mirror of
https://github.com/pese-git/llm-arch-research.git
synced 2026-01-23 21:10:54 +00:00
1247 lines
51 KiB
Plaintext
1247 lines
51 KiB
Plaintext
{
|
||
"cells": [
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "6842e799",
|
||
"metadata": {},
|
||
"source": [
|
||
"# Архитектура GPT-2\n",
|
||
"\n",
|
||
"GPT-2 — это эволюция GPT-1, предложенная OpenAI в 2019 году. Модель сохраняет **архитектуру трансформера-декодера**, но вносит несколько ключевых улучшений, благодаря которым она стала более стабильной и способной генерировать длинные тексты.\n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"## Основные улучшения GPT-2 по сравнению с GPT-1\n",
|
||
"\n",
|
||
"### 1. Масштаб модели\n",
|
||
"\n",
|
||
"- GPT-2 значительно **увеличила количество параметров**.\n",
|
||
" \n",
|
||
" |Модель|Параметры|Слои (Decoder)|Размер эмбеддингов|Heads|\n",
|
||
" |---|---|---|---|---|\n",
|
||
" |GPT-1|117M|12|768|12|\n",
|
||
" |GPT-2|1.5B|48|1600|25|\n",
|
||
" \n",
|
||
"- Увеличение глубины и ширины слоёв позволяет модели **захватывать более сложные закономерности языка**.\n",
|
||
" \n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 2. Pre-norm и Post-norm\n",
|
||
"\n",
|
||
"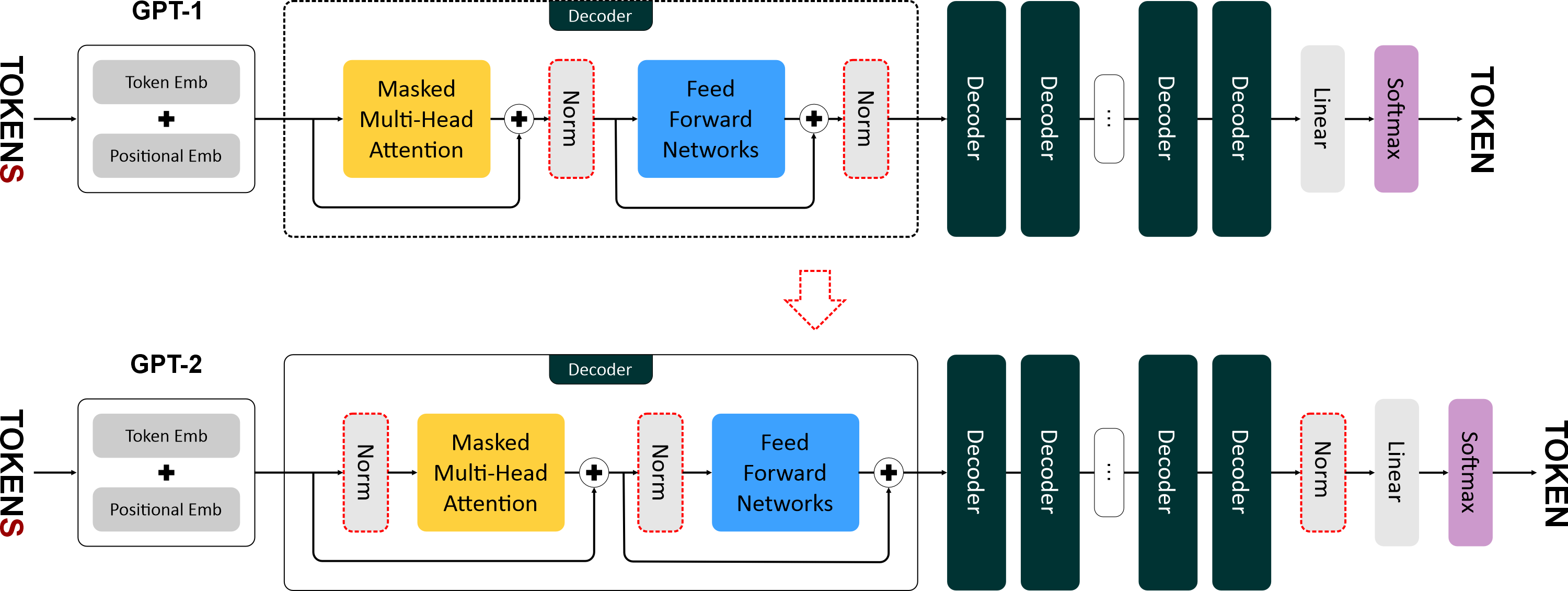\n",
|
||
"\n",
|
||
"- **GPT-1** использовала **post-norm**, когда слои нормализации применялись **после блоков внимания и FFN**.\n",
|
||
" \n",
|
||
"- **GPT-2** ввела **pre-norm**, то есть **слои нормализации располагаются перед блоками внимания и FFN**.\n",
|
||
" \n",
|
||
" - Это повышает **устойчивость обучения глубоких сетей**, особенно при увеличении числа слоёв.\n",
|
||
" \n",
|
||
" - Также добавлен **один слой нормализации после последнего блока декодера**, что стабилизирует выход модели.\n",
|
||
" \n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 3. GELU вместо ReLU\n",
|
||
"\n",
|
||
"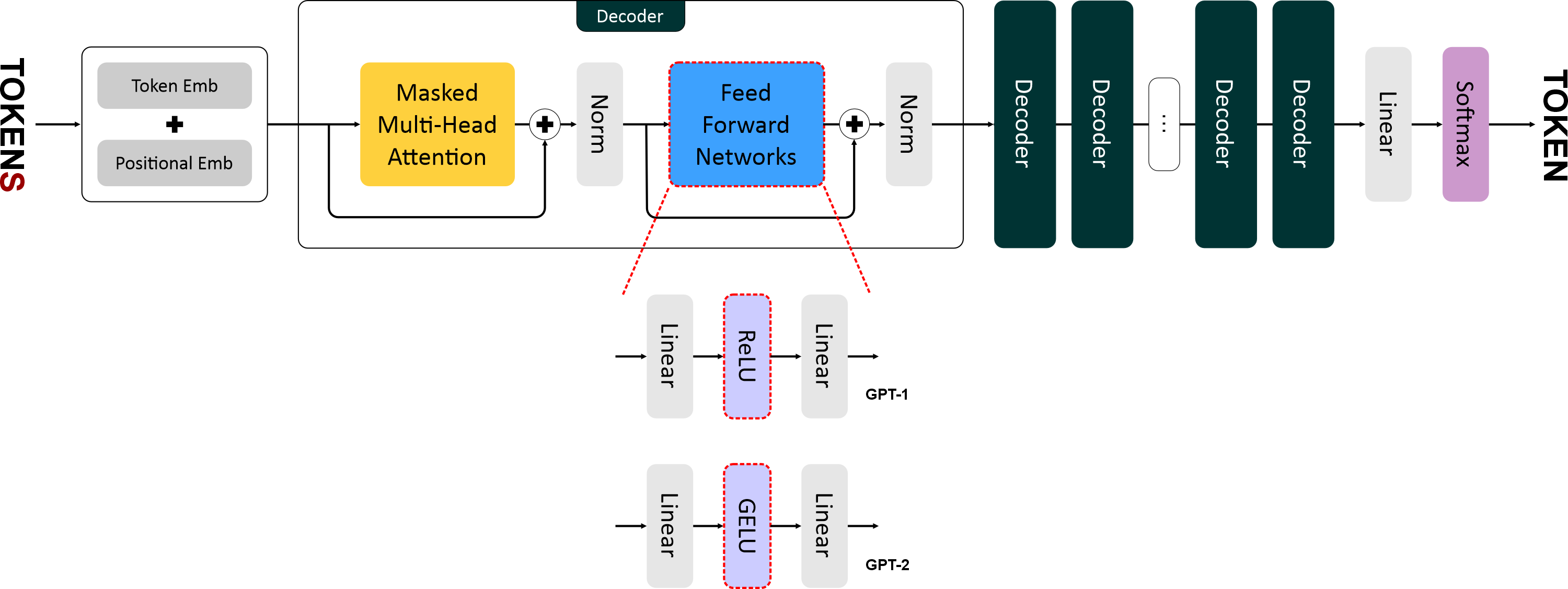\n",
|
||
"\n",
|
||
"- В GPT-1 использовалась **ReLU** в полносвязных сетях (FFN).\n",
|
||
" \n",
|
||
"- В GPT-2 применяют **GELU (Gaussian Error Linear Unit)**:\n",
|
||
"\n",
|
||
"\n",
|
||
"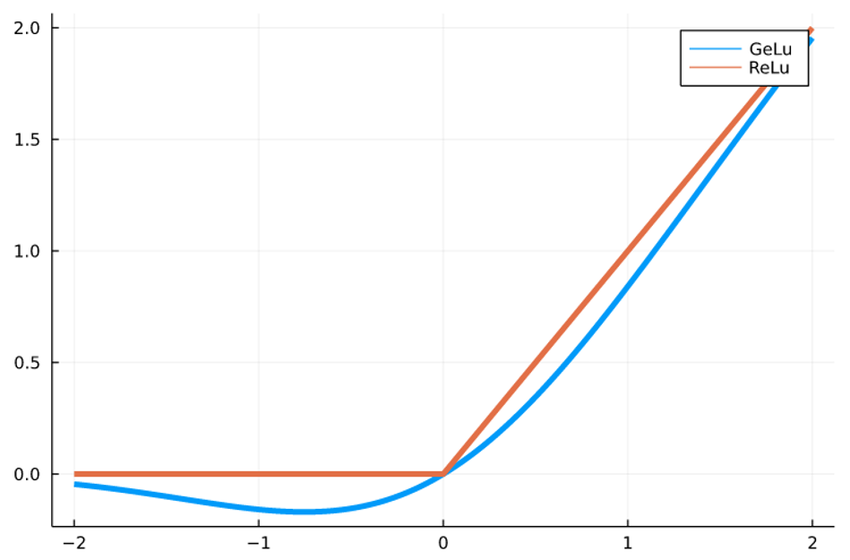\n",
|
||
" \n",
|
||
"$$ \n",
|
||
"\\text{GELU}(x) = x \\cdot \\Phi(x) \n",
|
||
"$$\n",
|
||
"\n",
|
||
"где $Phi(x)$ — функция нормального распределения.\n",
|
||
"\n",
|
||
"- GELU **плавно подавляет отрицательные значения**, создавая мягкий переход около нуля.\n",
|
||
" \n",
|
||
"- Эмпирически улучшает **скорость обучения и качество генерации** текста.\n",
|
||
" \n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 4. KV-cache (Key-Value Cache)\n",
|
||
"\n",
|
||
"- GPT-2 использует **оптимизацию вычислений при генерации текста**:\n",
|
||
" \n",
|
||
" - Ранее в GPT-1 каждый прогон модели пересчитывал **всё внимание** заново для всей последовательности.\n",
|
||
" \n",
|
||
" - KV-cache позволяет **сохранять Q, K, V для уже обработанных токенов** и обновлять только новые токены.\n",
|
||
" \n",
|
||
" - Это значительно ускоряет **генерацию длинных текстов**.\n",
|
||
" \n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 5. Tokenization и словарь\n",
|
||
"\n",
|
||
"- GPT-2 сохраняет **Byte Pair Encoding (BPE)**, но словарь **больше (50 000 токенов)**.\n",
|
||
" \n",
|
||
"- Это позволяет модели **обрабатывать редкие слова, спецсимволы и эмодзи**.\n",
|
||
" \n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 6. Маскированное внимание (Causal Self-Attention)\n",
|
||
"\n",
|
||
"- GPT-2 продолжает использовать **авторегрессионное предсказание**: каждый токен зависит только от предыдущих.\n",
|
||
" \n",
|
||
"- Отличие в **оптимизации для больших последовательностей** и увеличении числа голов внимания, что повышает способность захватывать сложные зависимости между токенами.\n",
|
||
" \n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 7. Feed-Forward Network (FFN)\n",
|
||
"\n",
|
||
"- Двухслойная FFN с **GELU** и шириной 4× размер эмбеддингов.\n",
|
||
" \n",
|
||
"- Позволяет **обрабатывать и смешивать информацию из разных голов внимания** более эффективно, чем ReLU в GPT-1.\n",
|
||
" \n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 8. Генерация текста\n",
|
||
"\n",
|
||
"- GPT-2 остаётся **авторегрессионной**, как GPT-1.\n",
|
||
" \n",
|
||
"- Улучшения:\n",
|
||
" \n",
|
||
" - KV-cache для ускорения генерации длинных последовательностей.\n",
|
||
" \n",
|
||
" - Поддержка **top-k и top-p (nucleus) sampling** для управления разнообразием текста.\n",
|
||
" \n",
|
||
" - Более длинные контексты (до 1024 токенов и более).\n",
|
||
" \n",
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 🔹 Сравнение GPT-1 и GPT-2\n",
|
||
"\n",
|
||
"|Компонент|GPT-1|GPT-2|\n",
|
||
"|---|---|---|\n",
|
||
"|Слои Decoder|12|48|\n",
|
||
"|Эмбеддинги|768|1600|\n",
|
||
"|Heads|12|25|\n",
|
||
"|Словарь|~40k|50k|\n",
|
||
"|Max Seq Len|512|1024|\n",
|
||
"|LayerNorm|Post-LN|Pre-LN + финальный LN|\n",
|
||
"|Активация FFN|ReLU|GELU|\n",
|
||
"|Генерация|Полный расчет заново|KV-cache + top-k/top-p|\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 2,
|
||
"id": "a4fba924",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"import dill\n",
|
||
"from torch import nn\n",
|
||
"import torch"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "6ed35205",
|
||
"metadata": {},
|
||
"source": [
|
||
