NPu3PfHiQPILlwUi6A39WwsGEXYzaGTX5sLb89Z2rdhRO7ENWQHNlk5PDDD/fKzGyiYM8NOOSQQ7zFno05xHPdxMKeu9SwCGRj/v77771EyS5AbcimdK2x5zPYLd/2PAJbTmeTPNs179fYRaurr77aWxxa+xytTe0KY8/Y2li2lNCen2UTL5uY7r333pt0LQAAkDiDBg3ybqjZcyvtwtQzzzzj5Uc237D5hD2HKda8yLJ5UUN524Zsyo0sm0PZIwZsXrTDDjt4xwf81s06e96VLSu0C2/rnv9pF6Xs2aCu86IhQ4Z4ZYz2pp1d4Fv3zFIAyYFFKQC/yyYpHTt23ORzDn5vAcZ+3h7+bc+QsucevPbaa17CYM8asB+z5x38ll+7U/ZzxZ/xdknZa9jznzb0tb83/7pssmXv0C1dutTst99+GzyM1Hr33Xe9O532ztztt9/uHQxvkzd7yKdN3jbF2ncWf4/dJWYPjrfseQv28dvFQQAA0HyEQiFvgcq+9enTxzs70h4qbhd11LzIsmc12RuF69rUzr42L7rjjju8BixbbbXVry6a2UPc7Y0ye1aUPd/TnidlH6PdWW8X3Rricp0X2ZuCb7/9dmMMdjHM7qACkFxYlAKwUexB2nfddZd3h8se+v1b7EGWNsGwd+T69+/f+PFly5Z528bt59e20047eW/2UHK7aGMPO7fbwO1h6Qrb+c8mYvaumk3qVLaLjT2I3C6YPfbYY7/6dU899ZTJysryFtnW3vFlF6XWtak7p37Laaed1njw+8UXX+wdGLpuCSUAAGg+tt9++8aDulU2L7Js5zq7+1tlD0e3u7Pswo89NP3X2BuPdoHIliGuvZtrQ+WCLvMiu4hny/dsR+QLL7zQOxh9woQJzuYH4Aa30AFslAsuuMBrHWwXiuzi0rrsHSjbcc5q6PZmF0XWZu+OWbbrS8N28oa7dw223npr7/9rl7zF6rDDDvPuGtrywHWvY9+3O4s2hd1ZZbvH2DuCBx100K9+nb2mTap
"text/plain": [
"<Figure size 1200x400 with 2 Axes>"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"import matplotlib.pyplot as plt\n",
"\n",
"cos_m, sin_m = create_rotary_embeddings(64, 100)\n",
"\n",
"fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))\n",
"ax1.imshow(cos_m.numpy(), aspect='auto', cmap='RdBu')\n",
"ax1.set_title('Cosine Matrix')\n",
"ax1.set_xlabel('Frequency dimension')\n",
"ax1.set_ylabel('Position')\n",
"\n",
"ax2.imshow(sin_m.numpy(), aspect='auto', cmap='RdBu')\n",
"ax2.set_title('Sine Matrix')\n",
"ax2.set_xlabel('Frequency dimension')\n",
"ax2.set_ylabel('Position')\n",
"plt.tight_layout()"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "4fe79d02",
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"from torch import nn\n",
"\n",
"class RoPE(nn.Module):\n",
" def __init__(self, head_size: int, max_seq_len: int, base: int = 10_000):\n",
" super().__init__()\n",
" assert head_size % 2 == 0, \"head_size должен быть четным\"\n",
"\n",
" # Обратные частоты\n",
" freqs = 1.0 / (base ** (2 * torch.arange(head_size // 2).float() / head_size))\n",
" \n",
" # Позиции\n",
" positions = torch.arange(max_seq_len).float()\n",
" \n",
" # Матрица частот (внешнее произведение)\n",
" #freq_matrix = torch.outer(positions, freqs)\n",
" freq_matrix = positions.unsqueeze(1) * freqs.unsqueeze(0)\n",
"\n",
" # Матрицы косинусов и синусов\n",
" self.register_buffer('cos_matrix', torch.cos(freq_matrix))\n",
" self.register_buffer('sin_matrix', torch.sin(freq_matrix))\n",
"\n",
"\n",
" def forward(self, x: torch.Tensor): # Получает на вход тензор x (тип float) размером [batch_size × ×
" seq_len = x.size(1)\n",
" # Берем нужную часть матриц и приводим к типу x\n",
" cos = self.cos_matrix[:seq_len].to(x.dtype) # [seq_len, head_size//2]\n",
" sin = self.sin_matrix[:seq_len].to(x.dtype) # [seq_len, head_size//2]\n",
" \n",
"\n",
" # Разделяем на четные и нечетные\n",
" x_even = x[:, :, 0::2] # [batch_size, seq_len, head_size//2]\n",
" x_odd = x[:, :, 1::2] # [batch_size, seq_len, head_size//2]\n",
"\n",
" # Применяем поворот\n",
" x_rotated_even = x_even * cos - x_odd * sin\n",
" x_rotated_odd = x_even * sin + x_odd * cos\n",
"\n",
"\n",
" # Объединяем обратно\n",
" x_rotated = torch.stack([x_rotated_even, x_rotated_odd], dim=-1)\n",
" x_rotated = x_rotated.flatten(-2) # [batch_size, seq_len, head_size]\n",
"\n",
" return x_rotated"
]
},
2025-10-05 23:01:58 +03:00
{
"cell_type": "markdown",
"id": "c9fe652d",
"metadata": {},
"source": []
},
2025-10-06 12:52:59 +03:00
{
"cell_type": "markdown",
"id": "1133b962",
"metadata": {},
"source": []
},
2025-10-05 23:01:58 +03:00
{
"cell_type": "code",
2025-10-06 12:52:59 +03:00
"execution_count": 7,
2025-10-05 23:01:58 +03:00
"id": "fe1274b1",
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"from torch import nn\n",
"import torch.nn.functional as F\n",
"from math import sqrt\n",
"import torch\n",
"from torch import nn\n",
"from torch import Tensor\n",
"\n",
"class TokenEmbeddings(nn.Module):\n",
" def __init__(self, vocab_size: int, emb_size: int):\n",
" super().__init__()\n",
" self._embedding = nn.Embedding(\n",
" num_embeddings=vocab_size,\n",
" embedding_dim=emb_size\n",
" )\n",
"\n",
" def forward(self, x: Tensor) -> Tensor:\n",