"## BPE Tokenizator"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 3,
|
||
"id": "1a6f2914",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"class BPE:\n",
|
||
" def __init__(self, vocab_size: int):\n",
|
||
" self.vocab_size = vocab_size\n",
|
||
" self.id2token = {}\n",
|
||
" self.token2id = {}\n",
|
||
"\n",
|
||
" def fit(self, text: str):\n",
|
||
" # 1. Получаем уникальные токены (символы)\n",
|
||
" unique_tokens = sorted(set(text))\n",
|
||
" tokens = unique_tokens.copy()\n",
|
||
"\n",
|
||
" # 2. Разбиваем текст на токены-символы\n",
|
||
" sequence = list(text)\n",
|
||
"\n",
|
||
" # 3. Объединяем токены до достижения нужного размера словаря\n",
|
||
" while len(tokens) < self.vocab_size:\n",
|
||
" #print(f'len={len(tokens)} < {self.vocab_size}')\n",
|
||
" # Считаем частоты пар\n",
|
||
" pair_freq = {}\n",
|
||
" for i in range(len(sequence) - 1):\n",
|
||
" pair = (sequence[i], sequence[i + 1])\n",
|
||
" #print(f'pair = {pair}')\n",
|
||
" if pair not in pair_freq:\n",
|
||
" pair_freq[pair] = 0\n",
|
||
" pair_freq[pair] += 1\n",
|
||
"\n",
|
||
"\n",
|
||
" #print(f'pair_freq = {pair_freq}') \n",
|
||
" if not pair_freq:\n",
|
||
" break # нет пар — выходим\n",
|
||
"\n",
|
||
" #for x in pair_freq.items():\n",
|
||
" # self.debug(x, sequence)\n",
|
||
"\n",
|
||
" # Находим самую частую пару (в случае равенства — та, что встретилась первой)\n",
|
||
" most_frequent_pair = max(pair_freq.items(), key=lambda x: (x[1], -self._pair_first_index(sequence, x[0])))[0]\n",
|
||
" #print(most_frequent_pair)\n",
|
||
" # Создаем новый токен\n",
|
||
" new_token = most_frequent_pair[0] + most_frequent_pair[1]\n",
|
||
" #print(f\"new token={new_token}\")\n",
|
||
" tokens.append(new_token)\n",
|
||
" #print(f\"tokens={tokens}\")\n",
|
||
"\n",
|
||
" i = 0\n",
|
||
" new_sequence = []\n",
|
||
"\n",
|
||
" while i < len(sequence):\n",
|
||
" if i < len(sequence) - 1 and (sequence[i], sequence[i + 1]) == most_frequent_pair:\n",
|
||
" new_sequence.append(new_token)\n",
|
||
" i += 2 # пропускаем два символа — заменённую пару\n",
|
||
" else:\n",
|
||
" new_sequence.append(sequence[i])\n",
|
||
" i += 1\n",
|
||
" sequence = new_sequence\n",
|
||
" #break\n",
|
||
" \n",
|
||
" # 4. Создаем словари\n",
|
||
" self.vocab = tokens.copy()\n",
|
||
" self.token2id = dict(zip(tokens, range(self.vocab_size)))\n",
|
||
" self.id2token = dict(zip(range(self.vocab_size), tokens))\n",
|
||
"\n",
|
||
" def _pair_first_index(self, sequence, pair):\n",
|
||
" for i in range(len(sequence) - 1):\n",
|
||
" if (sequence[i], sequence[i + 1]) == pair:\n",
|
||
" return i\n",
|
||
" return float('inf') # если пара не найдена (в теории не должно случиться)\n",
|
||
"\n",
|
||
"\n",
|
||
" def encode(self, text: str):\n",
|
||
" # 1. Разбиваем текст на токены-символы\n",
|
||
" sequence = list(text)\n",
|
||
" # 2. Инициализация пустого списка токенов\n",
|
||
" tokens = []\n",
|
||
" # 3. Установить i = 0\n",
|
||
" i = 0\n",
|
||
" while i < len(text):\n",
|
||
" # 3.1 Найти все токены в словаре, начинающиеся с text[i]\n",
|
||
" start_char = text[i]\n",
|
||
" result = [token for token in self.vocab if token.startswith(start_char)]\n",
|
||
" # 3.2 Выбрать самый длинный подходящий токен\n",
|
||
" find_token = self._find_max_matching_token(text[i:], result)\n",
|
||
" if find_token is None:\n",
|
||
" # Обработка неизвестного символа\n",
|
||
" tokens.append(text[i]) # Добавляем сам символ как токен\n",
|
||
" i += 1\n",
|
||
" else:\n",
|
||
" # 3.3 Добавить токен в результат\n",
|
||
" tokens.append(find_token)\n",
|
||
" # 3.4 Увеличить i на длину токена\n",
|
||
" i += len(find_token)\n",
|
||
"\n",
|
||
" # 4. Заменить токены на их ID\n",
|
||
" return self._tokens_to_ids(tokens)\n",
|
||
"\n",
|
||
" def _find_max_matching_token(self, text: str, tokens: list):\n",
|
||
" \"\"\"Находит самый длинный токен из списка, с которого начинается текст\"\"\"\n",
|
||
" matching = [token for token in tokens if text.startswith(token)]\n",
|
||
" return max(matching, key=len) if matching else None\n",
|
||
"\n",
|
||
" def _tokens_to_ids(self, tokens):\n",
|
||
" \"\"\"Конвертирует список токенов в их ID с обработкой неизвестных токенов\"\"\"\n",
|
||
" ids = []\n",
|
||
" for token in tokens:\n",
|
||
" if token in self.token2id:\n",
|
||
" ids.append(self.token2id[token])\n",
|
||
" else:\n",
|
||
" ids.append(0) # Специальное значение\n",
|
||
" return ids\n",
|
||
"\n",
|
||
"\n",
|
||
" def decode(self, ids: list) -> str:\n",
|
||
" return ''.join(self._ids_to_tokens(ids))\n",
|
||
"\n",
|
||
" def _ids_to_tokens(self, ids: list) -> list:\n",
|
||
" \"\"\"Конвертирует список Ids в их tokens\"\"\"\n",
|
||
" tokens = []\n",
|
||
" for id in ids:\n",
|
||
" if id in self.id2token:\n",
|
||
" tokens.append(self.id2token[id])\n",
|
||
" else:\n",
|
||
" tokens.append('') # Специальное значение\n",
|
||
" return tokens\n",
|
||
"\n",
|
||
"\n",
|
||
" def save(self, filename):\n",
|
||
" with open(filename, 'wb') as f:\n",
|
||
" dill.dump(self, f)\n",
|
||
" print(f\"Объект сохранён в {filename}\")\n",
|
||
"\n",
|
||
"\n",
|
||
" @classmethod\n",
|
||
" def load(cls, filename):\n",
|
||
" with open(filename, 'rb') as f:\n",
|
||
" obj = dill.load(f)\n",
|
||
" \n",
|
||
" print(f\"Объект загружен из {filename}\")\n",
|
||
" return obj"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "9036bbb5",