" return self._embedding(x)\n",
"\n",
" @property\n",
" def num_embeddings(self) -> int:\n",
" return self._embedding.num_embeddings\n",
"\n",
" @property\n",
" def embedding_dim(self) -> int:\n",
" return self._embedding.embedding_dim\n",
" \n",
" \n",
"class HeadAttention(nn.Module):\n",
"\n",
2025-10-06 12:52:59 +03:00
" def __init__(self, emb_size: int, head_size: int, max_seq_len: int, rope: RoPE):\n",
2025-10-05 23:01:58 +03:00
" super().__init__()\n",
" self._emb_size = emb_size\n",
" self._head_size = head_size\n",
" self._max_seq_len = max_seq_len\n",
2025-10-06 12:52:59 +03:00
" self._rope = rope\n",
2025-10-05 23:01:58 +03:00
"\n",
" self._k = nn.Linear(emb_size, head_size)\n",
" self._q = nn.Linear(emb_size, head_size)\n",
" self._v = nn.Linear(emb_size, head_size)\n",
"\n",
" mask = torch.tril(torch.ones(max_seq_len, max_seq_len))\n",
" self.register_buffer('_tril_mask', mask.bool() if hasattr(torch, 'bool') else mask.byte())\n",
"\n",
" def forward(self, x: torch.Tensor, use_cache: bool = True, cache: tuple = None) -> tuple:\n",
" seq_len = x.shape[1]\n",
" if seq_len > self._max_seq_len:\n",
" raise ValueError(f\"Длина последовательности {seq_len} превышает максимум {self._max_seq_len}\")\n",
"\n",
" k = self._k(x) # [B, T, hs]\n",
" q = self._q(x) # [B, T, hs]\n",
" v = self._v(x) # [B, T, hs]\n",
"\n",
2025-10-06 12:52:59 +03:00
" # ✅ Применяем RoPE к Q и K (Н Е
" q = self._rope(q) # [B, T, hs]\n",
" k = self._rope(k) # [B, T, hs]\n",
"\n",
2025-10-05 23:01:58 +03:00
" if cache is not None:\n",
" k_cache, v_cache = cache\n",
" k = torch.cat([k_cache, k], dim=1) # [B, cache_len + T, hs]\n",
" v = torch.cat([v_cache, v], dim=1) # [B, cache_len + T, hs]\n",
" \n",
" scores = q @ k.transpose(-2, -1) / sqrt(self._head_size)\n",
" \n",
" if cache is None:\n",
" scores = scores.masked_fill(~self._tril_mask[:seq_len, :seq_len], float('-inf'))\n",
" \n",
" weights = F.softmax(scores, dim=-1)\n",
" x_out = weights @ v # [B, T, hs]\n",
"\n",
" if use_cache is True:\n",
" return (x_out, (k, v))\n",
" else:\n",
" return (x_out, None)\n",
" \n",
"from torch import nn\n",
"import torch\n",
"import math\n",
"\n",
"class MultiHeadAttention(nn.Module):\n",
2025-10-06 12:52:59 +03:00
" def __init__(self, num_heads: int, emb_size: int, head_size: int, max_seq_len: int, rope: RoPE, dropout: float = 0.1):\n",
2025-10-05 23:01:58 +03:00
"\n",
" super().__init__()\n",
" self._heads = nn.ModuleList([\n",
" HeadAttention(\n",
" emb_size=emb_size, \n",
" head_size=head_size, \n",
2025-10-06 12:52:59 +03:00
" max_seq_len=max_seq_len,\n",
" rope=rope,\n",
2025-10-05 23:01:58 +03:00
" ) for _ in range(num_heads)\n",
" ])\n",
" self._layer = nn.Linear(head_size * num_heads, emb_size)\n",
" self._dropout = nn.Dropout(dropout)\n",
"\n",
" def forward(self, x: torch.Tensor, mask: torch.Tensor = None, use_cache: bool = True, cache: list = None):\n",
"\n",
" attention_results = []\n",
" for i, head in enumerate(self._heads):\n",
" head_cache = cache[i] if cache is not None else None\n",
" result = head(x, use_cache=use_cache, cache=head_cache)\n",
" attention_results.append(result)\n",
" \n",
" outputs, caches = zip(*attention_results)\n",
" attention_outputs = list(outputs)\n",
" kv_caches = list(caches)\n",
" \n",
" concatenated_attention = torch.cat(attention_outputs, dim=-1)\n",
"\n",
" projected_output = self._layer(concatenated_attention)\n",
" \n",
" final_output = self._dropout(projected_output)\n",
" \n",
" if use_cache is True:\n",
" return (final_output, kv_caches)\n",
" else:\n",
" return (final_output, None)\n",
"\n",
"\n",
"class GELU(nn.Module):\n",
" def __init__(self):\n",
" super().__init__()\n",
" self.sqrt_2_over_pi = torch.sqrt(torch.tensor(2.0) / math.pi)\n",
" \n",
" def forward(self, x: torch.Tensor) -> torch.Tensor:\n",
" return 0.5 * x * (1 + torch.tanh(\n",
" self.sqrt_2_over_pi * (x + 0.044715 * torch.pow(x, 3))\n",
" ))\n",
"\n",
" \n",
"class Decoder(nn.Module):\n",
" def __init__(self, \n",
" num_heads: int,\n",
" emb_size: int,\n",
" head_size: int,\n",
" max_seq_len: int,\n",
2025-10-06 12:52:59 +03:00
" rope: RoPE,\n",
2025-10-05 23:01:58 +03:00
" dropout: float = 0.1\n",
" ):\n",
" super().__init__()\n",
" self._heads = MultiHeadAttention(\n",
" num_heads=num_heads, \n",
" emb_size=emb_size, \n",
" head_size=head_size, \n",
2025-10-06 12:52:59 +03:00
" max_seq_len=max_seq_len,\n",
" rope=rope,\n",
2025-10-05 23:01:58 +03:00
" dropout=dropout\n",
" )\n",
2025-10-06 12:52:59 +03:00
" self._ff = SwiGLU(emb_size=emb_size, dropout=dropout)\n",
2025-10-05 23:01:58 +03:00
" self._norm1 = RMSNorm(emb_size)\n",
" self._norm2 = RMSNorm(emb_size)\n",
"\n",
" def forward(self, x: torch.Tensor, mask: torch.Tensor = None, use_cache: bool = True, cache: list = None) -> torch.Tensor:\n",
" norm1_out = self._norm1(x)\n",
" attention, kv_caches = self._heads(norm1_out, mask, use_cache=use_cache, cache=cache)\n",
" out = attention + x\n",
" \n",
" norm2_out = self._norm2(out)\n",
" ffn_out = self._ff(norm2_out)\n",
"\n",
" if use_cache is True:\n",
" return (ffn_out + out, kv_caches)\n",
" else:\n",
" return (ffn_out + out, None)\n",
"\n",
"\n",
"\n",
"from torch import nn\n",
"import torch\n",
"import torch.nn.functional as F\n",
"\n",
"class Llama(nn.Module):\n",
" def __init__(self,\n",
" vocab_size: int,\n",
" max_seq_len: int,\n",
" emb_size: int,\n",
" num_heads: int,\n",
" head_size: int,\n",
" num_layers: int,\n",
" dropout: float = 0.1,\n",
" device: str = 'cpu'\n",
" ):\n",
" super().__init__()\n",
" self._vocab_size = vocab_size\n",
" self._max_seq_len = max_seq_len\n",
" self._emb_size = emb_size\n",
" self._num_heads = num_heads\n",
" self._head_size = head_size\n",
" self._num_layers = num_layers\n",
" self._dropout = dropout\n",
" self._device = device\n",
" \n",
" self.validation_loss = None\n",
"\n",
" # Инициализация слоев\n",
" self._token_embeddings = TokenEmbeddings(\n",
" vocab_size=vocab_size, \n",
" emb_size=emb_size\n",
" )\n",
2025-10-06 12:52:59 +03:00
" self._position_embeddings = RoPE(\n",
" head_size=head_size,\n",
" max_seq_len=max_seq_len\n",
2025-10-05 23:01:58 +03:00
" )\n",
2025-10-06 12:52:59 +03:00
" #self._position_embeddings = PositionalEmbeddings(\n",
" # max_seq_len=max_seq_len, \n",
" # emb_size=emb_size\n",
" #)\n",
2025-10-05 23:01:58 +03:00
" self._dropout = nn.Dropout(dropout)\n",
" self._decoders = nn.ModuleList([Decoder(\n",
" num_heads=num_heads,\n",
" emb_size=emb_size,\n",
" head_size=head_size,\n",
" max_seq_len=max_seq_len,\n",
2025-10-06 12:52:59 +03:00
" rope=self._position_embeddings,\n",
2025-10-05 23:01:58 +03:00
" dropout=dropout \n",
" ) for _ in range(num_layers)])\n",
" self._norm = RMSNorm(emb_size)\n",
" self._linear = nn.Linear(emb_size, vocab_size)\n",
"\n",
" def forward(self, x: torch.Tensor, use_cache: bool = True, cache: list = None) -> tuple:\n",
" # Проверка длины последовательности (только при отсутствии кэша)\n",
" if cache is None and x.size(1) > self._max_seq_len:\n",
" raise ValueError(f\"Длина последовательности {x.size(1)} превышает максимальную {self.max_seq_len}\")\n",
" \n",
" \n",
" # Вычисление start_pos из кэша (если кэш передан)\n",
2025-10-06 12:52:59 +03:00
" #if cache is not None:\n",
" # # При кэше обрабатываем только один токен (последний)\n",
" # seq_len = 1\n",
" # # Вычисляем start_pos из самого нижнего уровня кэша\n",
" # if cache and cache[0] and cache[0][0]:\n",
" # key_cache, _ = cache[0][0] # Первый декодер, первая голова\n",
" # start_pos = key_cache.size(1) # cache_len\n",
" # else:\n",
" # start_pos = 0\n",
" #else:\n",
" # # Без кэша работаем как раньше\n",
" # start_pos = 0\n",
" # seq_len = x.size(1)\n",
2025-10-05 23:01:58 +03:00
"\n",
" # Эмбеддинги токенов и позиций\n",
" tok_out = self._token_embeddings(x) # [batch, seq_len, emb_size]\n",
2025-10-06 12:52:59 +03:00
" #pos_out = self._position_embeddings(x) # [batch, seq_len, emb_size]\n",
2025-10-05 23:01:58 +03:00
" \n",
" # Комбинирование\n",
2025-10-06 12:52:59 +03:00
" out = self._dropout(tok_out) # [batch, seq_len, emb_size]\n",
2025-10-05 23:01:58 +03:00
" \n",
" # Стек декодеров с
" new_cache = []\n",
" for i, decoder in enumerate(self._decoders):\n",
" decoder_cache = cache[i] if cache is not None else None\n",
" decoder_result = decoder(out, use_cache=use_cache, cache=decoder_cache)\n",
"\n",
" # Извлекаем результат из кортежа\n",
" if use_cache:\n",
" out, decoder_new_cache = decoder_result\n",
" new_cache.append(decoder_new_cache)\n",
" else:\n",
" out = decoder_result[0]\n",
"\n",
" out = self._norm(out)\n",
" logits = self._linear(out)\n",
" \n",