|
||
"metadata": {},
|
||
"source": [
|
||
"## GPT2"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 9,
|
||
"id": "87b6504e",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"import torch\n",
|
||
"from torch import nn\n",
|
||
"import torch.nn.functional as F\n",
|
||
"from math import sqrt\n",
|
||
"import torch\n",
|
||
"from torch import nn\n",
|
||
"from torch import Tensor\n",
|
||
"\n",
|
||
"class TokenEmbeddings(nn.Module):\n",
|
||
" def __init__(self, vocab_size: int, emb_size: int):\n",
|
||
" super().__init__()\n",
|
||
" self._embedding = nn.Embedding(\n",
|
||
" num_embeddings=vocab_size,\n",
|
||
" embedding_dim=emb_size\n",
|
||
" )\n",
|
||
"\n",
|
||
" def forward(self, x: Tensor) -> Tensor:\n",
|
||
" return self._embedding(x)\n",
|
||
"\n",
|
||
" @property\n",
|
||
" def num_embeddings(self) -> int:\n",
|
||
" return self._embedding.num_embeddings\n",
|
||
"\n",
|
||
" @property\n",
|
||
" def embedding_dim(self) -> int:\n",
|
||
" return self._embedding.embedding_dim\n",
|
||
"\n",
|
||
"\n",
|
||
"import torch\n",
|
||
"from torch import nn, Tensor\n",
|
||
"\n",
|
||
"class PositionalEmbeddings(nn.Module):\n",
|
||
" def __init__(self, max_seq_len: int, emb_size: int):\n",
|
||
" super().__init__()\n",
|
||
" self.max_seq_len = max_seq_len\n",
|
||
" self.emb_size = emb_size\n",
|
||
" self.embedding = nn.Embedding(\n",
|
||
" num_embeddings=max_seq_len,\n",
|
||
" embedding_dim=emb_size\n",
|
||
" )\n",
|
||
"\n",
|
||
" def forward(self, seq_len: int, start_pos: int = 0) -> Tensor:\n",
|
||
" if seq_len < 1 or seq_len > self.max_seq_len:\n",
|
||
" raise IndexError(f\"Длина {seq_len} должна быть от 1 до {self.max_seq_len}\")\n",
|
||
" if start_pos == 0:\n",
|
||
" positions = torch.arange(seq_len, device=self.embedding.weight.device)\n",
|
||
" else:\n",
|
||
" positions = torch.arange(start=start_pos, end=start_pos + seq_len, device=self.embedding.weight.device)\n",
|
||
" return self.embedding(positions)\n",
|
||
" \n",
|
||
" \n",
|
||
"class HeadAttention(nn.Module):\n",
|
||
"\n",
|
||
" def __init__(self, emb_size: int, head_size: int, max_seq_len: int):\n",
|
||
" super().__init__()\n",
|
||
" self._emb_size = emb_size\n",
|
||
" self._head_size = head_size\n",
|
||
" self._max_seq_len = max_seq_len\n",
|
||
"\n",
|
||
" self._k = nn.Linear(emb_size, head_size)\n",
|
||
" self._q = nn.Linear(emb_size, head_size)\n",
|
||
" self._v = nn.Linear(emb_size, head_size)\n",
|
||
"\n",
|
||
" mask = torch.tril(torch.ones(max_seq_len, max_seq_len))\n",
|
||
" self.register_buffer('_tril_mask', mask.bool() if hasattr(torch, 'bool') else mask.byte())\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor, use_cache: bool = True, cache: tuple = None) -> tuple:\n",
|
||
" seq_len = x.shape[1]\n",
|
||
" if seq_len > self._max_seq_len:\n",
|
||
" raise ValueError(f\"Длина последовательности {seq_len} превышает максимум {self._max_seq_len}\")\n",
|
||
"\n",
|
||
" k = self._k(x) # [B, T, hs]\n",
|
||
" q = self._q(x) # [B, T, hs]\n",
|
||
" v = self._v(x) # [B, T, hs]\n",
|
||
"\n",
|
||
" if cache is not None:\n",
|
||
" k_cache, v_cache = cache\n",
|
||
" k = torch.cat([k_cache, k], dim=1) # [B, cache_len + T, hs]\n",
|
||
" v = torch.cat([v_cache, v], dim=1) # [B, cache_len + T, hs]\n",
|
||
" \n",
|
||
" scores = q @ k.transpose(-2, -1) / sqrt(self._head_size)\n",
|
||
" \n",
|
||
" if cache is None:\n",
|
||
" scores = scores.masked_fill(~self._tril_mask[:seq_len, :seq_len], float('-inf'))\n",
|
||
" \n",
|
||
" weights = F.softmax(scores, dim=-1)\n",
|
||
" x_out = weights @ v # [B, T, hs]\n",
|
||
"\n",
|
||
" if use_cache is True:\n",
|
||
" return (x_out, (k, v))\n",
|
||
" else:\n",
|
||
" return (x_out, None)\n",
|
||
" \n",
|
||
"from torch import nn\n",
|
||
"import torch\n",
|
||
"import math\n",
|
||
"\n",
|
||
"class MultiHeadAttention(nn.Module):\n",
|
||
" def __init__(self, num_heads: int, emb_size: int, head_size: int, max_seq_len: int, dropout: float = 0.1):\n",
|
||
"\n",
|
||
" super().__init__()\n",
|
||
" self._heads = nn.ModuleList([\n",
|
||
" HeadAttention(\n",
|
||
" emb_size=emb_size, \n",
|
||
" head_size=head_size, \n",
|
||
" max_seq_len=max_seq_len\n",
|
||
" ) for _ in range(num_heads)\n",
|
||
" ])\n",
|
||
" self._layer = nn.Linear(head_size * num_heads, emb_size)\n",
|
||
" self._dropout = nn.Dropout(dropout)\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor, mask: torch.Tensor = None, use_cache: bool = True, cache: list = None):\n",
|
||
"\n",
|
||
" attention_results = []\n",
|
||
" for i, head in enumerate(self._heads):\n",
|
||
" head_cache = cache[i] if cache is not None else None\n",
|
||
" result = head(x, use_cache=use_cache, cache=head_cache)\n",
|
||
" attention_results.append(result)\n",
|
||
" \n",
|
||
" outputs, caches = zip(*attention_results)\n",
|
||
" attention_outputs = list(outputs)\n",
|
||
" kv_caches = list(caches)\n",
|
||
" \n",
|
||
" concatenated_attention = torch.cat(attention_outputs, dim=-1)\n",
|
||
"\n",
|
||
" projected_output = self._layer(concatenated_attention)\n",
|
||
" \n",
|
||
" final_output = self._dropout(projected_output)\n",
|
||
" \n",
|
||
" if use_cache is True:\n",
|
||
" return (final_output, kv_caches)\n",
|
||
" else:\n",
|
||
" return (final_output, None)\n",
|
||
"\n",
|
||
"\n",
|
||
"class GELU(nn.Module):\n",