" # Возвращаем результат с
" if use_cache:\n",
" return (logits, new_cache)\n",
" else:\n",
" return (logits, None)\n",
"\n",
" def generate(self,\n",
" x: torch.Tensor, \n",
" max_new_tokens: int, \n",
" do_sample: bool,\n",
" temperature: float = 1.0,\n",
" top_k: int = None,\n",
" top_p: float = None,\n",
" use_cache: bool = True\n",
" ) -> torch.Tensor:\n",
" cache = None\n",
"\n",
" for _ in range(max_new_tokens):\n",
" if use_cache and cache is not None:\n",
" # Используем кэш - передаем только последний токен\n",
" x_input = x[:, -1:] # [batch_size, 1]\n",
" else:\n",
" # Первая итерация или кэш отключен - передаем всю последовательность\n",
" x_input = x\n",
" \n",
" # Прямой проход с
" logits, new_cache = self.forward(x_input, use_cache=use_cache, cache=cache)\n",
" \n",
" # Обновляем кэш для следующей итерации\n",
" if use_cache:\n",
" cache = new_cache\n",
"\n",
" last_logits = logits[:, -1, :] # [batch_size, vocab_size]\n",
"\n",
" # Масштабируем логиты температурой\n",
" if temperature > 0:\n",
" logits_scaled = last_logits / temperature\n",
" else:\n",
" logits_scaled = last_logits\n",
"\n",
" if do_sample == True and top_k != None:\n",
" _, topk_indices = torch.topk(logits_scaled, top_k, dim=-1)\n",
"\n",
" # # Заменим все Н Е
" masked_logits = logits_scaled.clone()\n",
" vocab_size = logits_scaled.size(-1)\n",
"\n",
" # создаём маску: 1, если токен Н Е
" mask = torch.ones_like(logits_scaled, dtype=torch.uint8)\n",
" mask.scatter_(1, topk_indices, 0) # 0 там, где top-k индексы\n",
" masked_logits[mask.byte()] = float('-inf')\n",
"\n",
" logits_scaled = masked_logits\n",
"\n",
" if do_sample == True and top_p != None:\n",
" # 1. Применим softmax, чтобы получить вероятности:\n",
" probs = F.softmax(logits_scaled, dim=-1) # [B, vocab_size]\n",
" # 2. Отсортируем токены по убыванию вероятностей:\n",
" sorted_probs, sorted_indices = torch.sort(probs, descending=True, dim=-1)\n",
" # 3. Посчитаем кумулятивную сумму вероятностей:\n",
" cum_probs = torch.cumsum(sorted_probs, dim=-1) # [B, vocab_size]\n",
" # 4. Определим маску: оставить токены, пока сумма < top_p\n",
" sorted_mask = (cum_probs <= top_p).byte() # [B, vocab_size]\n",
" # Гарантируем, что хотя бы первый токен останется\n",
" sorted_mask[:, 0] = 1\n",
" # 5. Преобразуем маску обратно в оригинальный порядок:\n",
" # Создаём полную маску из 0\n",
" mask = torch.zeros_like(probs, dtype=torch.uint8)\n",
" # Устанавливаем 1 в местах нужных токенов\n",
" mask.scatter_(dim=1, index=sorted_indices, src=sorted_mask)\n",
" # 6. Зануляем логиты токенов вне топ-p:\n",
" logits_scaled[~mask] = float('-inf')\n",
"\n",
" # 4. Применяем Softmax\n",
" probs = F.softmax(logits_scaled, dim=-1) # [batch_size, vocab_size]\n",
"\n",
"\n",
" if do_sample == True:\n",
" # 5. Если do_sample равен True, то отбираем токен случайно с
" next_token = torch.multinomial(probs, num_samples=1) # [batch_size, 1]\n",
" else:\n",
" # 5. Если do_sample равен False, то выбираем токен с
" next_token = torch.argmax(probs, dim=-1, keepdim=True) # [batch_size, 1]\n",
" \n",
" # 6. Добавляем е г о
" x = torch.cat([x, next_token], dim=1) # [batch_size, seq_len+1]\n",
" return x\n",
"\n",
" def save(self, path):\n",
" torch.save({\n",
" 'model_state_dict': self.state_dict(),\n",
" 'vocab_size': self._vocab_size,\n",
" 'max_seq_len': self._max_seq_len,\n",
" 'emb_size': self._emb_size,\n",
" 'num_heads': self._num_heads,\n",
" 'head_size': self._head_size,\n",
" 'num_layers': self._num_layers\n",
" }, path)\n",
"\n",
" @classmethod\n",
" def load(cls, path, device):\n",
" checkpoint = torch.load(path, map_location=device)\n",
" model = cls(\n",
" vocab_size=checkpoint['vocab_size'],\n",
" max_seq_len=checkpoint['max_seq_len'],\n",
" emb_size=checkpoint['emb_size'],\n",
" num_heads=checkpoint['num_heads'],\n",
" head_size=checkpoint['head_size'],\n",
" num_layers=checkpoint['num_layers']\n",
" )\n",
" model.load_state_dict(checkpoint['model_state_dict'])\n",
" model.to(device)\n",
" return model\n",
"\n",
" @property\n",
" def max_seq_len(self) -> int:\n",
" return self._max_seq_len"
]
},
2025-10-06 12:52:59 +03:00
{
"cell_type": "markdown",
"id": "0dd53e32",
"metadata": {},
"source": [
"## 2. Обучение LLAMA\n",
"\n",
"LLAMA обучается в два этапа:\n",
"\n",
"- 1️
"- 2️
]
},
{