|
||
" def __init__(self):\n",
|
||
" super().__init__()\n",
|
||
" self.sqrt_2_over_pi = torch.sqrt(torch.tensor(2.0) / math.pi)\n",
|
||
" \n",
|
||
" def forward(self, x: torch.Tensor) -> torch.Tensor:\n",
|
||
" return 0.5 * x * (1 + torch.tanh(\n",
|
||
" self.sqrt_2_over_pi * (x + 0.044715 * torch.pow(x, 3))\n",
|
||
" ))\n",
|
||
"\n",
|
||
"class FeedForward(nn.Module):\n",
|
||
"\n",
|
||
" def __init__(self, emb_size: int, dropout: float = 0.1):\n",
|
||
" super().__init__()\n",
|
||
" self._layer1 = nn.Linear(emb_size, emb_size * 4)\n",
|
||
" self._gelu = GELU()\n",
|
||
" self._layer2 = nn.Linear(emb_size * 4, emb_size)\n",
|
||
" self._dropout = nn.Dropout(dropout)\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor):\n",
|
||
" input_dtype = x.dtype\n",
|
||
" \n",
|
||
" if input_dtype != self._layer1.weight.dtype:\n",
|
||
" self._layer1 = self._layer1.to(dtype=input_dtype)\n",
|
||
" self._layer2 = self._layer2.to(dtype=input_dtype)\n",
|
||
" \n",
|
||
" x = self._layer1(x)\n",
|
||
" x = self._gelu(x)\n",
|
||
" x = self._layer2(x)\n",
|
||
" return self._dropout(x)\n",
|
||
" \n",
|
||
"class Decoder(nn.Module):\n",
|
||
" def __init__(self, \n",
|
||
" num_heads: int,\n",
|
||
" emb_size: int,\n",
|
||
" head_size: int,\n",
|
||
" max_seq_len: int,\n",
|
||
" dropout: float = 0.1\n",
|
||
" ):\n",
|
||
" super().__init__()\n",
|
||
" self._heads = MultiHeadAttention(\n",
|
||
" num_heads=num_heads, \n",
|
||
" emb_size=emb_size, \n",
|
||
" head_size=head_size, \n",
|
||
" max_seq_len=max_seq_len, \n",
|
||
" dropout=dropout\n",
|
||
" )\n",
|
||
" self._ff = FeedForward(emb_size=emb_size, dropout=dropout)\n",
|
||
" self._norm1 = nn.LayerNorm(emb_size)\n",
|
||
" self._norm2 = nn.LayerNorm(emb_size)\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor, mask: torch.Tensor = None, use_cache: bool = True, cache: list = None) -> torch.Tensor:\n",
|
||
" norm1_out = self._norm1(x)\n",
|
||
" attention, kv_caches = self._heads(norm1_out, mask, use_cache=use_cache, cache=cache)\n",
|
||
" out = attention + x\n",
|
||
" \n",
|
||
" norm2_out = self._norm2(out)\n",
|
||
" ffn_out = self._ff(norm2_out)\n",
|
||
"\n",
|
||
" if use_cache is True:\n",
|
||
" return (ffn_out + out, kv_caches)\n",
|
||
" else:\n",
|
||
" return (ffn_out + out, None)\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"from torch import nn\n",
|
||
"import torch\n",
|
||
"import torch.nn.functional as F\n",
|
||
"\n",
|
||
"class GPT2(nn.Module):\n",
|
||
" def __init__(self,\n",
|
||
" vocab_size: int,\n",
|
||
" max_seq_len: int,\n",
|
||
" emb_size: int,\n",
|
||
" num_heads: int,\n",
|
||
" head_size: int,\n",
|
||
" num_layers: int,\n",
|
||
" dropout: float = 0.1,\n",
|
||
" device: str = 'cpu'\n",
|
||
" ):\n",
|
||
" super().__init__()\n",
|
||
" self._vocab_size = vocab_size\n",
|
||
" self._max_seq_len = max_seq_len\n",
|
||
" self._emb_size = emb_size\n",
|
||
" self._num_heads = num_heads\n",
|
||
" self._head_size = head_size\n",
|
||
" self._num_layers = num_layers\n",
|
||
" self._dropout = dropout\n",
|
||
" self._device = device\n",
|
||
" \n",
|
||
" self.validation_loss = None\n",
|
||
"\n",
|
||
" # Инициализация слоев\n",
|
||
" self._token_embeddings = TokenEmbeddings(\n",
|
||
" vocab_size=vocab_size, \n",
|
||
" emb_size=emb_size\n",
|
||
" )\n",
|
||
" self._position_embeddings = PositionalEmbeddings(\n",
|
||
" max_seq_len=max_seq_len, \n",
|
||
" emb_size=emb_size\n",
|
||
" )\n",
|
||
" self._dropout = nn.Dropout(dropout)\n",
|
||
" self._decoders = nn.ModuleList([Decoder(\n",
|
||
" num_heads=num_heads,\n",
|
||
" emb_size=emb_size,\n",
|
||
" head_size=head_size,\n",
|
||
" max_seq_len=max_seq_len,\n",
|
||
" dropout=dropout \n",
|
||
" ) for _ in range(num_layers)])\n",
|
||
" self._norm = nn.LayerNorm(emb_size)\n",
|
||
" self._linear = nn.Linear(emb_size, vocab_size)\n",
|
||
"\n",
|
||
" def forward(self, x: torch.Tensor, use_cache: bool = True, cache: list = None) -> tuple:\n",
|
||
" # Проверка длины последовательности (только при отсутствии кэша)\n",
|
||
" if cache is None and x.size(1) > self._max_seq_len:\n",
|
||
" raise ValueError(f\"Длина последовательности {x.size(1)} превышает максимальную {self.max_seq_len}\")\n",
|
||
" \n",
|
||
" \n",
|
||
" # Вычисление start_pos из кэша (если кэш передан)\n",
|
||
" if cache is not None:\n",
|
||
" # При кэше обрабатываем только один токен (последний)\n",
|
||
" seq_len = 1\n",
|
||
" # Вычисляем start_pos из самого нижнего уровня кэша\n",
|
||
" if cache and cache[0] and cache[0][0]:\n",
|
||
" key_cache, _ = cache[0][0] # Первый декодер, первая голова\n",
|
||
" start_pos = key_cache.size(1) # cache_len\n",
|
||
" else:\n",
|
||
" start_pos = 0\n",
|
||
" else:\n",
|
||
" # Без кэша работаем как раньше\n",
|
||
" start_pos = 0\n",
|
||
" seq_len = x.size(1)\n",
|
||
"\n",
|
||
" # Эмбеддинги токенов и позиций\n",
|
||
" tok_out = self._token_embeddings(x) # [batch, seq_len, emb_size]\n",
|
||
" pos_out = self._position_embeddings(seq_len, start_pos=start_pos) # [seq_len, emb_size]\n",
|
||
" \n",
|
||
" # Комбинирование\n",
|
||
" out = self._dropout(tok_out + pos_out.unsqueeze(0)) # [batch, seq_len, emb_size]\n",
|
||
" \n",
|
||
" # Стек декодеров с передачей кэша\n",
|
||
" new_cache = []\n",
|
||
" for i, decoder in enumerate(self._decoders):\n",
|
||