"cell_type": "markdown",
"id": "4793cef4",
"metadata": {},
"source": [
"\n",
"\n",
"### 5.1 Предобучение\n",
"\n",
"Н а
"\n",
"Функция потерь:\n",
"$$\n",
"L = - \\sum_{t=1}^{T} \\log P(x_t | x_1, x_2, ..., x_{t-1})\n",
"$$\n",
"\n",
"Таким образом, модель учится строить вероятностную модель языка, \"угадывая\" продолжение текста.\n"
]
},
{
"cell_type": "markdown",
"id": "5b8bf950",
"metadata": {},
"source": [
"В о
"Формально: \n",
"$$ \n",
"P(x_t ,|, x_1, x_2, \\dots, x_{t-1}) \n",
"$$ \n",
"Т о
]
},
{
"cell_type": "markdown",
"id": "96aeecdd",
"metadata": {},
"source": [
"### ✅ 5.1.1 Подготовка данных\n",
"\n",
"Создадим **датасет** на основе BPE-токенизатора:"
]
},
{
"cell_type": "markdown",
"id": "21bd0b2e",
"metadata": {},
"source": [
"**BPE Tokenizator**"
]
},
2025-10-05 23:01:58 +03:00
{
"cell_type": "code",
2025-10-06 12:52:59 +03:00
"execution_count": 8,
"id": "078ed4ce",
"metadata": {},
"outputs": [],
"source": [
"class BPE:\n",
" def __init__(self, vocab_size: int):\n",
" self.vocab_size = vocab_size\n",
" self.id2token = {}\n",
" self.token2id = {}\n",
"\n",
" def fit(self, text: str):\n",
" # 1. Получаем уникальные токены (символы)\n",
" unique_tokens = sorted(set(text))\n",
" tokens = unique_tokens.copy()\n",
"\n",
" # 2. Разбиваем текст на токены-символы\n",
" sequence = list(text)\n",
"\n",
" # 3. Объединяем токены до достижения нужного размера словаря\n",
" while len(tokens) < self.vocab_size:\n",
" #print(f'len={len(tokens)} < {self.vocab_size}')\n",
" # Считаем частоты пар\n",
" pair_freq = {}\n",
" for i in range(len(sequence) - 1):\n",
" pair = (sequence[i], sequence[i + 1])\n",
" #print(f'pair = {pair}')\n",
" if pair not in pair_freq:\n",
" pair_freq[pair] = 0\n",
" pair_freq[pair] += 1\n",
"\n",
"\n",
" #print(f'pair_freq = {pair_freq}') \n",
" if not pair_freq:\n",
" break # нет пар — выходим\n",
"\n",
" #for x in pair_freq.items():\n",
" # self.debug(x, sequence)\n",
"\n",
" # Находим самую частую пару (в случае равенства — та, что встретилась первой)\n",
" most_frequent_pair = max(pair_freq.items(), key=lambda x: (x[1], -self._pair_first_index(sequence, x[0])))[0]\n",
" #print(most_frequent_pair)\n",
" # Создаем новый токен\n",
" new_token = most_frequent_pair[0] + most_frequent_pair[1]\n",
" #print(f\"new token={new_token}\")\n",
" tokens.append(new_token)\n",
" #print(f\"tokens={tokens}\")\n",
"\n",
" i = 0\n",
" new_sequence = []\n",
"\n",
" while i < len(sequence):\n",
" if i < len(sequence) - 1 and (sequence[i], sequence[i + 1]) == most_frequent_pair:\n",
" new_sequence.append(new_token)\n",
" i += 2 # пропускаем два символа — заменённую пару\n",
" else:\n",
" new_sequence.append(sequence[i])\n",
" i += 1\n",
" sequence = new_sequence\n",
" #break\n",
" \n",
" # 4. Создаем словари\n",
" self.vocab = tokens.copy()\n",
" self.token2id = dict(zip(tokens, range(self.vocab_size)))\n",
" self.id2token = dict(zip(range(self.vocab_size), tokens))\n",
"\n",
" def _pair_first_index(self, sequence, pair):\n",
" for i in range(len(sequence) - 1):\n",
" if (sequence[i], sequence[i + 1]) == pair:\n",
" return i\n",
" return float('inf') # если пара не найдена (в теории не должно случиться)\n",
"\n",
"\n",
" def encode(self, text: str):\n",
" # 1. Разбиваем текст на токены-символы\n",
" sequence = list(text)\n",
" # 2. Инициализация пустого списка токенов\n",
" tokens = []\n",
" # 3. Установить i = 0\n",
" i = 0\n",
" while i < len(text):\n",
" # 3.1 Найти все токены в словаре, начинающиеся с
" start_char = text[i]\n",
" result = [token for token in self.vocab if token.startswith(start_char)]\n",
" # 3.2 Выбрать самый длинный подходящий токен\n",
" find_token = self._find_max_matching_token(text[i:], result)\n",
" if find_token is None:\n",
" # Обработка неизвестного символа\n",
" tokens.append(text[i]) # Добавляем сам символ как токен\n",
" i += 1\n",
" else:\n",
" # 3.3 Добавить токен в результат\n",
" tokens.append(find_token)\n",
" # 3.4 Увеличить i на длину токена\n",
" i += len(find_token)\n",
"\n",
" # 4. Заменить токены на их ID\n",
" return self._tokens_to_ids(tokens)\n",
"\n",
" def _find_max_matching_token(self, text: str, tokens: list):\n",
" \"\"\"Находит самый длинный токен из списка, с
" matching = [token for token in tokens if text.startswith(token)]\n",
" return max(matching, key=len) if matching else None\n",