" decoder_cache = cache[i] if cache is not None else None\n",
|
||
" decoder_result = decoder(out, use_cache=use_cache, cache=decoder_cache)\n",
|
||
"\n",
|
||
" # Извлекаем результат из кортежа\n",
|
||
" if use_cache:\n",
|
||
" out, decoder_new_cache = decoder_result\n",
|
||
" new_cache.append(decoder_new_cache)\n",
|
||
" else:\n",
|
||
" out = decoder_result[0]\n",
|
||
"\n",
|
||
" out = self._norm(out)\n",
|
||
" logits = self._linear(out)\n",
|
||
" \n",
|
||
" # Возвращаем результат с учетом use_cache\n",
|
||
" if use_cache:\n",
|
||
" return (logits, new_cache)\n",
|
||
" else:\n",
|
||
" return (logits, None)\n",
|
||
"\n",
|
||
" def generate(self,\n",
|
||
" x: torch.Tensor, \n",
|
||
" max_new_tokens: int, \n",
|
||
" do_sample: bool,\n",
|
||
" temperature: float = 1.0,\n",
|
||
" top_k: int = None,\n",
|
||
" top_p: float = None,\n",
|
||
" use_cache: bool = True\n",
|
||
" ) -> torch.Tensor:\n",
|
||
" cache = None\n",
|
||
"\n",
|
||
" for _ in range(max_new_tokens):\n",
|
||
" if use_cache and cache is not None:\n",
|
||
" # Используем кэш - передаем только последний токен\n",
|
||
" x_input = x[:, -1:] # [batch_size, 1]\n",
|
||
" else:\n",
|
||
" # Первая итерация или кэш отключен - передаем всю последовательность\n",
|
||
" x_input = x\n",
|
||
" \n",
|
||
" # Прямой проход с кэшем\n",
|
||
" logits, new_cache = self.forward(x_input, use_cache=use_cache, cache=cache)\n",
|
||
" \n",
|
||
" # Обновляем кэш для следующей итерации\n",
|
||
" if use_cache:\n",
|
||
" cache = new_cache\n",
|
||
"\n",
|
||
" last_logits = logits[:, -1, :] # [batch_size, vocab_size]\n",
|
||
"\n",
|
||
" # Масштабируем логиты температурой\n",
|
||
" if temperature > 0:\n",
|
||
" logits_scaled = last_logits / temperature\n",
|
||
" else:\n",
|
||
" logits_scaled = last_logits\n",
|
||
"\n",
|
||
" if do_sample == True and top_k != None:\n",
|
||
" _, topk_indices = torch.topk(logits_scaled, top_k, dim=-1)\n",
|
||
"\n",
|
||
" # # Заменим все НЕ top-k логиты на -inf\n",
|
||
" masked_logits = logits_scaled.clone()\n",
|
||
" vocab_size = logits_scaled.size(-1)\n",
|
||
"\n",
|
||
" # создаём маску: 1, если токен НЕ в topk_indices\n",
|
||
" mask = torch.ones_like(logits_scaled, dtype=torch.uint8)\n",
|
||
" mask.scatter_(1, topk_indices, 0) # 0 там, где top-k индексы\n",
|
||
" masked_logits[mask.byte()] = float('-inf')\n",
|
||
"\n",
|
||
" logits_scaled = masked_logits\n",
|
||
"\n",
|
||
" if do_sample == True and top_p != None:\n",
|
||
" # 1. Применим softmax, чтобы получить вероятности:\n",
|
||
" probs = F.softmax(logits_scaled, dim=-1) # [B, vocab_size]\n",
|
||
" # 2. Отсортируем токены по убыванию вероятностей:\n",
|
||
" sorted_probs, sorted_indices = torch.sort(probs, descending=True, dim=-1)\n",
|
||
" # 3. Посчитаем кумулятивную сумму вероятностей:\n",
|
||
" cum_probs = torch.cumsum(sorted_probs, dim=-1) # [B, vocab_size]\n",
|
||
" # 4. Определим маску: оставить токены, пока сумма < top_p\n",
|
||
" sorted_mask = (cum_probs <= top_p).byte() # [B, vocab_size]\n",
|
||
" # Гарантируем, что хотя бы первый токен останется\n",
|
||
" sorted_mask[:, 0] = 1\n",
|
||
" # 5. Преобразуем маску обратно в оригинальный порядок:\n",
|
||
" # Создаём полную маску из 0\n",
|
||
" mask = torch.zeros_like(probs, dtype=torch.uint8)\n",
|
||
" # Устанавливаем 1 в местах нужных токенов\n",
|
||
" mask.scatter_(dim=1, index=sorted_indices, src=sorted_mask)\n",
|
||
" # 6. Зануляем логиты токенов вне топ-p:\n",
|
||
" logits_scaled[~mask] = float('-inf')\n",
|
||
"\n",
|
||
" # 4. Применяем Softmax\n",
|
||
" probs = F.softmax(logits_scaled, dim=-1) # [batch_size, vocab_size]\n",
|
||
"\n",
|
||
"\n",
|
||
" if do_sample == True:\n",
|
||
" # 5. Если do_sample равен True, то отбираем токен случайно с помощью torch.multinomial\n",
|
||
" next_token = torch.multinomial(probs, num_samples=1) # [batch_size, 1]\n",
|
||
" else:\n",
|
||
" # 5. Если do_sample равен False, то выбираем токен с максимальной вероятностью\n",
|
||
" next_token = torch.argmax(probs, dim=-1, keepdim=True) # [batch_size, 1]\n",
|
||
" \n",
|
||
" # 6. Добавляем его к последовательности\n",
|
||
" x = torch.cat([x, next_token], dim=1) # [batch_size, seq_len+1]\n",
|
||
" return x\n",
|
||
"\n",
|
||
" def save(self, path):\n",
|
||
" torch.save({\n",
|
||
" 'model_state_dict': self.state_dict(),\n",
|
||
" 'vocab_size': self._vocab_size,\n",
|
||
" 'max_seq_len': self._max_seq_len,\n",
|
||
" 'emb_size': self._emb_size,\n",
|
||
" 'num_heads': self._num_heads,\n",
|
||
" 'head_size': self._head_size,\n",
|
||
" 'num_layers': self._num_layers\n",
|
||
" }, path)\n",
|
||
"\n",
|
||
" @classmethod\n",
|
||
" def load(cls, path, device):\n",
|
||
" checkpoint = torch.load(path, map_location=device)\n",
|
||
" model = cls(\n",
|
||
" vocab_size=checkpoint['vocab_size'],\n",
|
||
" max_seq_len=checkpoint['max_seq_len'],\n",
|
||
" emb_size=checkpoint['emb_size'],\n",
|
||
" num_heads=checkpoint['num_heads'],\n",
|
||
" head_size=checkpoint['head_size'],\n",
|
||
" num_layers=checkpoint['num_layers']\n",
|
||
" )\n",
|
||
" model.load_state_dict(checkpoint['model_state_dict'])\n",
|
||
" model.to(device)\n",
|
||
" return model\n",
|
||
"\n",
|
||
" @property\n",
|
||
" def max_seq_len(self) -> int:\n",
|
||
" return self._max_seq_len"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "888d1a1c",
|
||
"metadata": {},
|
||
"source": [
|
||
"## 2. Обучение GPT-2\n",
|
||
"\n",
|
||
"GPT-2 обучается в два этапа:\n",
|
||
"\n",
|
||
"- 1️⃣ **Предобучение (Unsupervised Pretraining)** \n",
|
||
"- 2️⃣ **Дообучение (Supervised Fine-Tuning)**\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "b47966ba",
|
||
"metadata": {},
|
||
"source": [
|
||
"\n",
|
||
"\n",
|
||
"### 5.1 Предобучение\n",
|
||
"\n",
|
||
"На первом этапе модель обучается без разметки: она получает большой корпус текстов и учится **предсказывать следующий токен** по предыдущим.\n",
|
||
"\n",
|
||
"Функция потерь:\n",
|
||
"$$\n",
|
||
"L = - \\sum_{t=1}^{T} \\log P(x_t | x_1, x_2, ..., x_{t-1})\n",
|
||
"$$\n",
|
||
"\n",
|
||
"Таким образом, модель учится строить вероятностную модель языка, \"угадывая\" продолжение текста.\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "12e4624e",
|
||
"metadata": {},
|
||
"source": [
|
||
"Во время **предобучения** GPT-1 учится **предсказывать следующий токен** (language modeling task). \n",
|
||
"Формально: \n",
|
||
"$$ \n",
|
||
"P(x_t ,|, x_1, x_2, \\dots, x_{t-1}) \n",
|
||
"$$ \n",
|
||
"То есть, если на вход подаётся предложение `\"I love deep\"`, модель должна предсказать `\"learning\"`.\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "87dcc10e",
|
||
"metadata": {},
|
||
"source": [
|
||
"### ✅ 5.1.1 Подготовка данных\n",
|
||
"\n",
|
||
"Создадим **датасет** на основе BPE-токенизатора:"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 10,
|
||
"id": "632eec77",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"import torch\n",
|
||
"from torch.utils.data import Dataset, DataLoader\n",
|
||
"\n",
|
||
"class GPTDataset(Dataset):\n",
|
||
" def __init__(self, text: str, bpe: BPE, block_size: int):\n",
|
||
" self.bpe = bpe\n",
|
||
" self.block_size = block_size\n",
|
||
" self.data = bpe.encode(text)\n",
|
||
" \n",
|
||
" def __len__(self):\n",
|
||
" return len(self.data) - self.block_size\n",
|
||
"\n",
|
||
" def __getitem__(self, idx):\n",
|
||
" x = torch.tensor(self.data[idx:idx+self.block_size], dtype=torch.long)\n",
|
||
" y = torch.tensor(self.data[idx+1:idx+self.block_size+1], dtype=torch.long)\n",
|
||
" return x, y"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "bb5d83d8",
|
||
"metadata": {},
|
||
"source": [
|
||
"- `x` — входная последовательность токенов\n",
|
||
" \n",
|
||
"- `y` — та же последовательность, но сдвинутая на один токен вперёд (цель)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "24de37be",
|
||
"metadata": {},
|
||
"source": [
|
||
"### ✅ 5.1.2 Цикл обучения\n",
|
||
"\n",
|
||
"Для обучения создадим функцию:"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 15,
|
||
"id": "8003ea24",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"import torch.nn.functional as F\n",
|
||
"from torch import optim\n",
|
||
"\n",
|
||
"def train_gpt(model, dataset, epochs=5, batch_size=32, lr=3e-4, device='cpu'):\n",
|
||
" dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)\n",
|
||
" optimizer = optim.AdamW(model.parameters(), lr=lr)\n",
|
||
"\n",
|
||
" model.to(device)\n",
|
||
" model.train()\n",
|
||
"\n",
|
||
" for epoch in range(epochs):\n",
|
||
" total_loss = 0\n",
|
||
" for x, y in dataloader:\n",
|
||
" x, y = x.to(device), y.to(device)\n",
|
||
"\n",
|
||
" # Прямой проход\n",
|
||
" logits, _ = model(x, use_cache=False) # [B, T, vocab_size]\n",
|
||
"\n",
|
||
" # Перестроим выход под CrossEntropy\n",
|
||
" loss = F.cross_entropy(logits.view(-1, logits.size(-1)), y.view(-1))\n",
|
||
"\n",
|
||
" # Обратное распространение\n",
|
||
" optimizer.zero_grad()\n",
|
||
" loss.backward()\n",
|
||
" optimizer.step()\n",
|
||
"\n",
|
||
" total_loss += loss.item()\n",
|
||
"\n",
|
||
" avg_loss = total_loss / len(dataloader)\n",
|
||
" print(f\"Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}\")\n",
|
||
"\n",
|
||
" return model"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "3c351b56",
|
||
"metadata": {},
|
||
"source": [
|
||
"### ✅ 5.1.3 Пример запуска\n",
|
||
"\n",
|
||
"\n",
|
||
"**🧠 Конфигурация GPT-2 Mini (официальная OpenAI)**\n",
|
||
"\n",
|
||
"\n",
|
||
"| Параметр | Значение | Описание |\n",
|
||
"| --------------- | -------- | --------------------------------------------- |\n",
|
||
"| **vocab_size** | `50257` | Размер словаря (BPE токенизатор OpenAI) |\n",
|
||
"| **max_seq_len** | `512` | Максимальная длина входной последовательности |\n",
|
||
"| **emb_size** | `256` | Размер эмбеддингов (векторное пространство) |\n",
|
||
"| **num_heads** | `4` | Количество голов в multi-head attention |\n",
|
||
"| **head_size** | `64` | Размерность одной головы внимания (768 / 12) |\n",
|
||
"| **num_layers** | `4` | Количество блоков (декодеров) |\n",
|
||
"| **dropout** | `0.1` | Вероятность дропаута |\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 30,
|
||
"id": "dd700a5c",
|
||
"metadata": {},
|
||
"outputs": [
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"Dataset length: 20\n",
|
||
"Epoch 1/100, Loss: 4.0049\n",
|
||
"Epoch 2/100, Loss: 2.2952\n",
|
||
"Epoch 3/100, Loss: 1.2738\n",
|
||
"Epoch 4/100, Loss: 0.6864\n",
|
||
"Epoch 5/100, Loss: 0.4070\n",
|
||
"Epoch 6/100, Loss: 0.3075\n",
|
||
"Epoch 7/100, Loss: 0.2422\n",
|
||
"Epoch 8/100, Loss: 0.1881\n",
|
||
"Epoch 9/100, Loss: 0.1484\n",
|
||
"Epoch 10/100, Loss: 0.1258\n",
|
||