"\n",
" def _tokens_to_ids(self, tokens):\n",
" \"\"\"Конвертирует список токенов в их ID с
" ids = []\n",
" for token in tokens:\n",
" if token in self.token2id:\n",
" ids.append(self.token2id[token])\n",
" else:\n",
" ids.append(0) # Специальное значение\n",
" return ids\n",
"\n",
"\n",
" def decode(self, ids: list) -> str:\n",
" return ''.join(self._ids_to_tokens(ids))\n",
"\n",
" def _ids_to_tokens(self, ids: list) -> list:\n",
" \"\"\"Конвертирует список Ids в их tokens\"\"\"\n",
" tokens = []\n",
" for id in ids:\n",
" if id in self.id2token:\n",
" tokens.append(self.id2token[id])\n",
" else:\n",
" tokens.append('') # Специальное значение\n",
" return tokens\n",
"\n",
"\n",
" def save(self, filename):\n",
" with open(filename, 'wb') as f:\n",
" dill.dump(self, f)\n",
" print(f\"Объект сохранён в {filename}\")\n",
"\n",
"\n",
" @classmethod\n",
" def load(cls, filename):\n",
" with open(filename, 'rb') as f:\n",
" obj = dill.load(f)\n",
" \n",
" print(f\"Объект загружен из {filename}\")\n",
" return obj"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "0258c483",
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"from torch.utils.data import Dataset, DataLoader\n",
"\n",
"class GPTDataset(Dataset):\n",
" def __init__(self, text: str, bpe: BPE, block_size: int):\n",
" self.bpe = bpe\n",
" self.block_size = block_size\n",
" self.data = bpe.encode(text)\n",
" \n",
" def __len__(self):\n",
" return len(self.data) - self.block_size\n",
"\n",
" def __getitem__(self, idx):\n",
" x = torch.tensor(self.data[idx:idx+self.block_size], dtype=torch.long)\n",
" y = torch.tensor(self.data[idx+1:idx+self.block_size+1], dtype=torch.long)\n",
" return x, y"
]
},
{
"cell_type": "markdown",
"id": "5a7d9a2e",
"metadata": {},
"source": [
"### ✅ 5.1.2 Цикл обучения\n",
"\n",
"Для обучения создадим функцию:"
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "f8f06cf7",
"metadata": {},
"outputs": [],
"source": [
"import torch.nn.functional as F\n",
"from torch import optim\n",
"\n",
"def train_llama(model, dataset, epochs=5, batch_size=32, lr=3e-4, device='cpu'):\n",
" dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)\n",
" optimizer = optim.AdamW(model.parameters(), lr=lr)\n",
"\n",
" model.to(device)\n",
" model.train()\n",
"\n",
" for epoch in range(epochs):\n",
" total_loss = 0\n",
" for x, y in dataloader:\n",
" x, y = x.to(device), y.to(device)\n",
"\n",
" # Прямой проход\n",
" logits, _ = model(x, use_cache=False) # [B, T, vocab_size]\n",
"\n",
" # Перестроим выход под CrossEntropy\n",
" loss = F.cross_entropy(logits.view(-1, logits.size(-1)), y.view(-1))\n",
"\n",
" # Обратное распространение\n",
" optimizer.zero_grad()\n",
" loss.backward()\n",
" optimizer.step()\n",
"\n",
" total_loss += loss.item()\n",
"\n",
" avg_loss = total_loss / len(dataloader)\n",
" print(f\"Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}\")\n",
"\n",
" return model"
]
},
{
"cell_type": "markdown",
"id": "576cc8f4",
"metadata": {},
"source": [
"### ✅ 5.1.3 Пример запуска\n",
"\n",
"\n",
"**🧠 Конфигурация LLAMA Mini**\n",
"\n",
"\n",
"| Параметр | Значение | Описание |\n",
"| --------------- | -------- | --------------------------------------------- |\n",
"| **vocab_size** | `50257` | Размер словаря (BPE токенизатор OpenAI) |\n",
"| **max_seq_len** | `512` | Максимальная длина входной последовательности |\n",
"| **emb_size** | `256` | Размер эмбеддингов (векторное пространство) |\n",
"| **num_heads** | `4` | Количество голов в multi-head attention |\n",
"| **head_size** | `64` | Размерность одной головы внимания (768 / 12) |\n",
"| **num_layers** | `4` | Количество блоков (декодеров) |\n",
"| **dropout** | `0.1` | Вероятность дропаута |\n"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "0c753d52",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataset length: 20\n",
"Epoch 1/100, Loss: 3.9063\n",
"Epoch 2/100, Loss: 1.6363\n",
"Epoch 3/100, Loss: 0.6436\n",
"Epoch 4/100, Loss: 0.3222\n",
"Epoch 5/100, Loss: 0.2031\n",
"Epoch 6/100, Loss: 0.1460\n",
"Epoch 7/100, Loss: 0.1119\n",
"Epoch 8/100, Loss: 0.0978\n",
"Epoch 9/100, Loss: 0.0925\n",
"Epoch 10/100, Loss: 0.0757\n",
"Epoch 11/100, Loss: 0.0809\n",
"Epoch 12/100, Loss: 0.0763\n",
"Epoch 13/100, Loss: 0.0671\n",
"Epoch 14/100, Loss: 0.0681\n",