"Epoch 11/100, Loss: 0.1153\n",
|
||
"Epoch 12/100, Loss: 0.1039\n",
|
||
"Epoch 13/100, Loss: 0.0852\n",
|
||
"Epoch 14/100, Loss: 0.0897\n",
|
||
"Epoch 15/100, Loss: 0.0799\n",
|
||
"Epoch 16/100, Loss: 0.0741\n",
|
||
"Epoch 17/100, Loss: 0.0809\n",
|
||
"Epoch 18/100, Loss: 0.0680\n",
|
||
"Epoch 19/100, Loss: 0.0717\n",
|
||
"Epoch 20/100, Loss: 0.0648\n",
|
||
"Epoch 21/100, Loss: 0.0684\n",
|
||
"Epoch 22/100, Loss: 0.0654\n",
|
||
"Epoch 23/100, Loss: 0.0631\n",
|
||
"Epoch 24/100, Loss: 0.0686\n",
|
||
"Epoch 25/100, Loss: 0.0633\n",
|
||
"Epoch 26/100, Loss: 0.0624\n",
|
||
"Epoch 27/100, Loss: 0.0618\n",
|
||
"Epoch 28/100, Loss: 0.0686\n",
|
||
"Epoch 29/100, Loss: 0.0613\n",
|
||
"Epoch 30/100, Loss: 0.0564\n",
|
||
"Epoch 31/100, Loss: 0.0587\n",
|
||
"Epoch 32/100, Loss: 0.0696\n",
|
||
"Epoch 33/100, Loss: 0.0574\n",
|
||
"Epoch 34/100, Loss: 0.0594\n",
|
||
"Epoch 35/100, Loss: 0.0556\n",
|
||
"Epoch 36/100, Loss: 0.0630\n",
|
||
"Epoch 37/100, Loss: 0.0527\n",
|
||
"Epoch 38/100, Loss: 0.0644\n",
|
||
"Epoch 39/100, Loss: 0.0570\n",
|
||
"Epoch 40/100, Loss: 0.0513\n",
|
||
"Epoch 41/100, Loss: 0.0614\n",
|
||
"Epoch 42/100, Loss: 0.0591\n",
|
||
"Epoch 43/100, Loss: 0.0454\n",
|
||
"Epoch 44/100, Loss: 0.0499\n",
|
||
"Epoch 45/100, Loss: 0.0506\n",
|
||
"Epoch 46/100, Loss: 0.0627\n",
|
||
"Epoch 47/100, Loss: 0.0522\n",
|
||
"Epoch 48/100, Loss: 0.0545\n",
|
||
"Epoch 49/100, Loss: 0.0504\n",
|
||
"Epoch 50/100, Loss: 0.0512\n",
|
||
"Epoch 51/100, Loss: 0.0525\n",
|
||
"Epoch 52/100, Loss: 0.0528\n",
|
||
"Epoch 53/100, Loss: 0.0507\n",
|
||
"Epoch 54/100, Loss: 0.0596\n",
|
||
"Epoch 55/100, Loss: 0.0507\n",
|
||
"Epoch 56/100, Loss: 0.0581\n",
|
||
"Epoch 57/100, Loss: 0.0516\n",
|
||
"Epoch 58/100, Loss: 0.0556\n",
|
||
"Epoch 59/100, Loss: 0.0545\n",
|
||
"Epoch 60/100, Loss: 0.0512\n",
|
||
"Epoch 61/100, Loss: 0.0455\n",
|
||
"Epoch 62/100, Loss: 0.0492\n",
|
||
"Epoch 63/100, Loss: 0.0467\n",
|
||
"Epoch 64/100, Loss: 0.0478\n",
|
||
"Epoch 65/100, Loss: 0.0471\n",
|
||
"Epoch 66/100, Loss: 0.0539\n",
|
||
"Epoch 67/100, Loss: 0.0529\n",
|
||
"Epoch 68/100, Loss: 0.0573\n",
|
||
"Epoch 69/100, Loss: 0.0515\n",
|
||
"Epoch 70/100, Loss: 0.0451\n",
|
||
"Epoch 71/100, Loss: 0.0483\n",
|
||
"Epoch 72/100, Loss: 0.0536\n",
|
||
"Epoch 73/100, Loss: 0.0526\n",
|
||
"Epoch 74/100, Loss: 0.0479\n",
|
||
"Epoch 75/100, Loss: 0.0480\n",
|
||
"Epoch 76/100, Loss: 0.0447\n",
|
||
"Epoch 77/100, Loss: 0.0441\n",
|
||
"Epoch 78/100, Loss: 0.0502\n",
|
||
"Epoch 79/100, Loss: 0.0486\n",
|
||
"Epoch 80/100, Loss: 0.0515\n",
|
||
"Epoch 81/100, Loss: 0.0478\n",
|
||
"Epoch 82/100, Loss: 0.0460\n",
|
||
"Epoch 83/100, Loss: 0.0518\n",
|
||
"Epoch 84/100, Loss: 0.0492\n",
|
||
"Epoch 85/100, Loss: 0.0459\n",
|
||
"Epoch 86/100, Loss: 0.0501\n",
|
||
"Epoch 87/100, Loss: 0.0502\n",
|
||
"Epoch 88/100, Loss: 0.0519\n",
|
||
"Epoch 89/100, Loss: 0.0442\n",
|
||
"Epoch 90/100, Loss: 0.0473\n",
|
||
"Epoch 91/100, Loss: 0.0429\n",
|
||
"Epoch 92/100, Loss: 0.0469\n",
|
||
"Epoch 93/100, Loss: 0.0471\n",
|
||
"Epoch 94/100, Loss: 0.0458\n",
|
||
"Epoch 95/100, Loss: 0.0484\n",
|
||
"Epoch 96/100, Loss: 0.0417\n",
|
||
"Epoch 97/100, Loss: 0.0491\n",
|
||
"Epoch 98/100, Loss: 0.0528\n",
|
||
"Epoch 99/100, Loss: 0.0476\n",
|
||
"Epoch 100/100, Loss: 0.0433\n"
|
||
]
|
||
},
|
||
{
|
||
"data": {
|
||
"text/plain": [
|
||
"GPT2(\n",
|
||
" (_token_embeddings): TokenEmbeddings(\n",
|
||
" (_embedding): Embedding(100, 256)\n",
|
||
" )\n",
|
||
" (_position_embeddings): PositionalEmbeddings(\n",
|
||
" (embedding): Embedding(512, 256)\n",
|
||
" )\n",
|
||
" (_dropout): Dropout(p=0.1, inplace=False)\n",
|
||
" (_decoders): ModuleList(\n",
|
||
" (0-3): 4 x Decoder(\n",
|
||
" (_heads): MultiHeadAttention(\n",
|
||
" (_heads): ModuleList(\n",
|
||
" (0-3): 4 x HeadAttention(\n",
|
||
" (_k): Linear(in_features=256, out_features=64, bias=True)\n",
|
||
" (_q): Linear(in_features=256, out_features=64, bias=True)\n",
|
||
" (_v): Linear(in_features=256, out_features=64, bias=True)\n",
|
||
" )\n",
|
||
" )\n",
|
||
" (_layer): Linear(in_features=256, out_features=256, bias=True)\n",
|
||
" (_dropout): Dropout(p=0.1, inplace=False)\n",
|
||
" )\n",
|
||
" (_ff): FeedForward(\n",
|
||
" (_layer1): Linear(in_features=256, out_features=1024, bias=True)\n",
|
||
" (_gelu): GELU()\n",
|
||
" (_layer2): Linear(in_features=1024, out_features=256, bias=True)\n",
|
||
" (_dropout): Dropout(p=0.1, inplace=False)\n",
|
||
" )\n",
|
||
" (_norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)\n",
|
||
" (_norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)\n",
|
||
" )\n",
|
||
" )\n",
|
||
" (_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)\n",
|
||
" (_linear): Linear(in_features=256, out_features=100, bias=True)\n",
|
||
")"
|
||
]
|
||
},
|
||
"execution_count": 30,
|
||
"metadata": {},
|
||
"output_type": "execute_result"
|
||
}
|
||
],
|
||
"source": [
|
||
"# 1. Исходный текст\n",
|
||
"text = \"Deep learning is amazing. Transformers changed the world. Attention is all you need. GPT models revolutionized NLP.\"\n",
|
||
"\n",
|
||
"# 2. Обучаем токенизатор\n",
|
||
"bpe = BPE(vocab_size=100)\n",
|
||
"bpe.fit(text)\n",
|
||
"\n",
|
||
"# 3. Создаем датасет\n",
|
||
"dataset = GPTDataset(text, bpe, block_size=8)\n",
|
||
"print(f\"Dataset length: {len(dataset)}\")\n",
|
||
"\n",
|
||
"# 4. Инициализируем модель\n",
|
||
"gpt = GPT2(\n",
|
||
" vocab_size=len(bpe.vocab), # размер словаря BPE\n",
|
||
" max_seq_len=512, # GPT-2 использует контекст в 512 токена\n",
|
||
" emb_size=256, # размер эмбеддингов\n",
|
||
" num_heads=4, # количество голов внимания\n",
|
||
" head_size=64, # размер каждой головы (256 / 4)\n",
|
||
" num_layers=4, # количество блоков Transformer\n",
|
||
" dropout=0.1 # стандартный dropout GPT-2\n",
|
||
")\n",
|
||
"\n",
|
||
"# 5. Обучаем\n",
|
||
"train_gpt(gpt, dataset, epochs=100, batch_size=4)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "c3714dfc",
|
||
"metadata": {},
|
||
"source": [
|
||
"\n",
|
||
"---\n",
|
||
"\n",
|
||
"### 5.2 Дообучение\n",
|
||
"\n",
|
||
"После предобучения GPT-1 уже знает структуру и грамматику языка. \n",
|
||
"На втором этапе она дообучается на конкретных задачах (например, классификация, QA) с помощью размеченных данных.\n",
|
||
"\n",
|
||
"Технически это почти то же обучение, только:\n",
|
||
"\n",
|
||
"- Загружаем модель с уже обученными весами.\n",
|
||
"- Используем новые данные.\n",
|
||
"- Можно уменьшить скорость обучения.\n",
|
||
"- Иногда замораживают часть слоёв (например, эмбеддинги).\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 31,
|
||
"id": "4afd7733",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"def fine_tune_gpt(model, dataset, epochs=3, batch_size=16, lr=1e-5, device='cpu', freeze_embeddings=True):\n",
|
||
" if freeze_embeddings:\n",
|
||
" for param in model._token_embeddings.parameters():\n",
|
||
" param.requires_grad = False\n",
|
||
" for param in model._position_embeddings.parameters():\n",
|
||
" param.requires_grad = False\n",
|
||
"\n",
|
||
" dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)\n",
|
||
" optimizer = optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=lr)\n",
|
||
"\n",
|
||
" model.to(device)\n",
|
||
" model.train()\n",
|
||
"\n",
|
||
" for epoch in range(epochs):\n",
|
||
" total_loss = 0\n",
|
||
" for x, y in dataloader:\n",
|
||
" x, y = x.to(device), y.to(device)\n",
|
||
" logits, _ = model(x, use_cache=False)\n",
|
||
" loss = F.cross_entropy(logits.view(-1, logits.size(-1)), y.view(-1))\n",
|
||
" optimizer.zero_grad()\n",
|
||
" loss.backward()\n",
|
||
" optimizer.step()\n",
|
||
" total_loss += loss.item()\n",
|
||
" print(f\"Fine-tune Epoch {epoch+1}/{epochs}, Loss: {total_loss / len(dataloader):.4f}\")"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "d1698def",
|
||
"metadata": {},
|
||
"source": []
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 32,
|
||
"id": "71bb6b24",
|
||
"metadata": {},
|
||
"outputs": [
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"Fine-tune Epoch 1/10, Loss: 4.6839\n",
|
||
"Fine-tune Epoch 2/10, Loss: 2.7124\n",
|
||
"Fine-tune Epoch 3/10, Loss: 2.0318\n",
|
||
"Fine-tune Epoch 4/10, Loss: 1.6738\n",
|
||
"Fine-tune Epoch 5/10, Loss: 1.4043\n",
|
||
"Fine-tune Epoch 6/10, Loss: 1.1781\n",
|
||
"Fine-tune Epoch 7/10, Loss: 1.0102\n",
|
||
"Fine-tune Epoch 8/10, Loss: 0.8826\n",
|
||
"Fine-tune Epoch 9/10, Loss: 0.7884\n",
|
||
"Fine-tune Epoch 10/10, Loss: 0.7057\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"# Например, мы хотим дообучить модель на стиле коротких технических фраз\n",
|
||
"fine_tune_text = \"\"\"\n",
|
||
"Transformers revolutionize NLP.\n",
|
||
"Deep learning enables self-attention.\n",
|
||
"GPT generates text autoregressively.\n",
|
||
"\"\"\"\n",
|
||
"\n",
|
||
"dataset = GPTDataset(fine_tune_text, bpe, block_size=8)\n",
|
||
"\n",
|
||
"\n",
|
||
"# Запуск дообучения\n",
|
||
"fine_tune_gpt(gpt, dataset, epochs=10, batch_size=4, lr=1e-4)"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"id": "d5ff63e9",
|
||
"metadata": {},
|
||
"source": [
|
||
"## 📝 6. Генерация текста после обучения"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 33,
|
||
"id": "ccb9621a",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": [
|
||
"def generate_text(model, bpe, prompt: str, max_new_tokens=20, device='cpu'):\n",
|
||
" model.eval()\n",
|
||
" ids = torch.tensor([bpe.encode(prompt)], dtype=torch.long).to(device)\n",
|
||
" out = model.generate(ids, max_new_tokens=max_new_tokens, do_sample=True)\n",
|
||
" text = bpe.decode(out[0].tolist())\n",
|
||
" return text"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": 34,
|
||
"id": "f1b82472",
|
||
"metadata": {},
|
||
"outputs": [
|
||
{
|
||
"name": "stdout",
|
||
"output_type": "stream",
|
||
"text": [
|
||
"Deep learning enaten. tns st GP. N\n"
|
||
]
|
||
}
|
||
],
|
||
"source": [
|
||
"print(generate_text(gpt, bpe, \"Deep learning\", max_new_tokens=20))"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "code",
|
||
"execution_count": null,
|
||
"id": "eb376510",
|
||
"metadata": {},
|
||
"outputs": [],
|
||
"source": []
|
||
}
|
||
],
|
||
"metadata": {
|
||
"kernelspec": {
|
||
"display_name": ".venv",
|
||
"language": "python",
|
||
"name": "python3"
|
||
},
|
||
"language_info": {
|
||
"codemirror_mode": {
|
||
"name": "ipython",
|
||
"version": 3
|
||
},
|
||
"file_extension": ".py",
|
||
"mimetype": "text/x-python",
|
||
"name": "python",
|
||
"nbconvert_exporter": "python",
|
||
"pygments_lexer": "ipython3",
|
||
"version": "3.10.9"
|
||
}
|
||
},
|
||
"nbformat": 4,
|
||
"nbformat_minor": 5
|
||
}
|