"Epoch 15/100, Loss: 0.0582\n",
"Epoch 16/100, Loss: 0.0655\n",
"Epoch 17/100, Loss: 0.0751\n",
"Epoch 18/100, Loss: 0.0656\n",
"Epoch 19/100, Loss: 0.0625\n",
"Epoch 20/100, Loss: 0.0593\n",
"Epoch 21/100, Loss: 0.0678\n",
"Epoch 22/100, Loss: 0.0652\n",
"Epoch 23/100, Loss: 0.0644\n",
"Epoch 24/100, Loss: 0.0542\n",
"Epoch 25/100, Loss: 0.0627\n",
"Epoch 26/100, Loss: 0.0596\n",
"Epoch 27/100, Loss: 0.0639\n",
"Epoch 28/100, Loss: 0.0536\n",
"Epoch 29/100, Loss: 0.0606\n",
"Epoch 30/100, Loss: 0.0565\n",
"Epoch 31/100, Loss: 0.0622\n",
"Epoch 32/100, Loss: 0.0581\n",
"Epoch 33/100, Loss: 0.0492\n",
"Epoch 34/100, Loss: 0.0553\n",
"Epoch 35/100, Loss: 0.0526\n",
"Epoch 36/100, Loss: 0.0527\n",
"Epoch 37/100, Loss: 0.0570\n",
"Epoch 38/100, Loss: 0.0482\n",
"Epoch 39/100, Loss: 0.0553\n",
"Epoch 40/100, Loss: 0.0444\n",
"Epoch 41/100, Loss: 0.0602\n",
"Epoch 42/100, Loss: 0.0599\n",
"Epoch 43/100, Loss: 0.0598\n",
"Epoch 44/100, Loss: 0.0572\n",
"Epoch 45/100, Loss: 0.0551\n",
"Epoch 46/100, Loss: 0.0577\n",
"Epoch 47/100, Loss: 0.0527\n",
"Epoch 48/100, Loss: 0.0466\n",
"Epoch 49/100, Loss: 0.0551\n",
"Epoch 50/100, Loss: 0.0517\n",
"Epoch 51/100, Loss: 0.0477\n",
"Epoch 52/100, Loss: 0.0539\n",
"Epoch 53/100, Loss: 0.0478\n",
"Epoch 54/100, Loss: 0.0539\n",
"Epoch 55/100, Loss: 0.0435\n",
"Epoch 56/100, Loss: 0.0471\n",
"Epoch 57/100, Loss: 0.0461\n",
"Epoch 58/100, Loss: 0.0452\n",
"Epoch 59/100, Loss: 0.0507\n",
"Epoch 60/100, Loss: 0.0481\n",
"Epoch 61/100, Loss: 0.0398\n",
"Epoch 62/100, Loss: 0.0535\n",
"Epoch 63/100, Loss: 0.0503\n",
"Epoch 64/100, Loss: 0.0504\n",
"Epoch 65/100, Loss: 0.0473\n",
"Epoch 66/100, Loss: 0.0553\n",
"Epoch 67/100, Loss: 0.0514\n",
"Epoch 68/100, Loss: 0.0450\n",
"Epoch 69/100, Loss: 0.0488\n",
"Epoch 70/100, Loss: 0.0414\n",
"Epoch 71/100, Loss: 0.0413\n",
"Epoch 72/100, Loss: 0.0473\n",
"Epoch 73/100, Loss: 0.0530\n",
"Epoch 74/100, Loss: 0.0482\n",
"Epoch 75/100, Loss: 0.0477\n",
"Epoch 76/100, Loss: 0.0483\n",
"Epoch 77/100, Loss: 0.0452\n",
"Epoch 78/100, Loss: 0.0452\n",
"Epoch 79/100, Loss: 0.0474\n",
"Epoch 80/100, Loss: 0.0483\n",
"Epoch 81/100, Loss: 0.0522\n",
"Epoch 82/100, Loss: 0.0453\n",
"Epoch 83/100, Loss: 0.0436\n",
"Epoch 84/100, Loss: 0.0452\n",
"Epoch 85/100, Loss: 0.0523\n",
"Epoch 86/100, Loss: 0.0446\n",
"Epoch 87/100, Loss: 0.0475\n",
"Epoch 88/100, Loss: 0.0503\n",
"Epoch 89/100, Loss: 0.0484\n",
"Epoch 90/100, Loss: 0.0456\n",
"Epoch 91/100, Loss: 0.0433\n",
"Epoch 92/100, Loss: 0.0458\n",
"Epoch 93/100, Loss: 0.0461\n",
"Epoch 94/100, Loss: 0.0448\n",
"Epoch 95/100, Loss: 0.0432\n",
"Epoch 96/100, Loss: 0.0456\n",
"Epoch 97/100, Loss: 0.0470\n",
"Epoch 98/100, Loss: 0.0470\n",
"Epoch 99/100, Loss: 0.0467\n",
"Epoch 100/100, Loss: 0.0471\n"
]
},
{
"data": {
"text/plain": [
"Llama(\n",
" (_token_embeddings): TokenEmbeddings(\n",
" (_embedding): Embedding(100, 256)\n",
" )\n",
" (_position_embeddings): RoPE()\n",
" (_dropout): Dropout(p=0.1, inplace=False)\n",
" (_decoders): ModuleList(\n",
" (0-3): 4 x Decoder(\n",
" (_heads): MultiHeadAttention(\n",
" (_heads): ModuleList(\n",
" (0-3): 4 x HeadAttention(\n",
" (_rope): RoPE()\n",
" (_k): Linear(in_features=256, out_features=64, bias=True)\n",
" (_q): Linear(in_features=256, out_features=64, bias=True)\n",
" (_v): Linear(in_features=256, out_features=64, bias=True)\n",
" )\n",
" )\n",
" (_layer): Linear(in_features=256, out_features=256, bias=True)\n",
" (_dropout): Dropout(p=0.1, inplace=False)\n",
" )\n",
" (_ff): SwiGLU(\n",
" (_gate): Linear(in_features=256, out_features=1024, bias=True)\n",
" (_up): Linear(in_features=256, out_features=1024, bias=True)\n",
" (_down): Linear(in_features=1024, out_features=256, bias=True)\n",
" (_activation): SiLU()\n",
" (_dropout): Dropout(p=0.1, inplace=False)\n",
" )\n",
" (_norm1): RMSNorm()\n",
" (_norm2): RMSNorm()\n",
" )\n",
" )\n",
" (_norm): RMSNorm()\n",
" (_linear): Linear(in_features=256, out_features=100, bias=True)\n",
")"
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# 1. Исходный текст\n",
"text = \"Deep learning is amazing. Transformers changed the world. Attention is all you need. GPT models revolutionized NLP.\"\n",
"\n",
"# 2. Обучаем токенизатор\n",
"bpe = BPE(vocab_size=100)\n",
"bpe.fit(text)\n",
"\n",
"# 3. Создаем датасет\n",
"dataset = GPTDataset(text, bpe, block_size=8)\n",
"print(f\"Dataset length: {len(dataset)}\")\n",
"\n",
"# 4. Инициализируем модель\n",
"model = Llama(\n",
" vocab_size=len(bpe.vocab), # размер словаря BPE\n",
" max_seq_len=512, # GPT-2 использует контекст в 512 токена\n",
" emb_size=256, # размер эмбеддингов\n",
" num_heads=4, # количество голов внимания\n",
" head_size=64, # размер каждой головы (256 / 4)\n",
" num_layers=4, # количество блоков Transformer\n",
" dropout=0.1 # стандартный dropout GPT-2\n",
")\n",
"\n",
"# 5. Обучаем\n",
"train_llama(model, dataset, epochs=100, batch_size=4)"
]
},
{
"cell_type": "markdown",
"id": "631fa9c5",
"metadata": {},
"source": [
"\n",
"---\n",
"\n",
"### 5.2 Дообучение\n",
"\n",
"После предобучения LLAMA уже знает структуру и грамматику языка. \n",
"Н а с
"\n",
"Технически это почти то же обучение, только:\n",
"\n",
"- Загружаем модель с
"- Используем новые данные.\n",
"- Можно уменьшить скорость обучения.\n",
"- Иногда замораживают часть слоёв (например, эмбеддинги).\n"
]
},
{
"cell_type": "markdown",
"id": "7bce4bb4",
"metadata": {},
"source": []
},
{
"cell_type": "code",
"execution_count": 12,
2025-10-05 23:01:58 +03:00
"id": "8efb1396",
"metadata": {},
"outputs": [],
2025-10-06 12:52:59 +03:00
"source": [
"def fine_tune_llama(model, dataset, epochs=3, batch_size=16, lr=1e-5, device='cpu', freeze_embeddings=True):\n",
" if freeze_embeddings:\n",
" for param in model._token_embeddings.parameters():\n",
" param.requires_grad = False\n",
" for param in model._position_embeddings.parameters():\n",
" param.requires_grad = False\n",
"\n",
" dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)\n",
" optimizer = optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=lr)\n",
"\n",
" model.to(device)\n",
" model.train()\n",
"\n",
" for epoch in range(epochs):\n",
" total_loss = 0\n",
" for x, y in dataloader:\n",
" x, y = x.to(device), y.to(device)\n",
" logits, _ = model(x, use_cache=False)\n",
" loss = F.cross_entropy(logits.view(-1, logits.size(-1)), y.view(-1))\n",
" optimizer.zero_grad()\n",
" loss.backward()\n",
" optimizer.step()\n",
" total_loss += loss.item()\n",
" print(f\"Fine-tune Epoch {epoch+1}/{epochs}, Loss: {total_loss / len(dataloader):.4f}\")"
]
},
{
"cell_type": "code",
"execution_count": 14,
"id": "b4a1c9d9",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Fine-tune Epoch 1/10, Loss: 4.8250\n",
"Fine-tune Epoch 2/10, Loss: 2.6400\n",
"Fine-tune Epoch 3/10, Loss: 1.6920\n",
"Fine-tune Epoch 4/10, Loss: 1.2630\n",
"Fine-tune Epoch 5/10, Loss: 1.0183\n",
"Fine-tune Epoch 6/10, Loss: 0.8237\n",
"Fine-tune Epoch 7/10, Loss: 0.6869\n",
"Fine-tune Epoch 8/10, Loss: 0.5854\n",
"Fine-tune Epoch 9/10, Loss: 0.5155\n",
"Fine-tune Epoch 10/10, Loss: 0.4489\n"
]
}
],
"source": [
"# Например, мы хотим дообучить модель на стиле коротких технических фраз\n",
"fine_tune_text = \"\"\"\n",
"Transformers revolutionize NLP.\n",
"Deep learning enables self-attention.\n",
"GPT generates text autoregressively.\n",
"\"\"\"\n",
"\n",
"dataset = GPTDataset(fine_tune_text, bpe, block_size=8)\n",
"\n",
"\n",
"# Запуск дообучения\n",
"fine_tune_llama(model, dataset, epochs=10, batch_size=4, lr=1e-4)"
]
},
{
"cell_type": "markdown",
"id": "cc9106b7",
"metadata": {},
"source": [
"## 📝 6. Генерация текста после обучения"
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "d77b8ff5",
"metadata": {},
"outputs": [],
"source": [
"def generate_text(model, bpe, prompt: str, max_new_tokens=20, device='cpu'):\n",
" model.eval()\n",
" ids = torch.tensor([bpe.encode(prompt)], dtype=torch.long).to(device)\n",
" out = model.generate(ids, max_new_tokens=max_new_tokens, do_sample=True)\n",
" text = bpe.decode(out[0].tolist())\n",
" return text"
]
},
{
"cell_type": "code",
"execution_count": 17,
"id": "79fea720",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Deep learning ena les selelf les te\n"
]
}
],
"source": [
"print(generate_text(model, bpe, \"Deep learning\", max_new_tokens=20))"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "05c4de3d",
"metadata": {},
"outputs": [],
2025-10-05 23:01:58 +03:00
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": ".venv",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.9"
}
},
"nbformat": 4,
"nbformat_minor": 5
}